An anti-pattern is a common response to a recurring problem that is usually ineffective and risks being highly counterproductive.
This is the first post in a series describing Solr anti-patterns to be avoided for better performance and stability of solr clusters.
 Image by David Zydd from Pixabay
Image by David Zydd from PixabayThe most common anti-patterns are:
1. Deep pagination
In Solr, the basic paginated searching is supported using the start and rows parameters, but performance issues can occur in Solr with Deep Paging.
Using very large values for the start or rows parameters can be very inefficient. Deep Pagination, not only requires Solr to compute (and sort) in memory all the matching documents that should be fetched for the current page, but also all of the documents that would have appeared on previous pages.
Solution: Use a cursor query to avoid the limitations of high start and row parameters. Cursor queries are designed and recommended for deep pagination. There are few constraints using cursor queries to be aware of.
2. Explicit commits and optimize
Sending explicit commit requests from client applications should be avoided as it can severely impact the performance of your clusters.
Running an optimize will remove all of the deleted documents from your index and will create a single segment. This operation will create segments much larger than the maximum considered for future merges and you’ll have to perform this operation routinely. This is a very heavy-weight operation that doubles the index size during its execution and basically rebuilds the index again.
Solution: Solr provides IgnoreCommitOptimizeUpdateProcessorFactory, which will ignore all explicit commits/optimize .This change can be done in solrconfig.xml.
3. SFPSGH on fields without docValues or on a large result set
SFPSGH -> Sort/Facet/Pivot/Stats/Group/Highlight
If you run SFPSGH query on a field without docValues, then Solr can not make use of the OS cache and will have to load the whole index for that field into the JVM (Java virtual machine). This will cause Solr nodes to go OutOfMemory if the index for that field is more than the JVM heap allocated to Solr.
Even if Solr does not go OutOfMemory, FieldCache does not get pushed out of the Solr JVM but stays forever until the Solr nodes are restarted or you reload the collection.
Solution: Enable docValues (docValue=true) for the fields and Narrow down the query result set where you have to perform SFPSGH operations.
Note: Do not enable docValues for all fields. DocValues have a performance penalty on the write side and will cause your ingestion to slow down if you have enabled it on a lot of fields. Also, changing docValue requires reindexing of documents.
4. Unlimited faceting
You need to be careful about setting appropriate facet.limit parameters for your queries. This is particularly true if you set your facet.limit=-1 on a field with many unique values.
Solution: Try to restrict the number of result set for faceting, facet on docValue enabled fields, and use json facet API instead of old-style faceting.
5. Storing all fields in Solr
Search indexes are RAM-limited since they have to keep most of the index in memory. So unnecessary field storage cause performance problems or increases hardware costs.
Sometimes, there are fields that aren’t searched but need to be displayed in the search results. You accomplish that by setting the field attributes to stored=true and indexed=false.
storing fields increases the size of the index, and the larger the index, the slower the search.
Solution: Store and index fields that are needed as per business requirements.
6. Catch all field
The _text_ field with an entry like <copyField source=”*” dest=”_text_”/> in the managed schema is called catch-all field.
In some cases this can be enabled, in case the client does not know what fields may be searched, but be very careful while designing the pipeline for field type of catch-all field. In case you have synonym expansion or graph filter factories then the parsed query can explode and may result in out of memory issues, especially if you are using solr 7.x, See this bug report snippet :
 https://issues.apache.org/jira/browse/SOLR-13336
https://issues.apache.org/jira/browse/SOLR-13336For more details read here.
Solution: catch-all field significantly increases your index size. If you don’t need it, consider removing the field and corresponding copyField directive.
7. Heap size: Too large or too small
You need to understand that one size does not fit all when it comes to heap usage in Solr. You want a heap that’s large enough so that you don’t have OOM exceptions and problems with constant garbage collection, but small enough that you’re not wasting memory or running into huge garbage collection pauses.
Solution: The best way to determine the correct size is to analyze the garbage collection (GC) logs located in your logs directory. There are various tools like GCViewer and GCEasy that help analyze these logs and, in particular, show the amount of memory used after GC has completed.
8. Large Transaction Logs (TLOGs)
TLOGs are only rolled over when you tell Solr to, i.e. issue a hard commit (or autoCommit happens, configured in solrconfig.xml).
So in bulk-loading situations where you are loading, say, 1,000 docs/second and you don’t do a hard commit for an hour, your single tlog will contain 3,600,000 documents. And an un-graceful shutdown may cause it to be entirely replayed before the Solr node is open for business. This may take hours.
Solution: If you have very large tlogs, this is a Bad Thing and you should change your hard commit settings.
9. Storing billions of documents in a shard
Keep in mind that Lucene/Solr has a limitation of about 2.14 billion documents per lucene-index , But in Solr, even deleted documents count toward a regular document and the result of an update is not 1 document → it is 1 deleted document and 1 new document.
So deleted documents also count toward the 2.14 billion document limit. Since it’s hard to estimate the deleted documents, it is recommended to limit the number of regular documents to 1 billion. This gives you room for deleted documents and some buffer to expand.
Solution: Plan your sharding strategy considering data growth for the next 6 months to a year. You can start with an Index/Ram Ratio of 1.5 or 2, let's say you have 100 million docs with 1 KB size, which means a total size of 100 GB.
With an Index/Ram Ratio of 1.5 or 2 in each node/compute with 25 GB of RAM, you can keep index size up to (35 to 40) or 50 GB (if query rates are low with minimal facets/pivots queries).
and you would need a minimum of 2 or 3 shards to accommodate 100 GB.
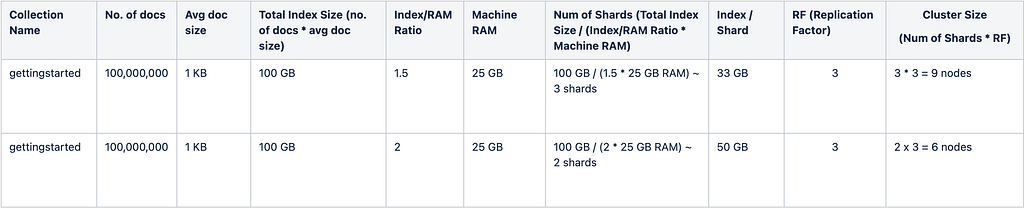
Note: This is just an example to start with, you have to do proper performance testing to get the actual numbers that meets your read and write throughputs.
10. Grouping/Faceting on unique key
Grouping or Faceting on a unique key is not a valid use case because the count will always be 1 for the unique key field. But sometimes users do such mistakes unknowingly and it can result in cluster outage.
Consider jobId is defined as a unique Key in your managed schema then running the below queries can result in OOM, as grouping and faceting are heavy operations if the cardinality (number of unique values in a field) of the field is huge (for the unique key field the cardinality will be the highest).
q=*:*&group.ngroups=true&rows=0&group.field=jobId&group=true
q=*:*&facet.limit=-1&facet.field=jobId&rows=0&facet=true
Note: In case you want to sort on a unique key, make sure you are not sorting millions of records, try to narrow down the search results before running complex operations like SFPSGH.
Solution: Avoid running faceting/grouping on a unique key.
Conclusion
This post is the first part where we listed the 10 most common solr anti-patterns and their alternate solutions. In part 2, we will cover some more anti-patterns and solutions to help you improve the stability and performance of your clusters. Stay tuned!
Solr Anti-patterns — Part1 was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Solr Anti-patterns — Part1. An anti-pattern is a common response to… | by Dinesh Naik | Walmart Global Tech Blog | Medium