

I identify myself as an Engineer, a problem solver who fell for AI & Data Science in his formative years. Always wanted to bring the best of both worlds, the analytical reasoning of an engineer and the brilliance of a data scientist by becoming a Machine Learning Engineer/Applied Data Scientist(the way I see it). It is important to understand the mathematics and concepts behind the beauty of data science and it is equally important to shape a mere concept into reality and transform it into an actual product. Being a hands-on engineer and well versed with the challenges & the significance of execution and experimentation required to obtain the desired output. With an ode to Dr. APJ Abdul Kalam, Tony Stark(Iron man), Elon Musk, and Howard Wolowitz, I am initiating this series wherein we’ll witness the crude side of neural networks abstracted under the sophisticated sleeve of state-of-the-art ML/DL libraries. So, let’s embark on a journey of enlightenment and demystifying the world of AI.
For coding the neural networks, we have python to the rescue. Audiences who would like to learn Python can do it the hard way(not literally) Learn Python the hard way.
The AI Family
Though Neural Networks gained popularity after 2010 the intuition dates back to the 1940s. They gained popularity after winning competitions and predicting/generating values which was deemed impossible otherwise. I personally feel Neural Networks gained momentum with the advancements in computation devices and the exponential growth in data generation. With the increase in processing speeds and GPU coming into the picture, training neural networks became practical for business purposes. “Data is the new oil”, this statement is sufficient to explain the importance of data for modern businesses(Also, for the new Facebook/Whatsapp privacy policy) and the imperativeness to feed them with the new fuel.
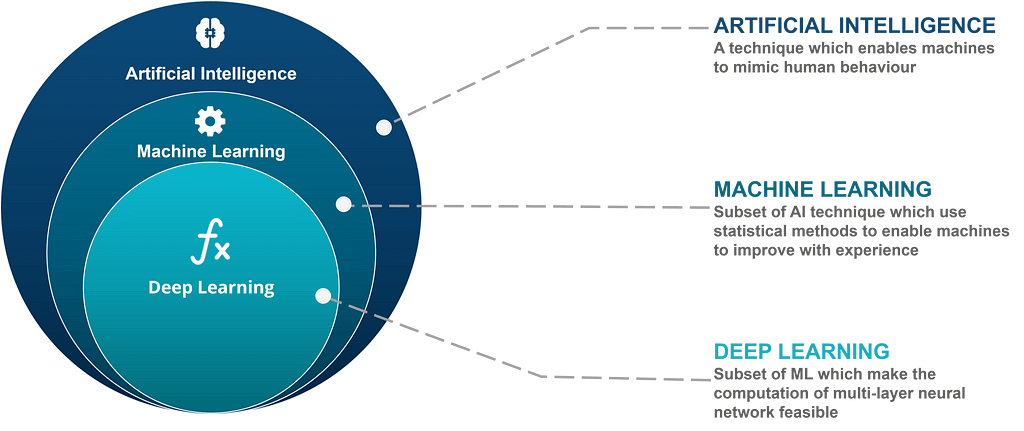 AI Hierarchy(Source)
AI Hierarchy(Source)Any procedure imitating human behavior can be considered under the wide umbrella of Artificial Intelligence. The tasks pertaining to the statistical subset of AI can be labeled as Machine Learning. Deep Learning is a subgroup of machine learning dealing with Multi-Layer Perceptrons/Neural Networks.
Neural Network Structure
Neural Networks are very similar in structure to the nerve cell also known as neurons. Each node in neural networks mimics the behavior of neurons in the biological nervous system. Though a single node is not practically effective but does wonders when fused with other nodes to form a neural network.
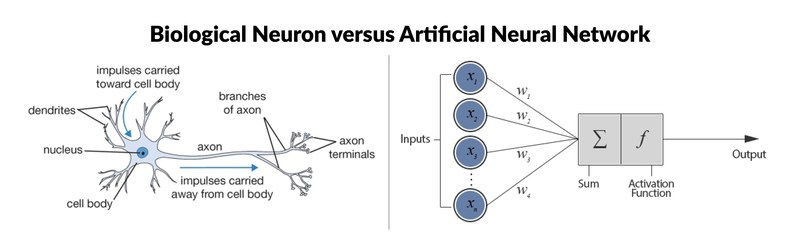 Source
SourceMathematical Overview
There are certain parameters that neural networks need to “Learn” to generate predictions. The parameters include the weights and biases of each node. Let me give you an idea of what weights and biases actually mean, consider an equation y=mx+c, where y is the value we need to identify(target variable), x is the input, m is the slope of the line(weight) and c is the constant(bias). m and c are the parameters to be identified in case we need to find the value of y from x.
Now, how do we calculate how many parameters our neural network has to learn?
 Neural Network Layers (Source)
Neural Network Layers (Source)Consider the above figure, a neural network with 1 input layer, 3 hidden layers, and 1 output layer. The input layer consists of 3 nodes: a1, ak, and ax. The output layer consists of 2 nodes: nk and nv. Now, focus on the interaction of the input layer with Layer 1, every node of Layer 1 is connected to every node of the input layer. So, each node in Layer 1 will learn 3 weights(1 for each input node). Similarly, we can extend our observation to subsequent layers and we get (35 + 55 + 55 + 52) = 75 weights. Since each node in the hidden layers and output layer will contain a bias component, the total tally of parameters reaches 92 (75 weights + 17 biases).
Our deep learning model will optimize the above parameters to predict the final result. Weights and biases impact the result in different ways, weight tends to change the magnitude of input and can reverse the sign of the value whereas bias makes an overall effect on the output. The final output from the node is the result of an activation function applied over the result obtained after the computation of weights and biases which introduces non-linearity(makes the node “fire”) and differentiates itself from classical machine learning algorithms. Hence, the final equation comes out to be:
outputFromNode = activationFunction(inputs * weights + bias)
Commonly used activation functions are ReLU, Leaky ReLU, sigmoid, softmax, tanh.
Now, it’s time we code the Layer Output Computation Utility using basic Python. Below is the code for reference. Currently, we won’t be utilizing any activation function to compute the layer output.
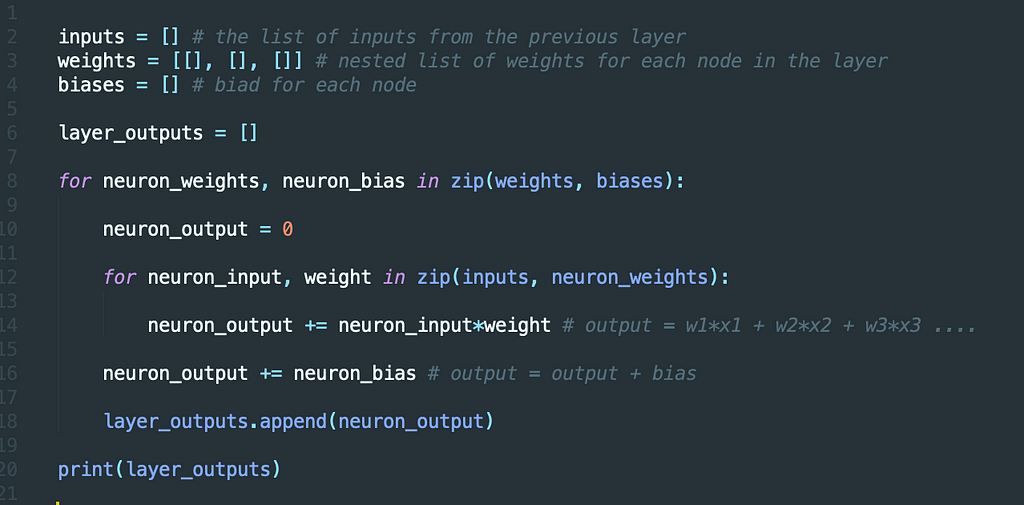 Layer Output Computation Utility
Layer Output Computation UtilityVoila! you just coded the output from a neural network layer in pure Python without any help from external libraries. However, there is still a lot of scope before we arrive at a sophisticated neural network model which performs well in real-life scenarios.
Conclusion
You can find all the codes for this series in the Github repository (Don’t forget to star it). These generic code snippets will help you build your very own neural network from scratch. Though we have reached the end of our first article it’s only the beginning of an exciting adventure. Meet you in the next one!
Other Articles
References
- Introduction to Machine Learning
- Elements of Statistical Learning: data mining, inference, and prediction. 2nd Edition.
- Learn Python the Hard Way
Neural Networks Exposed: Hello World! was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Neural Networks Exposed: Hello World! | by Rahul Bajaj | Walmart Global Tech Blog | Medium