Assemblyline Blog Entry #9
 Photo by Priscilla Du Preez on Unsplash
Photo by Priscilla Du Preez on UnsplashIn the previous article, “The Great OneNote Scramble of 2023”, we discussed how a OneNote malware campaign last year provided several opportunities for the Canadian Centre for Cyber Security to react defensively by improving Assemblyline, whether that is with new services, heuristics, signatures, or identification rules.
Assemblyline is a relatively mature open-source project (v3 released on GitHub in 2017, and v4 in 2020). Starting with a few developers, the Assemblyline team has grown to 10 or so people at the CCCS working on improving it on any given weekday. That being said, our development is driven by our clients at the Government of Canada and critical infrastructure partners as well as active members in the open-source community (join our Discord!).
Other than Assemblyline, several other open-source malware analysis tools are popular in the cyber security community, which is great! I wanted to find what Assemblyline could learn from these tools to improve the Government of Canada’s defences. One of my cyber analyst colleagues and I spent two weeks looking at these tools to find anything worth integrating into Assemblyline, and this article will discuss those findings.
How did we choose the tools to be compared?
A combination of word-of-mouth from our Discord community and conferences, and the number of GitHub stars associated with the project. Although this process is largely subjective, it elicited very positive results, which will be discussed below. If you are aware of any projects that were missed and deserve to be investigated, please let us know!
What tools were compared?
<a href="https://medium.com/media/aa56ab5f2b6a7c980829c633e0e87b53/href">https://medium.com/media/aa56ab5f2b6a7c980829c633e0e87b53/href</a>If you are the maintainer or are a fan of one of these tools and believe that something is incorrect or should be included, please reach out!
What was the goal?
The goal was to improve Assemblyline’s file analysis capabilities, including:
- file types analyzed
- malicious/suspicious indicators raised
- integration with other open source tools
- identifying possible system improvements not originally defined
We did not compare file throughput, the prettiest user interface, most integrations with other systems, or how the tool was designed to be used.
After two weeks of digging, my cyber analyst colleague and I found a series of gaps. I’ve separated them into two sections: “Lessons learned and addressed”, and “Lessons learned that we want to address”.
Lessons learned and addressed
Improvements to file type identification
Scripts
Looking at the Karton project, we found that there were some strings in the Classifier service being used for the identification of scripts — a notoriously finicky problem as malicious actors use more sophisticated obfuscation techniques. Karton had strings for Visual Basic Scripts, JavaScript, and PowerShell, which are file types of high interest to Assemblyline:
 Visual Basic Script strings used by Karton’s Classifier service
Visual Basic Script strings used by Karton’s Classifier service JavaScript strings used by Karton’s Classifier service
JavaScript strings used by Karton’s Classifier service PowerShell strings used by Karton’s Classifier service
PowerShell strings used by Karton’s Classifier serviceIn Assemblyline, we use a series of factors when identifying files, but for scripts, it usually comes down to custom YARA signatures. We have YARA rules for these three file types (JavaScript, Visual Basic Script, and PowerShell). From Karton’s Classifier, we added the high-confidence strings that we were missing to the relevant YARA signature to improve our script identification.
More Scripts!
Similar to the script identification strings in Karton’s Classifier, we also found strings in CAPE’s SFlock2 used for our three favourite script types:
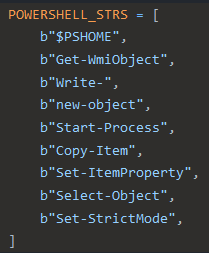 PowerShell strings used by CAPE’s SFlock2 tool
PowerShell strings used by CAPE’s SFlock2 tool JavaScript strings used by CAPE’s SFlock2 tool
JavaScript strings used by CAPE’s SFlock2 tool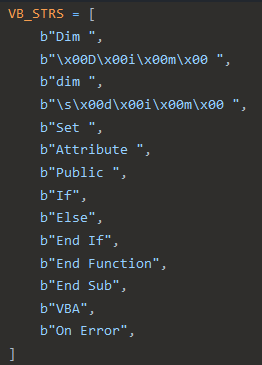 Visual Basic Script strings used by CAPE’s SFlock2 tool
Visual Basic Script strings used by CAPE’s SFlock2 toolWe identified the missing strings that should be in our YARA rules and added them.
This exercise also provided validation to our current YARA rule strings, by reinforcing those that were found in Karton’s Classifier and CAPE’s SFlock2.
AutoIt
Recently, our team has noticed an increase in malware activity that leverages AutoIt scripts. Although we have already done some work to detect these types of files and run them in our CAPE service, we found some additional strings in a YARA file used by Karton’s AutoIt-Ripper service that we were able to integrate into our own YARA signature for AutoIt files:
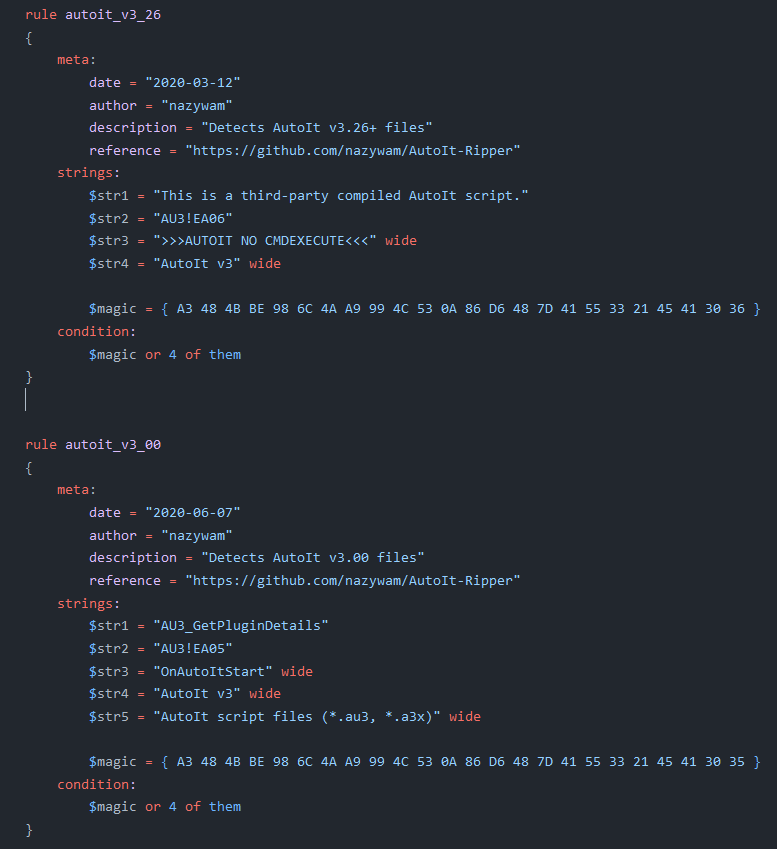 Useful AutoIt identification in Karton’s AutoIt-Ripper service
Useful AutoIt identification in Karton’s AutoIt-Ripper serviceTrusted MIMEs
CAPE uses a forked SFlock2 project from the original SFlock project from Hatching for file identification and archive extraction. We found that some high-confidence MIME types were being used to identify 7-Zip and BZip2 archives, as well as JAR files:
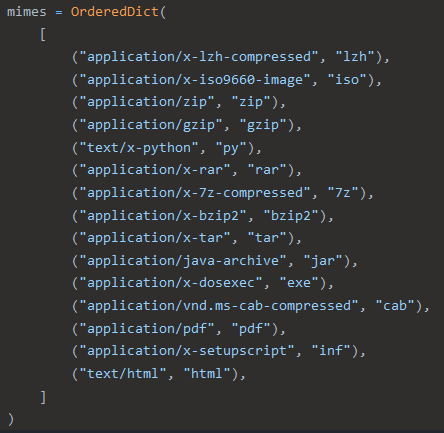 High-confidence MIMEs in CAPE’s SFlock2 tool
High-confidence MIMEs in CAPE’s SFlock2 toolIn Assemblyline’s identification mechanism, we consider the MIME types of a file when trying to determine its type, and we also utilize a concept of “trusted MIME” types which means that if a file has a given MIME type and we are confident that this MIME has an exceptionally high true-positive rate when identifying files, we will map this MIME type to the Assemblyline file type to provide faster and more accurate identification. Some of the high-confidence MIMEs seen in SFlock2 were not in Assemblyline’s “trusted MIME” list, so after verifying that files with these MIMEs were identified correctly at an exceptionally high rate, we added these MIME types to the list of “trusted MIMEs”.
The pull request that included these changes is found here: https://github.com/CybercentreCanada/assemblyline-base/pull/1477
Improvements to JsJaws Signature Set
JsJaws is Assemblyline’s JavaScript analysis service and has a signature set that runs on both file contents and emulator output. When looking through the Qu1ckSc0pe project, we found some interesting strings used by the DocumentAnalyzer service that could be added to JsJaws as signatures:
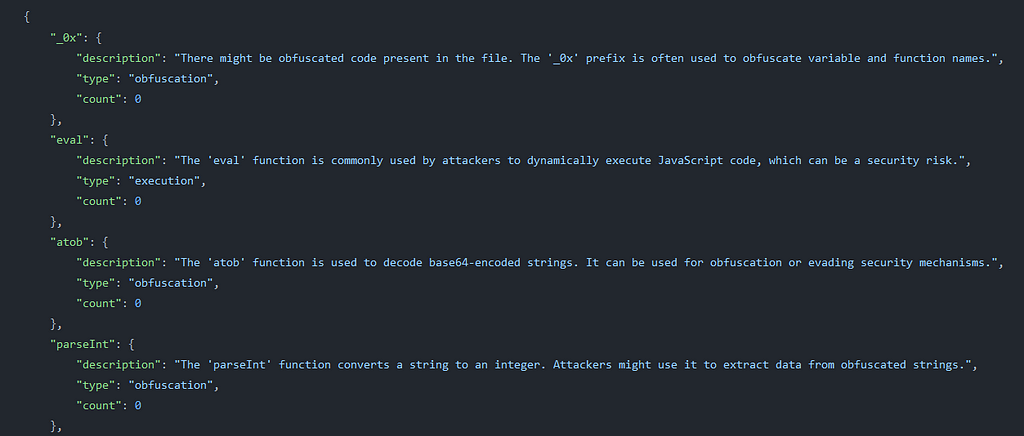 Malicious HTML codes used in Qu1ckSc0pe’s DocumentAnalyzer service
Malicious HTML codes used in Qu1ckSc0pe’s DocumentAnalyzer serviceThis JSON of malicious HTML codes also overlaps with some of the current signatures in JsJaws, which validates their inclusion in the signature set.
The pull request that includes these changes is found here: https://github.com/CybercentreCanada/assemblyline-service-jsjaws/pull/647
Extract Hexadecimal Blobs via Multidecoder
Assemblyline uses the Python library Multidecoder for extracting IOCs from file contents. The Deobfuscripter service uses Multidecoder’s find_FromBase64String method to extract Base64 blobs from PowerShell scripts.
The Qu1ckSc0pe project supports PowerShell’s FromBase64String method as well as FromHexString for blob extraction in their PowerShellAnalyzer service:
 Regular expressions from Qu1ckSc0pe’s PowerShellAnalyzer service
Regular expressions from Qu1ckSc0pe’s PowerShellAnalyzer serviceRecognizing this gap, we added support for FromHexStrings to Multidecoder, so that FrankenStrings will also be able to use this functionality.
Behaviour Detection in PS1Profiler
Assemblyline uses the Overpower service for PowerShell analysis. This service uses a maintained version of Palo Alto Network Unit 42’s PowerShellProfiler tool for detecting suspicious behaviours via string matching in a PowerShell script.
When digging into the Qu1ckSc0pe project, we saw that the PowerShellAnalyzer service also detects behaviours similar to what PowerShellProfiler does, and stores them in this file. After inspection, it was determined that it was worth integrating some of the missing strings into the Overpower service.
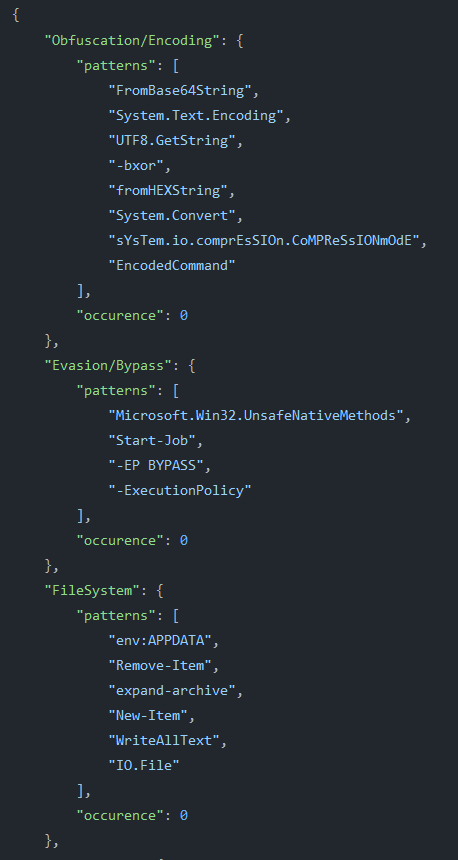 Behaviour detection strings used by Qu1ckSc0pe’s PowerShellAnalyzer service
Behaviour detection strings used by Qu1ckSc0pe’s PowerShellAnalyzer serviceWe also discovered some regular expressions in Qu1ckSc0pe‘s PowerShellAnalyzer service that would be useful for detecting execution, so we added the key strings into PowerShellProfiler.
The pull request that includes these changes can be found here: https://github.com/CybercentreCanada/assemblyline-service-overpower/pull/194
Heuristics for PE and ELF services
Assemblyline’s PE service and ELF service both use the LIEF project to parse executable files to extract metadata about the file. There are a series of heuristics that the services have which give it the ability to score on suspicious attributes of the file, but there is a lot of metadata that is extracted and it’s always nice to correlate more attributes with suspiciousness.
When we were looking at the Qu1ckSc0pe project, we came across its WinAnalyzer service which contained an interesting heuristic that detected if there were less than twenty total imported and exported functions. We were unsure of how malicious this was and added it as an unscored result section in the PE service. Since we scan thousands of benign PE files a day, we are able to generate metrics about the result section’s true positive rate.
When investigating the Viper project, we saw in their PE and LIEF services there were many “warning” logs when there were none of a certain attribute.
 Example of a Viper warning log
Example of a Viper warning logWe were also unsure if these warnings would be worth scoring so we added result sections to both the PE service and the ELF service for most of the warnings to run in production for a month to generate some statistics to guide our future decisions about them.
In our initial assessment of PE files, we found that if no resources or languages were found in the parsed metadata, there was a reasonable chance that the file was suspicious, so we added those features as heuristics so that we could score them. In the ELF files, we found that a lack of dynamic library or entry was also suspicious, so those made it into heuristics as well.
This is the initial pull request for the PE service that contained the heuristics and result sections inspired by Qu1ckSc0pe and Viper: https://github.com/CybercentreCanada/assemblyline-service-pe/pull/54.
The initial pull request for the ELF service that contained the heuristics and result sections inspired by Viper: https://github.com/CybercentreCanada/assemblyline-service-elf/pull/29
During this dig, we found that several of our current heuristics were also cause for suspicion in these other tools that validated our inclusion of them.
After these result sections ran in production for a while, we were able to easily query them in the data to determine their true positive rate:
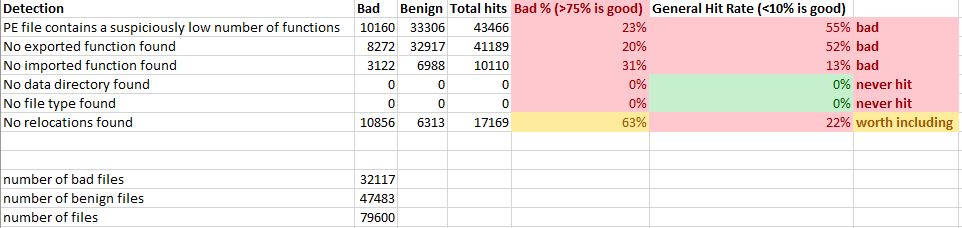 PE’s new result section metrics
PE’s new result section metrics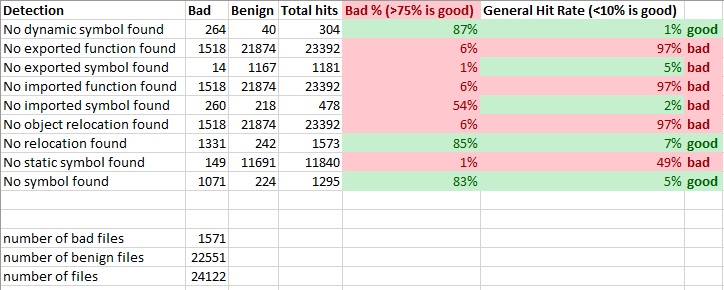 ELF’s new result section metrics
ELF’s new result section metricsArmed with these metrics, I removed result sections that didn’t have value or converted useful ones to heuristics such that we could score them for the PE service and the ELF service. In the end, only four of these features had a true positive rate that was high enough to be worth including, but that is still an improvement in detection for executable files on both Windows and Linux operating systems, so this work was worth our time!
HTML Script Entropies
Assemblyline’s JsJaws service can analyze script elements within HTML documents. Something interesting that we found in Viper’s HtmlParser service was the calculation of entropy for script elements. We are already performing entropy calculations for every file in Assemblyline via the Characterize service and the entropy of specific sections of executable files in the PE service and ELF service. This concept has value for these file types in detecting packing or obfuscation, so by introducing this analysis vector to HTML files there is potential to be able to flag high script entropies in the future as suspicious!
 Example of script entropy visualization for ec42b246dee5e5f1e7277d57b214a7ba10b5b9158017fd4e7fe684b4b057d6fd
Example of script entropy visualization for ec42b246dee5e5f1e7277d57b214a7ba10b5b9158017fd4e7fe684b4b057d6fdThe pull request to the JsJaws service that implements this change is here. We are currently not sure what threshold should be used to determine suspiciousness for benign HTML scripts, so this is another decision that will be made at a later date — stay tuned!
Lessons learned that we want to address
Below are interesting ideas that we discovered when looking at other tools, that we have not yet implemented.
Investigate XOR Capabilities
We found plenty of XOR capabilities in the Qu1ckSc0pe, Stoq, and Viper projects.
Assemblyline uses a modified version of Philippe Lagadec’s bbcrack in the Frankenstrings service to brute-force common obfuscation techniques, such as XOR.
The Viper project has a Strings service which gives the user the option of providing a XOR key before searching for particular strings. Assemblyline does not support passing a XOR key in a service’s submission parameters, and this is something that we will be exploring in the future.
Stoq’s YARA service extracts XOR keys using a plaintext value stored in the YARA rule metadata which is then passed to the XorDecode service for payload decoding. Assemblyline’s YARA service does not have this functionality. A contributor from the community added some code to our YARA repo and there are some XOR key capabilities commented out, so this is something that we can look into going forward.
StringSifter Capability
 Mandiant’s StringSifter, from https://github.com/mandiant/stringsifter/raw/master/misc/stringsifter-flat-dark.png
Mandiant’s StringSifter, from https://github.com/mandiant/stringsifter/raw/master/misc/stringsifter-flat-dark.pngAssemblyline’s FLOSS service is great at extracting strings via Mandiant’s FLOSS tool. What it isn’t good at is ranking these strings according to their likelihood of being used in malware, and scoring service results is the main method that Assemblyline uses to raise alerts to analysts. During this dig, we found that a couple of tools were giving the FLOSS output “teeth” by running the output through a tool called StringSifter. From the project README: “[StringSifter is] a machine learning tool that automatically ranks strings based on their relevance for malware analysis”.
FAME was using StringSifter in its StringSifter service and IntelOwl was using StringSifter in its FLOSS service.
This is something that we want to integrate into our analysis results because sometimes static analysis services such as FLOSS are our last hope for detecting novel malicious PE files. The use of StringSifter could also expand on the value of the Multidecoder library, and weaponize our FrankenStrings service.
Frida Integration
 Frida, by the FRIDA Project from https://frida.re/img/logotype.svg
Frida, by the FRIDA Project from https://frida.re/img/logotype.svgFrida is a project that we’ve had our eye on for a couple of years now. It is touted as a “dynamic instrumentation toolkit” and we saw its presence in FAME and Qu1ckSc0pe during our investigation. These two projects use Frida for script instrumentation in FAME’s CutTheCrap service and in Qu1ckSc0pe’s Windows Dynamic Analyzer service. The main question here is why are other malware analysis tools using Frida for script instrumentation when dynamic analysis tools exist like CAPE or emulation tools like Box-js, Box-ps, and ViperMonkey? Does it provide any value to malware analysis for scripts that we do not have in Assemblyline’s JsJaws, Overpower, and ViperMonkey services? That is to be determined.
DocumentPreview Default Value
Assemblyline has the DocumentPreview service which renders a document file. It also applies optical character recognition (OCR) to find malicious indicators in a file if they exist. When rendering files, we default to only rendering the first page, because at some point it was determined that the average phishing document length was one page. We found that the FAME project’s Document Preview service uses a default of 5 pages when rendering a document. A default should be applied because OCR is time and resource-intensive and could seriously hinder throughput in Assemblyline if we did not have a low default number of pages analyzed. It is worth our time to investigate what the average number of pages in a phishing document is, and if malicious indicators are found in pages following the initial page.
Authenticate DKIM, DMARC, and SPF headers in EmlParser
Assemblyline has an email analysis service called EmlParser which performs header parsing and analysis. Upon diving into FAME’s Email Headers service, we found that it had special parsing and validation for DMARC, DKIM, and SPF headers which we do not have in the EmlParser service. So, this is an opportunity for developing a heuristic to detect when these headers are invalid.
PeePDF Improvements
Assemblyline’s PeePDF service is one of our PDF-tailored services. It is originally based on the PeePDF project, which has not been touched in 8 years. We are using a “fork” of PeePDF, but it also has not been updated as of late. The CAPE and FAME projects both have PeePDF services. FAME’s PeePDF service has more detailed usages of PeePDF than our Assemblyline service has, so this is an opportunity for improvement! CAPE’s PeePDF service uses a custom fork of PeePDF which is a fork from Hatching’s PeePDF fork. This is all to say that there is the potential that there are some features from both FAME and CAPE that we are missing in our PeePDF service.
Update and improve FLOSS
 Mandiant’s FLOSS, from https://github.com/mandiant/flare-floss/raw/master/resources/floss-logo.png
Mandiant’s FLOSS, from https://github.com/mandiant/flare-floss/raw/master/resources/floss-logo.pngAssemblyline’s FLOSS service uses a pinned version of the FLOSS binary, currently at v1.7.0. The actual FLOSS project is at version 2.3.0. We are aware of this and so are our clients. Outside of updating the FLOSS binary and addressing the breaking changes that it will cause, CAPE has an officially supported FLOSS service, and FAME has a community FLOSS service which both have more detailed usages of the FLOSS tool than in Assemblyline’s service. It is worth duplicating CAPE’s usage of the Python library for FLOSS to take advantage of the latest version plus the helper methods that are provided with that module.
Extract API keys & Telegram Tokens
Assemblyline’s FrankenStrings service extracts interesting strings that we have tags for, such as domains and URLs. The Qu1ckSc0pe project uses regular expressions in its Domain Catcher service to extract API keys and Telegram tokens. Assemblyline’s only detection for Telegram usage is found in the JsJaws service as a signature that looks for when JavaScript makes outgoing requests to Telegram’s API server. We can integrate these regular expressions into FrankenStrings or URLCreator and then create a new tag type for each interesting string so that we can pivot on the data.
Spoof Check Heuristic for EmlParser
The Viper project has an EmailParse service that performs an interesting check for spoofed emails via the headers that Assemblyline’s EmlParser service could implement to improve detection for email spoofing. This is an opportunity to introduce a new heuristic and score an email as suspicious using the headers only, which is always an exciting prospect!
Otto Interpreter for JavaScript emulation
The biggest takeaway from investigating the Velociraptor project was that it uses the Otto project as a JavaScript interpreter. It is worth investigating how it runs JavaScript, what value it brings if any, and possibly integration into Assemblyline’s JsJaws service.
So, there you have it! Those are the lessons that Assemblyline can learn from other popular open source malware analysis tools. It should be said that we at the CCCS believe that cyber security is a team effort, and having so many great projects to dig through to learn and improve the Government of Canada’s defences as well as the public, given that Assemblyline is open-source, is something that we do not take for granted and are very appreciative of.
Thanks for reading
Sample Hashes
Script Entropy
ec42b246dee5e5f1e7277d57b214a7ba10b5b9158017fd4e7fe684b4b057d6fd
All images unless otherwise noted are by the author.
Article Link: What Can Assemblyline Learn From Other Malware Analysis Projects? | by Kevin Hardy-Cooper, P.Eng | Mar, 2024 | Medium