At Endgame Engineering, we believe that a high standard for performance can’t exist without taking risks and learning from failure. It’s necessary for growth. We learn from other companies like Honeycomb.io and Github that document and publish their internal postmortems. These engineering teams understand transparency is fundamental to building great teams and delivering customer value with a SaaS product. We think so, too.
We also believe it’s important to eat our own dog food. That’s why the very same endpoints we use to develop our product also run it. In October, we experienced a brief outage on this system. Production resiliency, to include our dogfooding instance, is paramount to our unique mission. We take all production incidents seriously.
This postmortem provides an overview of the technology, a summary of the problem and its reproduction, and lessons learned. We are also releasing two tools we developed during this analysis to help others find and fix similar problems in the future.
Background
Last year we began migrating from RabbitMQ to nats.io, a Cloud Native (CNCF) log based streaming messaging system written in Go. NATS is simple, highly performant and scalable.
Simplicity matters. It makes a difference when an engineer is observing a complex, distributed, and rapidly evolving system. Have you ever seen an Erlang stack trace?
Performance and scalability matters, too. Our customers protect online and disconnected endpoints with our product. NATS helps us deliver speed and scale for our customers. As Robin Morero says in this Pagero blog, “performance, simplicity, security and availability are the real DNA of NATS.”
NATS is a compelling technology choice. Most of our microservices are written in Go. After an analysis by our engineering team, we started repaving most of our major microservice highways with NATS.
Symptoms
An initial triage narrowed the problem down to one of our NATS streaming server channels, sensor.session.open.
This channel is used by sensor management microservices to notify subscribers when new endpoints are online. Messages published to this subject contain important information to route tasks to sensors.
NATS provides monitoring endpoints to observe channels and subscribers.
In the output from /channelsz below, we observe a count of published messages to sensor.session.open with last_seq. We also see the number of messages delivered and acknowledged for each subscriber with last_sent and pending_count respectively. Each last_sent field should be close or equal to last_seq when the system is behaving.
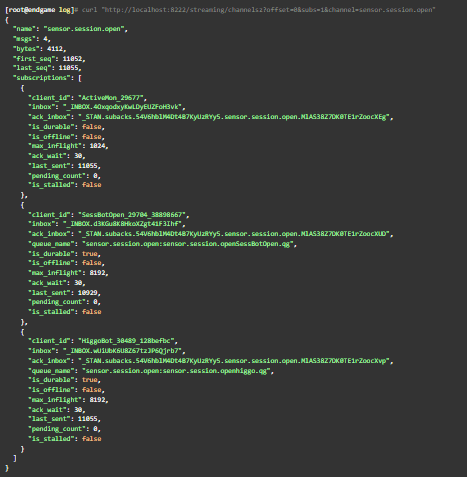
Here we see 11,055 messages have been published so far to sensor.session.open with last_seq. But last_sent for one of the three subscribers, SessBotOpen, is 126 messages behind. This is bad.
We observed /channelsz several more times. Each time, last_sent for SessBotOpen did not increase while the other two subscribers kept up with the channel’s last_seq. Moreover, the pending_count for SessBotOpen remained at zero. If messages were delivered but unacknowledged, we’d expect this count to be more than zero.
We suspected NATS streaming server was not delivering published messages to SessBotOpen. This microservice learns where to route sensor tasks by observing messages published to this channel.
A review of NATS issues showed us earlier this summer a similar bug was reported by Todd Schilling in nats-streaming-server issue #584.
We’re currently running NATS streaming with embedded NATS on a 3 node cluster in docker containers on AWS. We’ve seen several cases where a single subscription stops receiving messages. New subscriptions for the same channel receive all current messages. We can’t figure out what cases this behavior but our current work-around is to create a new subscription, which isn’t viable going forward.
This bug was fixed in v0.10.2 by Ivan Kozlovic. We were still using v0.9.2 in October.
While it’s enticing to assume an upgrade of NATS streaming server resolves our issue, we had no proof issue #584 was the root cause. Assumptions are the enemy of debugging. We did not know how to reproduce the problem. Without a reproduction, we could not promise our customers and partners this problem is fixed -- and that’s really important to us.
Reproduction
To come up with a reproduction theory we could test, we looked at the evidence and studied the NATS streaming server code.
During an upgrade, we noticed a new log message when NATS streaming server was restarted.
We’d not seen this log before. To see what it indicates, take a look at the code that produces it in server.go line 3087 from NATS streaming server v0.9.2 on github.
This log comes from a function named performDurableRedelivery(). It is called when NATS needs to resend a durable subscriber outstanding (unacknowledged) messages.
Let’s learn more about durable subscribers. From the nats.io documentation:
Durable subscriptions - Subscriptions may also specify a “durable name” which will survive client restarts. Durable subscriptions cause the server to track the last acknowledged message sequence number for a client and durable name. When the client restarts/resubscribes, and uses the same client ID and durable name, the server will resume delivery beginning with the earliest unacknowledged message for this durable subscription.
Our SessBotOpen client is a durable subscription. Messages sent to it before NATS streaming server was restarted were redelivered after the restart because they were not acknowledged.
Two of the subscriptions to this subject are durable. This means there is additional evidence that can reveal what happened in the file stores on disk. The location of these files is managed by the configuration file.
The structure of these files is defined here in filestore.go. Each time a message is published to the durable queue, it is saved to msgs.x.dat and indexed in msgs.x.idx in a function called writeRecord(), defined here in filestore.go on line 657.
If you search for calls to writeRecord in filestore.go, you’ll see this data could help us reproduce the bug. The timestamps associated with each message in the index seem especially useful.
To see this data, we created parse-nats-data.
Let’s examine messages from an exemplar system where we observed a similar problem. We focus on the last message published before NATS restarted and the first one after it came back online. We restarted NATS streaming server at 2018-10-03 01:16:24 UTC.

Recall earlier that last_sent for client SessBotOpen was stuck at message 10,929. Now we have evidence it was the last message sent before the restart.
Next let’s look at the subs.dat subscriber data for sensor.session.open to see what else we can learn. This file records several interesting subscription and message events. The types of events stored in this file are described in filestore.go on line 383.
The subs.dat file records the following events:
-
New subscription to a subject
-
Updates to an existing subscription
-
Subscription deletes (unsubscribes)
-
Message acknowledgements
-
Delivered messages
Analyzing this evidence could help us reproduce the bug. The format of this file is the same. The structure of each message is defined in nats-streaming-server/spb.
NATS streaming records metadata about every message and each subscription activity. Let’s focus only on the SessBotOpen client that subscribes to sensor.session.open.
In the output below from parse-nats-data, we’ve included just three event types:
-
New or updated subscriptions
-
First published message after SessBotOpen subscribes
-
First acknowledged message after SessBotOpen subscribes
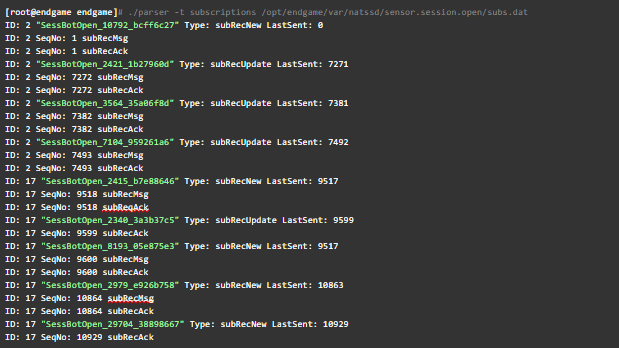
An interesting pattern emerges in the data above.
First, we see the internal NATS subscription ID is frequently reused each time a new SessBotOpen client subscribes after a restart. Not shown above in the output for subs.dat are other new subscriptions. Each time other clients subscribe to channels they seem to get a new subscription ID. SessBotOpen does not. This is unusual.
Second, each time SessBotOpen subscribes to sensor.session.open, we see the next message in the sequence (last_sent + 1) published and acknowledged – except for two clients:
-
SessBotOpen_2340_3a3b37c5
-
SessBotOpen_29704_38898667
In both cases, something unique happens. After SessBotOpen subscribes, an outstanding message is acknowledged. Specifically, the last_sent message before the restart.
Recall performDurableRedelivery() is responsible for redelivering all outstanding messages to a durable subscriber when it resubscribes. Let’s go back to the NATS streaming server logs.

We see the same two clients from subs.dat. This is a compelling lead. And it’s possible the problem also occurred on this exemplar system back in September but we didn’t detect it. NATS streaming server was restarted 8 minutes later.
What do we know? To reproduce the bug, it seems important to publish a message but force the subscriber to wait to acknowledge it until after NATS is restarted. We also observe that the subscription ID rarely changes while other subscriptions change each time they subscribe.
Let’s focus on recreating the two specific scenarios we observed in subs.dat.
-
Theory: There is a race condition in acknowledging messages during a NATS restart when a durable queue resubscribes and is assigned the same subscription ID.
-
Test: Let’s write a NATS streaming server test to recreate these two conditions.
The NATS streaming server unit test we create must do the following things:
-
Ensure we’re using the file system store with getTestDefaultOptsForPersistentStore()
-
Provide the ability to delay message acknowledgement in our QueueSubscribe() callback function
-
Publish one message
-
Close down the subscription so that it resubscribes with the same subscription ID after a restart
-
Restart NATS before the callback attempts to acknowledge it
-
Resubscribe with a new callback function that will acknowledge messages
-
Make sure new messages are delivered
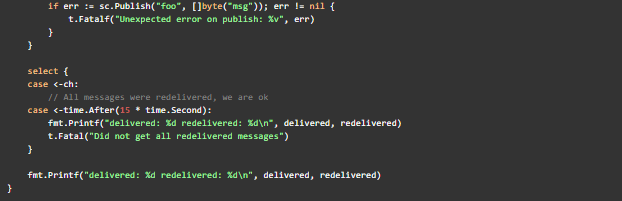
We’ll create a new test called TestRedeliveryBug and setup the data store first. It can help us validate that we’ve recreated the two earlier observations from subs.dat. The unit test is shown in full at the end of this blog.
There are two key ingredients to the test derived from our analysis of subs.dat.
First, we need to control how long we take to acknowledge messages in the callback function to recreate the message acknowledgement race condition. This is one of the two important conditions we want to recreate from subs.dat. We’ll send one message and wait 5 seconds before we acknowledge it. This will give us time to restart NATS streaming server.
Second, we need to force the subscriber to reuse the same internal subscription ID. The NATS streaming server Remove() function shown below from server.go from line 858 reuses subscription IDs if the client does not first unsubscribe.

We want to unsubscribe our callback function in our test so it does not receive data. This is similar to what happens when we restart NATS and the SessBotOpen microservice. We can call closeClient() first, which eventually calls Remove(), to ensure the subscription ID is reused on restart.
After we restart, we resubscribe, acknowledge messages quickly (in 10ms instead of 5s) and publish 20 new messages. If we recreate the bug, none of these messages will get delivered.
Let’s see if we can recreate the bug on v0.9.2 of NATS streaming server.
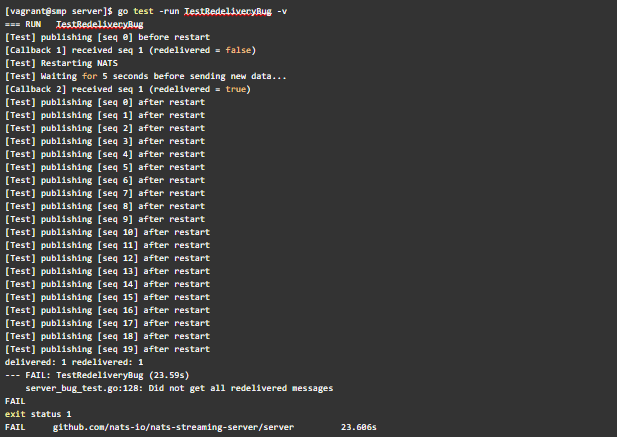
Executing TestRedeliveryBug on NATS streaming server v0.9.2
No new messages were delivered to the subscriber when the acknowledgement is delayed after a restart – even after it acknowledged the outstanding message!
Let’s run the same test again against the latest version of NATS streaming server (v0.11.2).
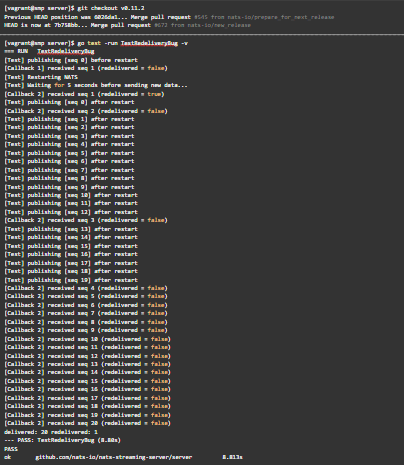
Executing TestRedeliveryBug on NATS streaming server v0.11.2
It works as expected! All messages, including the first outstanding message, were delivered to [Callback 2]. We also observed the same behavior in subs.dat by using parse-nats-data on the unit tests file store that was left behind.
We reproduced the bug!
Where was the bug?
Now that we have a reproduction, let’s see where the bug lives. The sendAvailableMessagesToQueue() function in server.go line 4572 is responsible for sending messages to subscriptions.
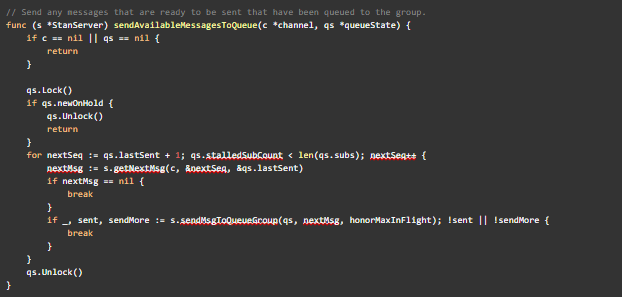
sendAvailableMessagesToQueue() function in server.go
Note that if qs.newOnHold is true, messages do not get delivered. We observed that updateState() from server.go sets this to true when the two conditions from subs.dat happen to a durable subscription in v0.9.2. It’s never set to false again and new messages never get delivered.
Let’s see why it works in v0.11.2 by finding the same line of code in updateState(). We see this specific code was moved up to the conditional above it in this commit on 3 July 2018.
[FIXED] Possible stall of durable queue after server/cluster restart
If a durable queue had no member running but had unacknowledged messages, and if the server (or cluster in clustered mode) was restarted, redelivery of unacknowledged messages may occur when the queue was restarted but new messages would not be delivered.
Resolves #584
It was NATS streaming server issue #584 all along! And if we look at the test added for this fix, it’s very similar to our test – only better.
Conclusion
In this postmortem we reviewed the symptoms of an incident that occurred after an upgrade of our cloud customers. We narrowed the problem down to a durable subscriber that was not receiving new messages after a restart. Further analysis of the evidence and code allowed us to reproduce a bug in NATS streaming server.
At Endgame Engineering, we take production incidents seriously. We want to earn the trust of our customers by proving the same problem will not happen twice. These postmortems are opportunities for us to share what we learned, how we improved, and the tools we’ve built with the community.
Here are a few lessons learned.
Debugging is mostly studying code and evidence
Debugging is a discipline. It requires comparing evidence with code (99% of the time it will be code you didn’t write or don’t remember writing). Assumptions in evidence or in how something works may seem like they save you time but they are the enemy of debugging. They will take up more time or worse – you’ll just be wrong.
I still find myself making assumptions. But I have to remind myself I can be wrong but evidence and code usually isn’t.
Tenacity is important
When it comes to delivering customer value -- don’t give up. Especially if you’ll learn something that can be shared with others. We tested three different theories to try and reproduce the bug. After the first two experiments failed, I was almost ready to give up. But there was more unexplored evidence in subs.dat. That was the breakthrough that led to a reproduction.
Code readability is important
This seems obvious, but studying code is so much easier when it’s straightforward and understandable. It’s one of the advantages of using NATS streaming server. It’s very simple and easy to read. Code and design readability helps others, and even your future self, understand what the code is doing so that it can be debugged quickly.
Chaos experiments are important
We need to make a larger investment in chaos experiments to tease out new failures in production. While simplicity matters, it’s important to embrace and navigate the emergent complexity in our systems and organizations.
Today we craft a number of experiments to study failure and build confidence in our ability to withstand turbulent conditions in production at massive scale. This problem showed us we can do more. We’re looking forward to sharing more of this with the community in upcoming blog posts on the topic.
In the meantime, I recommend you watch Casey Rosenthal’s GOTO Chicago 2018 talk, Deprecating Simplicity.
Create tools to find failure
Building tools is an essential part of debugging and experimenting to find failure. In addition to parse-nats-data, we are also sharing another tool we’ve built in Go, aws-logsearch, to search multiple AWS CloudWatch log groups at once on the command line. This allowed our incident responders to quickly validate this problem did not impact other customers.
This postmortem analysis was rewarding. I hope you found it useful.
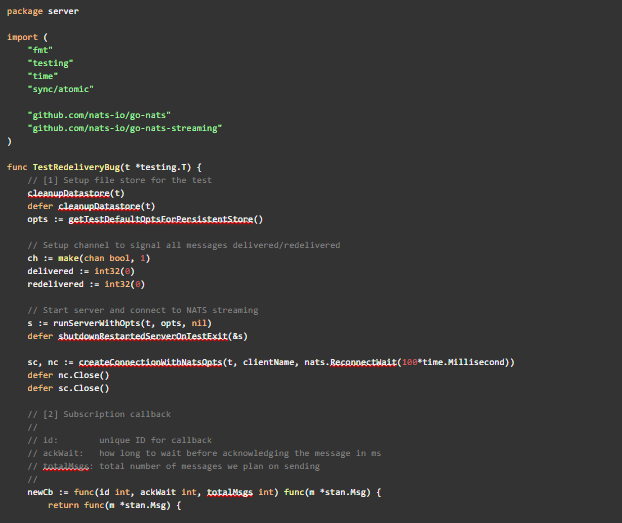
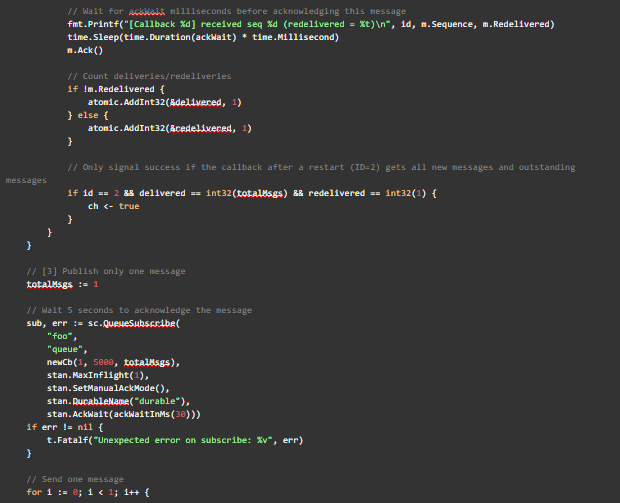
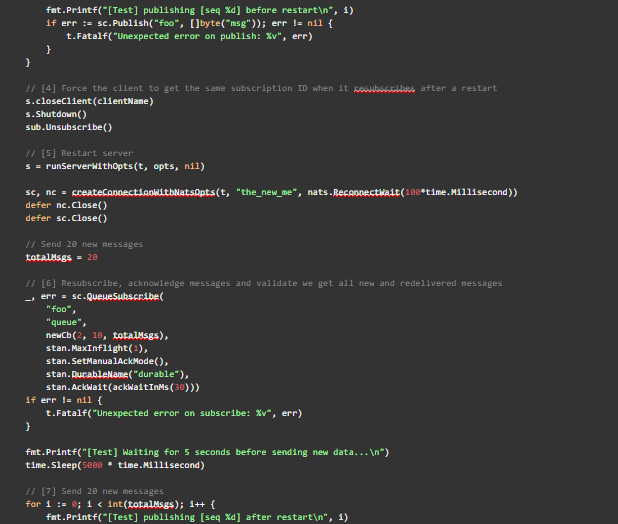
Appendix: Reproduction Unit Test
The unit test in its entirety to recreate the two conditions we observed from subs.dat is shown below.
Article Link: https://www.endgame.com/blog/executive-blog/postmortem-beating-nats-race