 Image generated using DALL-E
Image generated using DALL-E
Large Language Models (LLM) have taken the internet by storm in the last few months. The recent launch of PaLM 2 by Google and GPT 4 by OpenAI has captured the imagination of enterprises. There are many potential use cases being ideated across the domains. Multilingual customer support, code generation, content creation and advanced chatbots are some examples. These use cases require LLMs to respond based on the custom data of the business.
How businesses can solve these use cases with the help of LLM on their custom data? After some research and dabbling with LLMs, I found three ways of doing so.
- Prompt Engineering
- Embeddings
- Fine Tuning
Prompt Engineering
What is a prompt?
Prompt is an input to the LLM. For example, in the below image the prompt is-
“Recommend me 5 fiction novels similar to the Bourne Series. Write only the title and author name.”
 Prompt asking Chat GPT to recommend novels
Prompt asking Chat GPT to recommend novelsCustom data in prompt
Injecting your data or context in a prompt is the easiest way of using custom data with LLM. For example, in the below image, the prompt has sales data for Q1 2023 and Q2 2023 of a company. The question to the LLM is to return the percentage change in the sales.
 Adding data in Chat GPT prompt
Adding data in Chat GPT promptWhen to use prompt engineering?
There are many applications of prompt engineering. In fact, prompt engineering is considered a niche skill that will be coveted in the future.
Passing the data in prompt works well in the scenarios where you want to provide instructions to the LLM, perform search operation or get answer to the queries from a smaller data set. But, it is not the best way to work with a large set of documents or web pages as input to LLM due to limitation in the size of prompt and cost associated with passing large text to the LLM.
Embeddings
What are embeddings?
Embeddings are a way of representing information, whether it is text, image, or audio, into a numerical form. Imagine that you want to group apples, bananas and oranges based on similarity. This can be done using “embeddings”.
An embedding will turn each type of fruit into a numerical form (vector). Consider the below example,
Apples -> (3, 8, 7)
Bananas -> (8, 1, 3)
Oranges -> (4, 7, 6)
These embeddings for apples and oranges are closer to each other. We can say that apples and oranges are more alike.
Using embeddings
Below diagram explains conceptually how these embeddings are used to retrieve information from your documents using LLM. First, the documents are passed through a model that creates small chunks of it and then creates embedding of those chunks. These embeddings are then stored in a vector database. When a user wants to query the LLM, the embeddings are retrieved from the vector store and passed to the LLM. LLM generates the response from the custom data using the embeddings.
This post is a working example for generating embeddings for documents and passing these embeddings to Chat GPT.
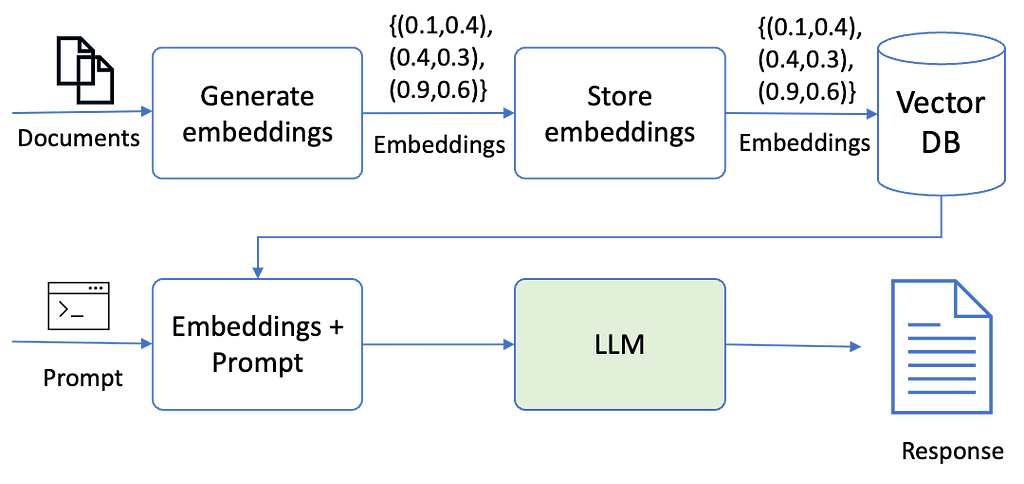 Document embedding with LLM
Document embedding with LLMWhen to use embeddings?
Embeddings work well when a large corpus of documents or web pages needs to be passed to an LLM. For example, this method would work well when a chatbot is built to provide a response from a set of policy documents to the user.
Fine Tuning
What is fine tuning?
Fine tuning is a way of teaching the model how to process the input query and how to represent the response. For example, LLM can be fine-tuned by providing data about the customer reviews and corresponding sentiment.
Prompt: I really liked this product. I highly recommend it.
Completion: Positive
Prompt: I found the delivery experience below average.
Completion: Negative
Here “prompt” is an example of an input and “completion” is an example of the corresponding output.
Now, if you provide another review as a prompt to the LLM, then it will respond with the corresponding sentiment.
 Sentiment analysis using fine tuned Chat GPT
Sentiment analysis using fine tuned Chat GPTAnother example is
Prompt: Q1 2023, $10 million, +5%, good, positive
Completion: The revenue for Q1 2023 was $10 million, which is 5% higher than revenue in the previous quarter. The sentiment on the streets is good for this company and there is a positive outlook for the business.
Prompt: Q2 2023, $20 million, -2%, neutral, negative
Completion: The revenue for Q2 2023 was $20 million, which is 2% lower than revenue in the previous quarter. The sentiment on the streets is neutral for this company and there is a negative outlook for the business.
You can provide many examples to fine tune the model and then ask questions to the model.
Fine tuning is available for limited base models — davinci, curie, babbage, and ada.
When to use fine tuning?
Fine tuning is typically used to tune the LLM for a specific task and get a response within that scope. The task can be email categorisation, sentiment analysis, entity extraction, generating product description based on the specs, etc.
This post barely scratched the surface of these techniques. There are many more nuances to each of these.
I am learning with you and will keep sharing my learnings about this exciting space. Do follow!
Training Large Language Model (LLM) on your data was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Training Large Language Model (LLM) on your data | by Mohit Soni | Walmart Global Tech Blog | Medium