In the last article, I mentioned about the aspects to keep in mind when developing a Data Science project. In this article, we will contrast the process of building AI based systems with that of traditional software systems, and the associated pitfalls[1]. Later, we outline an architecture to mitigate the pitfalls.
Pitfalls of the current Process:
One of the major differences of the ML systems from traditional software systems is the crucial dependence of the ML systems on data. Idea of using training data when building an ML system is to capture distribution of data empirically. If the input data distribution changes, ML models will under-perform.
The key here is to maintain versioning both for models and data. Ideally an ML based systems have a component to manage training data along with versioning. Similarly, it should have a model management system with version management.
In a rush to improve metrics of ML model, often all the components/fields of data are used. However, this leads to a system which is not amenable to evolution. For example, if one is using feature of a data element that may not be present in future or the syntax/format of the data gets modified, the model will either fail or perform poor because of unavailability of the feature. When we rush to use all the fields of data, there is a high changes of model inputs being correlated. Without understanding the causality of these inputs, model may turn out to be a model on effect variables (as there is indeterminacy problem when we use correlated feature). This is least desirable as effect features may be causally dependent on other variables.
Hence, it is mandatory to have proper data collection and feature engineering components. Sometimes domain knowledge is the key to take a decision on the right kind of data fields to be used in the model. Irrespective of this, feature engineering should have a pre-processing component to study correlation of the variables, and causality among the variables. Another orthogonal aspect is choosing the right set of data — data that represents the distribution when model is put in use. More often than not, a data-centric approach has higher chance of improved system performance than a model-centric approach.
In software system, sound abstraction philosophy is pursued, and hence interfaces are well-defined. Unlike software systems, in ML based systems, different algorithms to perform the same task have different interfaces. Since problem and data are forced fit to the implemented ML algorithms, the integration/glue components are omni-present. This not only makes the system difficult to understand but also adds difficult of maintenance.
Unfortunately, we have reached a state where it is kind of impossible to start with standards of components and interfaces. To alleviate this situation, the ML developers should write the glue code in an interpretable manner.
When ML system is built many a times we do not have idea of the number of downward clients that may use the service. With time, ML workflow may reach a load that it was not designed for. Even worse, there could be malicious attacks/failure-proneness (e.g. number of socket connections) that results in system shut-down.
Key cure to the above is to bring security aspects like authentication/authorization and service level agreements.
In order to make ML systems adaptive, many a times ML systems are developed to select training data adaptively and to retrain mode dynamically. There is a high chance of selection bias in the training data. Instead of improving the model it will result in deterioration of the model. Here again establishing the need of a data-centric approach rather than a model-centric approach. Yet another pitfall could be when another system depends on the current system for the input, but the design of the two systems are carried out with assumed interface without explicitly validating it.
Solution to the former issues is to use explore-exploit framework. However this may not work with increased state-space dimension. Better approach is to use periodic retraining but not with automated selection of training data.
Significant roadblock to industry-scale ML system is the possibility of huge number of configurations. There are wide choices of pre-processing, more possibilities of ML algorithms. Each algorithm has number of hyper-parameters. Worse, the data sources can be numerous and format of data may change.
ML systems should have a data collection and verification module. The objective is not only to collect the data from various sources, but do an exhaustive check on possibilities of data corruption/unavailability. There should be a system to manage hyperparameter specification both for feature creation and modelling.
ML literature is filled with transfer learning. Here, a model is built initially for a problem A. Later this model is used for another related problem B. Rather than building the model for problem B, model for problem A is trained partially (an example is last layer retraining for deep-net based model). Derived model cannot be optimal for problem B. If training model end-to-end is too expensive, greedy layer-wise pretraining too can yield much better model. Besides, one should understand the tenets for transferability.
With advances in computing, it is possible to build computational-intensive ML models now. However, computation cost is still one of the heavy cost component for corporates. ML systems have often built without taking cognizance of computation cost.
With proper resource management, it is possible to reduce the computation cost of organization. With concepts like auto-scaling of computation platform, pre-emptible compute or distributed computation with increased data-local computation, significant cost-saving is realizable.
Is there a reference architecture for ML based systems that can address the problems mentioned earlier? Given below is a platform architecture with different components that mitigate the pitfalls to a large extent. We will describe functionality of the components that help achieve the objective.
Platform Architecture for ML-based systems:
Architecture Diagram for ML based Systems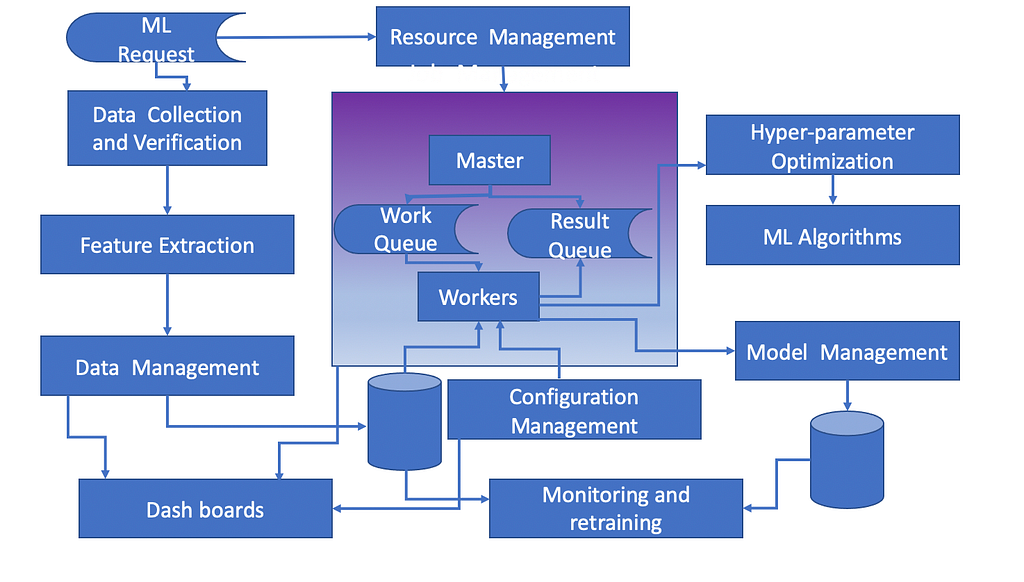
Data collection and verification module is meant to gather data from various data sources. It checks various fields to identify the inputs that are meaningful for the ML model. It also checks about ephemeral data components.
Feature extraction makes meaningful features out of the data. Towards this, the module may leverage different statistical methods of causation and correlation.
Data management module generates train, test and validation data sets. It also has data versioning capability.
Resource Management unit adaptively spawns new jobs. It also releases resources from jobs which are inactive currently (e.g. waiting for other jobs to complete etc.) Master unit is the controller for the resource management. It gets pending tasks done through worker agents. To manage its function effectively, master unit interfaces with workers through work queue and result queue.
Workers perform elementary ML jobs like pre-processing of data, model training. To handle large state space possible of configurations, a configuration management unit is required. It specifies types of pre-processing, various parameters associated with that, set of ML algorithms under consideration and hyper-parameters for them. A worker unit takes a slice of the configuration and runs hyper-parameter optimization while training the model. The configuration management and the hyper-parameter optimization modules are probably the most complex parts of the architecture, where adaptive decisions are taken on tasks to be performed.
Model management keeps information about the model performance at build time, information about models like build time, data used etc. Model versioning is properly maintained.
Dashboards are meant for analysis of data, job statistics, resource usage and even current configuration information.
Finally model monitoring is aimed at generating new data set for evaluation of model performance over time. If there is significant degradation of model performance, it triggers a new training.
At Walmart we have developed an in-house system called Ultron[2]. Ultron has all the components mentioned above.
This is the first of a the series of articles of various aspects of Data Science. In the last two articles, I have attempted to provide a guiding principle before we embark on Data Science projects, contrast Data Science engineering from software engineering and sketch out a model platform architecture for Data Science projects. Stay tuned for more insightful articles on various topics of Data Science.
Acknowledgements:
Special thanks to Sapna Balan, Sreyash Kenkre, Arun Menon, Amlan Roy and Amit Kumar Sharma for their inputs.
References:
- Sculley et al., “Hidden technical debt in Machine learning systems,” NIPS’15: Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 2, Pages 2503–2511.
- S. Narayan et al., “Ultron-AutoML: an open-source, distributed, scalable framework for efficient hyper-parameter optimization,” 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 2020, pp. 1584–1593.
Tackling the Pitfalls of building Data Science Projects was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Tackling the Pitfalls of building Data Science Projects | by Sakib Mondal | Walmart Global Tech Blog | Jun, 2021 | Medium