
“It’s not who I am underneath, but what I do that defines me.” — Bruce Wayne
These words might be coming from a fictional character but isn’t it what artificial intelligence is trying to convey these days. Wanna know something interesting, the above image is also generated by AI.
Natural Language Processing (NLP) and language models play a pivotal role in revolutionizing retail and Ecommerce. These technologies enable personalised product recommendations, chatbots for customer service, sentiment analysis of customer reviews, and efficient search algorithms. By analyzing vast amounts of text data, NLP helps retailers understand customer preferences, predict trends, and optimize pricing strategies. Language models enhance customer interactions by providing tailored responses and improving user experience. Moreover, NLP aids in fraud detection, inventory management, and supply chain optimization. In essence, leveraging NLP and language models empowers retailers to enhance customer satisfaction, streamline operations, and drive revenue growth in the competitive ecommerce landscape.
 AI Hierarchy
AI HierarchyThe Dawn
Generative AI is a subset of traditional machine learning and the machine learning models that underpin generative AI have learned these abilities by finding statistical patterns in massive datasets of content that was originally generated by humans. Generative AI models can generate a wide range of outputs, such as text, images, music, and even voice. Large language models, a type of generative AI, are particularly noteworthy. They are trained on vast amounts of text data and can generate human-like text based on the input they receive.
Natural Language Processing (NLP) has evolved significantly since its inception. Traditional models like TF-IDF (Term Frequency-Inverse Document Frequency) and Markov Chains were the initial models used in NLP. The TF-IDF model was used to measure the importance of a term within a document and a collection of documents, but it lacked the ability to understand the context and semantics of the phrases. Markov Chains model was used to predict the probability of each next word in a sentence based on the previous word, however, it only considered immediate predecessors, thus lacking long-term dependency understanding.
RNNs while powerful for their time, were limited by the amount of compute and memory needed to perform well at generative tasks. With just one previous word seen by the model, the prediction can’t be very good. As we scale the RNN implementation to be able to see more of the preceding words in the text, we have to significantly scale the resources that the model uses. To successfully predict the next word, models need to see more than just the previous few words. Models needs to have an understanding of the whole sentence or even the whole document. The problem here is that language is complex. In many languages, one word can have multiple meanings.
 RNN Block
RNN BlockThe problem was addressed by the introduction of Long Short-Term Memory (LSTM) networks. LSTMs, a special kind of RNN, are capable of learning long-term dependencies and remembering information for extended periods, which is particularly beneficial in NLP for understanding the context over a sequence of words. This has greatly improved the performance of NLP tasks, resulting in more human-like language understanding.
Eureka!!!
Transformer architecture came into the picture with “Attention is all you need” which disrupted the generative setup at that time with significant performance improvement over RNN. Unlike sequential models such as Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTMs), Transformers process all data points in parallel, making them more efficient for handling large text data. They also address the problem of long-term dependencies in a sequence by directly relating distant data points.
Transformers are the foundation of many state-of-the-art models in NLP, such as BERT, GPT-4, and T5, driving advancements in machine translation, text summarization, and other language tasks. Despite their complexity, their ability to handle context and maintain scalability makes them a vital tool in AI.
Transformers have the capability of creating a semantic understanding by looking terms around the focus token. Transformers use a technique called self-attention in which attention-weights are calculated from one term every other term in the phrase. Attention weights helps in focussing on tokens which needs more concentration and importance in reflecting the actual meaning of the phrase in language.
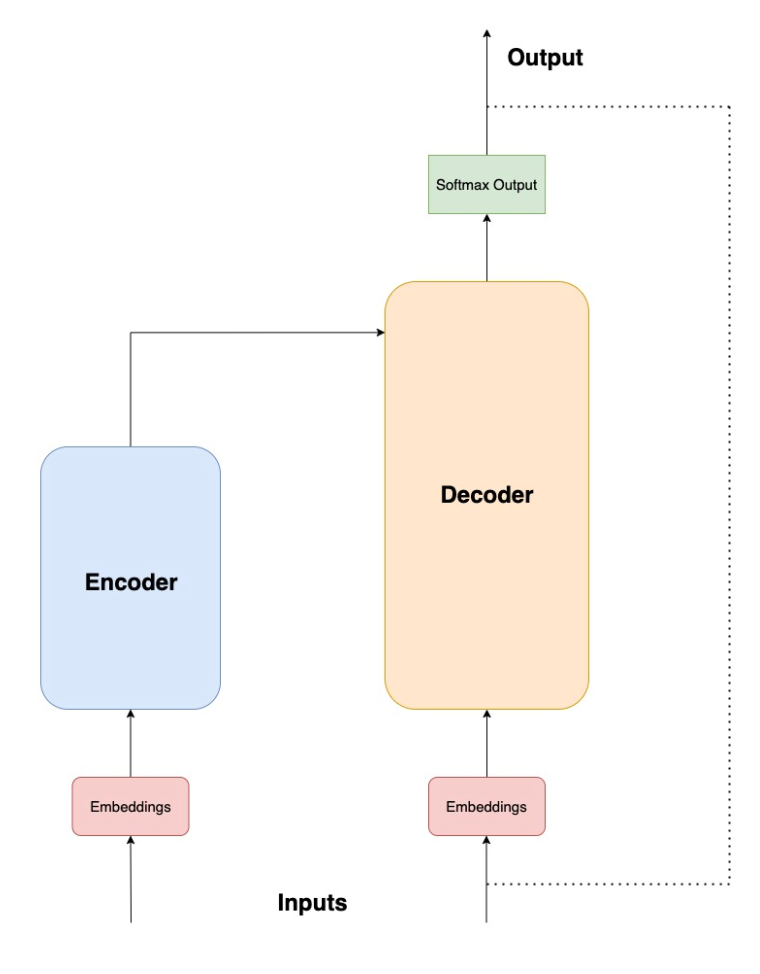 Transformer Schematic Diagram
Transformer Schematic DiagramThere are 3 major components in transformer architecture: Tokenizer, Encoder and Decoder.
A sentence or phrase is passed through the tokenizer to transform it into a sequence of tokens or numeric values. Tokenization is the process in which words are converted into numerical values for performing mathematical operations. Each token is then passed through the embedding layer to create a fixed length vector representation. These embeddings are understood to represent the context of each token in high dimensional space. Embeddings generated for tokens are pushed into Encoder and Decoder. Transformer architecture scales well because of its capability to process data in parallel. To retain the relative position of token the phrase, positional encodings are also pushed into the encoder and decoder unit along with the token embeddings. These units contain the self-attention units which computes the attention weights. These attention-weights are a representation of significance of a term with respect to all other terms in the phrase. Additionally, both encoder and decoder employ multi-head attention mechanism. The approach utilises multiple self-attentions units to find attention weights from various perspectives which helps the model to explore multiple semantic avenues accounting even for linguistic ambiguity. Output from the attention layers is pushed to fully connected feed forward network. Output from feed forward network of the decoder unit are the probability scores of the next token in sequence. Scores corresponding to each token in the model tokenizer dictionary are yielded. The scores are further processed by the softmax layer to determine the next predicted token.
 Tokenize (Source)
Tokenize (Source)During the inference phase, decoder uses the output from self-attention and feed forward network of the encoder to get the semantic and contextual knowledge of the input sequence. It generates the complete sequence in a loop until input tokens are supplied or the break condition is reached.
The Cousins
There are 2 variations of the original transformer architecture which are used for numerous natural language tasks. These variations are trained with varied training objectives.
 Auto Encoding Model Architecture
Auto Encoding Model ArchitectureEncoder only architecture models also known as Autoencoding models contain only the encoder unit from the original transformer architecture and trained using masked language modelling technique. Such models have Bidirectional context for a token and not limited just to the pre- occurring tokens in the sequence. These models are favourable for tasks like text categorisation and entity recognition. Examples: BERT, ALBERTA
 Source
SourceDecoder only architecture models also known as Autoregressive models contain only the decoder unit from the original transformer architecture and trained using causal language modelling. Such models only have visibility of the previous set of tokens and are primarily focussed on text generation tasks. These models tries to establish statistical distribution of the tokens in the language dictionary used to train the model. Due to harder training constraints of only unidirectional lookup, these models can perform varied tasks and carry out zero-shot learning tasks effectively. Examples: GPT, Llama
Unsettling Peace
Large language models have been trained on trillions of tokens over many weeks and months, and with large amounts of compute power. These foundation models, as we call them, with billions of parameters, exhibit emergent properties beyond language alone, and researchers are unlocking their ability to break down complex tasks, reason, and problem solve. The way we interact with language models is quite different than other machine learning and programming paradigms. In those cases, we write computer code with formalized syntax to interact with libraries and APIs. In contrast, large language models are able to take natural language or human written instructions and perform tasks much as a human would.
 LLM Interaction
LLM InteractionInteraction with traditional machine learning and deep learning systems is through programming languages and computer code following a pre-defined syntax. Contrastingly, interaction with LLMs is using Natural language and more particularly in form of instructions for accomplishing certain tasks.
In inference or prediction phase, the complete input to the LLM is known as Prompt. The prompt comprises of user question and optionally the context with respective to which the question needs to be answered. Including context within the prompt for improved model performance and obtaining desirable output from the model is called In-context learning. It is important to note that all LLMs have a limit on the number of words or tokens that can be ingested which is referred to as context window. Output from the model is “Completion” which is the process of running inference from the LLM based on given prompt which is composed of both the generated text and original prompt. Completion is structured in such a way as LLM works on next word generation wherein if the prompt contains a question, LLM generated the corresponding answer.
Size matters (sometimes)
Large language models implicitly gain a wide range of knowledge and subjective understanding while being trained with humongous amount of data. As size of the models increase, their width of information and propensity of understanding also improves. The large number of parameters learned during the training process allows to perform complex tasks and process information even without specialised training for the task. Interestingly, smaller models when trained or fine-tuned on specialised tasks tend to perform well.
Supplying models with in-depth context and examples to produce improved output for the task is called in-context learning. LLMs get their instruction as prompt about the task to be performed. Larger models acquire knowledge on wide range of topics during pre-training phase and showcase superior performance on zero-short inference. Comparatively, smaller models would require more elaborate description of the task and examples might help in achieving the desired goals. Process of adding one example in prompt is called one-shot inference and adding two or more than two examples is called few shot learning. An important point to note is length of prompt that can be handled is limited by the model’s context window.
 In-context Learning
In-context LearningExtending the capabilities of an LLM may include supplementing with external data sources which might include APIs, Database etc. We will talk about the topic in detail in subsequent articles.
Summing up
NLP has come a long way since it’s inception and with newer capabilities in place, it is easier to solve the most challenging problems of the industry.
The field of GenerativeAI is evolving by the hour and it becomes increasingly imperative for engineers and data scientists to arm themselves up with the most novel tech enabling the future. Google, Meta, Microsoft along with Mistral AI and HuggingFace have led the revolution in open source space to put these gigantic models and innovative tools in the hands of every engineer to experiment. Democratising AI is the need of the hour.
References & credits:
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017)
Dong, Qingxiu, et al. “A survey on in-context learning.” arXiv preprint arXiv:2301.00234 (2022)
Textual Titans: A Large Language Model Odyssey was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: https://medium.com/walmartglobaltech/textual-titans-a-large-language-model-odyssey-d36eab1e2743?source=rss----905ea2b3d4d1---4