
Introduction
ORC file stripe size is a critical factor in optimizing Trino query performance. This blog explores how ORC files, as columnar storage formats, influence data processing efficiency and why stripe size matters. It also presents insights gained from controlled experiments on the impact of different stripe sizes on Trino queries.
By understanding the significance of ORC file stripe size, readers will gain actionable knowledge to enhance their Trino-based big data analytics.
ORC files and their significance in big data processing
ORC (Optimized Row Columnar) files are columnar storage files that offer several benefits over row-based formats. They are compressed, support predicate pushdown, can handle skewed data, are compatible with Hive and Trino, and support complex data types.
Here is a table that summarizes the key features and benefits of ORC files:
- Columnar Storage: ORC files organize data in a columnar format rather than row-based, which enhances compression and processing efficiency for specific columns during queries.
- Compression: Using diverse compression techniques, ORC files reduce storage space and improve query performance. The columnar layout leads to efficient compression due to the grouping of similar data values.
- Predicate Pushdown: ORC files support predicate pushdown, filtering data before reading from disk during queries. This leverages the columnar storage to minimize disk reads, leading to faster query processing.
- Data Skew Handling: ORC files effectively manage skewed data. For heavily skewed data values, ORC can isolate and store them separately, enhancing query performance in such cases.
- Hive and Trino Compatibility: ORC files are natively supported by Apache Hive and Trino, allowing seamless integration into big data ecosystems. Users can utilize existing tools and infrastructure effectively.
- Complex Data Types: ORC files accommodate complex data types like structs, lists, maps, and unions, enabling storage and processing of nested and hierarchical data in an organized manner.
Trino as a distributed SQL query engine
Trino is a powerful distributed SQL query engine in big data analytics. Known for high performance and scalability, it is favoured for its distributed architecture and versatile capabilities.
- High Performance: Trino executes queries with exceptional speed by leveraging distributed processing across nodes, managing large data and complex queries efficiently.
- Scalability: With horizontal scaling, Trino grows by adding worker nodes, managing increasing data volumes and query demands.
- Compatibility: Trino adheres to ANSI SQL standards, integrating seamlessly with various SQL-based tools and systems.
- Data Source Agnostic: Trino works with diverse storage systems, be it relational databases, data lakes, or cloud storage, consolidating data sources for holistic analysis.
- Federated Queries: Trino supports querying multiple sources as a single database, simplifying data analysis by seamlessly combining data.
- Interactive Analysis: Trino offers real-time data exploration and analysis with low-latency performance, perfect for ad-hoc and iterative analysis.
ORC Stripes
ORC file stripe size is a key parameter for improving big data analytics performance. Stripes are chunks of data that are stored in ORC files. Each stripe is an independent section of the file that contains a specific amount of data.
The stripe size is a critical parameter for ORC file performance. It determines the size of each individual stripe in the file, which can vary depending on the data access patterns and data characteristics. Stripe sizes are typically set in bytes and can range from a few kilobytes to several megabytes.
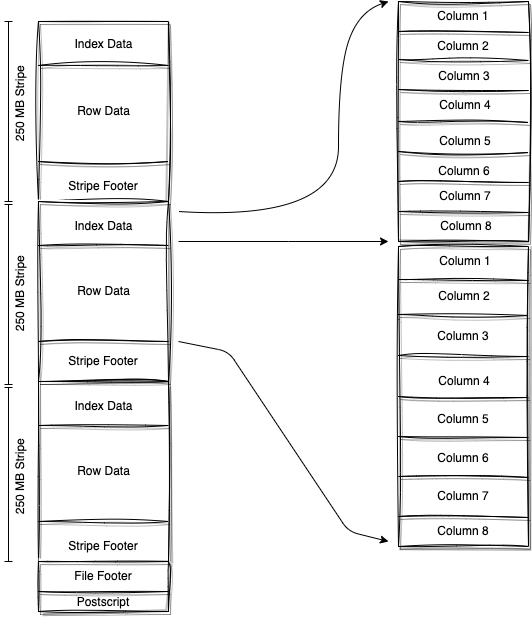 ORC File Structure
ORC File StructureSmall ORC Stripes = Poor Performance in Trino
While smaller stripe sizes in ORC files can offer benefits such as better compression, improved predicate pushdown, and more efficient memory utilization, they can also lead to suboptimal performance in Trino queries due to several reasons:
- Metadata Overhead: Smaller stripe sizes mean more stripes in the ORC file, which increases the amount of metadata associated with each stripe that Trino needs to read and process this metadata. This can lead to slower query execution.
- Increased Disk I/O: Trino reads data in chunks (stripes) from disk during query execution. With smaller stripe sizes, more disk I/O operations are required to read the same amount of data. This can result in increased latency and slower query performance, especially when dealing with a high volume of data.
- Network Overhead: Trino distributes data across worker nodes in a cluster for parallel processing. Smaller stripe sizes can lead to more frequent data transfers between nodes, causing higher network overhead.
- Reduced Compression Efficiency: While smaller stripe sizes can improve compression efficiency for individual stripes, they can also lead to less efficient overall compression for the entire ORC file. This can lead to larger file sizes and increased storage requirements.
- Suboptimal Predicate Pushdown: Predicate pushdown is a technique that can help to improve query performance by allowing Trino to filter data before it is read from disk. Smaller stripe sizes can theoretically allow for more efficient predicate pushdown, but in practice, the overhead of managing and processing many smaller stripes can outweigh the benefits. This can result in less effective predicate pushdown and reduced query performance.
Smaller stripe sizes can be beneficial in some cases, but they can also lead to inefficiencies in Trino queries. Striking the right balance between stripe size and other performance considerations is essential to achieve optimal query performance in Trino. The optimal stripe size will vary depending on the specific workload and data characteristics.
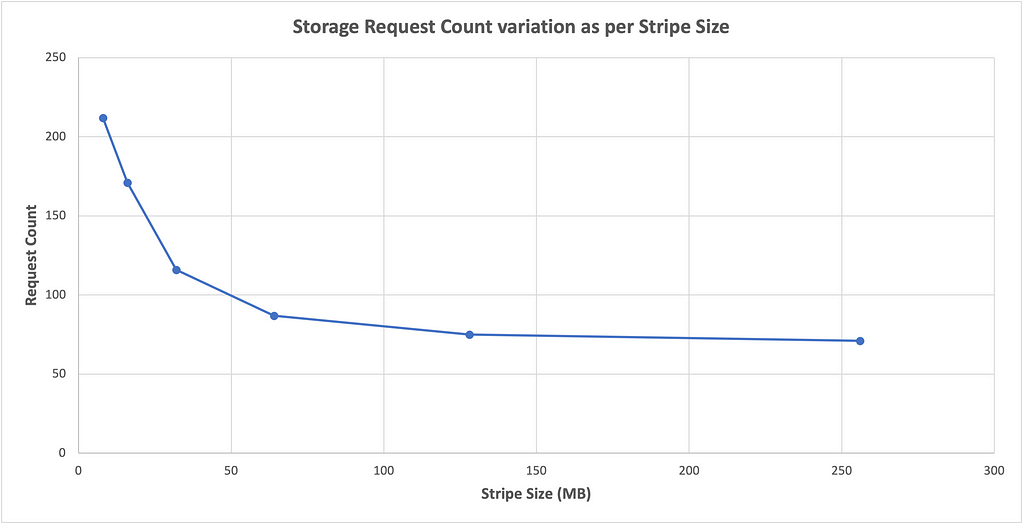 Data read request count to underlying storage decreases with the increase in ORC stripe size.
Data read request count to underlying storage decreases with the increase in ORC stripe size.We performed an experiment with ORC files of 900 MB, varying stripe sizes from 8 MB to 256 MB. The chart above shows that Trino made fewer data read requests to the storage underneath for data retrieval. It is evident that as the stripe size increases, the number of data read requests from Trino to the storage decreases.
Trino Configuration for Handling Stripes
Trino configuration property “hive.orc.tiny-stripe-threshold” determines the threshold size below which ORC files will be considered as “tiny stripes.” This property affects the stripe/file size threshold when ORC reader decides to read multiple consecutive stripes or entire files at once
The property has three main effects:
- Storage Efficiency: Each stripe in an ORC file has associated metadata. For tiny stripes, this metadata overhead can become proportionally larger, potentially leading to inefficiencies. By treating tiny stripes differently, ORC aims to reduce this metadata overhead and optimize storage.
- Query Performance: Tiny stripes can be less efficient for query processing due to the increased metadata overhead. By setting a threshold with “hive.orc.tiny-stripe-threshold,” you can ensure that very small stripes are treated in a way that balances storage efficiency with query performance.
- Configuration: The value you set for “hive.orc.tiny-stripe-threshold” specifies the size (in bytes) below which a stripe will be considered as “tiny.” This value should be chosen carefully, considering factors such as the typical size of your data, the hardware configuration, and the query workload.
Considerations for Choosing Stripe Size
Choosing the right stripe size for ORC files involves considering various factors that can impact query performance, storage efficiency, and overall system resources. Here are some key considerations to keep in mind when choosing stripe sizes:
- Data Volume: Consider the volume of data being processed. Smaller stripe sizes may be suitable for smaller datasets or when dealing with real-time, small queries. For larger datasets, larger stripe sizes might be more efficient to minimize metadata overhead and reduce the number of stripes.
- Query Complexity: Analyze the complexity of the queries being executed. Smaller stripe sizes may benefit queries with predicate filters or selective column access due to improved predicate pushdown and better memory utilization. On the other hand, larger stripe sizes might be more efficient for queries involving large-scale scans or aggregations.
- Data Distribution: Examine the data distribution patterns in the dataset. If the data is evenly distributed, both small and large stripe sizes might perform well. However, for skewed data distributions, smaller stripes can handle data skew more efficiently by storing skewed data separately.
- Query Throughput: Consider the query throughput requirements. Smaller stripe sizes might be beneficial for handling a higher number of concurrent small queries effectively. Larger stripe sizes can optimize query throughput for larger queries with reduced metadata and I/O overhead.
- Disk Utilization: Assess the disk utilization requirements and constraints. Smaller stripe sizes can optimize disk space usage by enabling better compression for individual stripes. Larger stripe sizes can minimize disk fragmentation and reduce overhead for metadata storage.
- Workload Variation: Consider the variation in the types of queries and workloads. If the workload involves a mix of small and large queries, a compromise on stripe size might be necessary to balance performance across different query types.
- System Configuration: Consider the configuration of the data processing system, including the number of nodes, CPU, memory, and network capabilities. Smaller stripe sizes might improve parallel processing and distribution efficiency in a large cluster, while larger stripe sizes may reduce metadata overhead and network traffic.
-
Cost vs Performance Trade-off: In scenarios where queries encompass substantial data volumes, opting for a smaller stripe size might potentially affect query performance. This is due to the higher number of metadata entries, leading to increased overhead during query execution. Consequently, this could amplify the count of list and get requests made to the underlying storage, subsequently inflating access costs.
On the contrary, larger stripe sizes translate to fewer requests to the underlying storage, culminating in lower access costs. To manage the amount of data read in each request, Trino leverages the max-split-size configuration property. This property controls the largest size of an individual file section allocated to a worker.
By carefully analyzing these considerations and testing different stripe sizes on representative datasets and queries, data engineers can identify optimal stripe size which meets the specific performance and storage requirements of their data processing environment. It is often an iterative process of experimentation and tuning to find the right balance for the given workload and data characteristics.
Conclusion
ORC file stripe size is a critical factor in achieving optimal query performance in Trino queries. It directly affects compression, data access efficiency, memory usage, and data skew handling.
Finding the right balance in stripe size selection is vital for maximizing Trino’s capabilities and ensuring efficient data processing in large-scale big data analytics environments. By considering multiple factors and continuously fine-tuning stripe sizes, organizations can unlock the full potential of Trino for fast, efficient, and reliable data analytics and exploration.
Significance of ORC File Stripe Size in Trino Queries was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.