
Hello everyone! Its been a while since I’ve posted. There’s been some changes in my life that have distracted me from my malware temporarily. One of those updates is a career change. I will officially be working as a security researcher and in preparation of that I felt that I needed to keep my reverse engineering skills sharp. So I went to any.runs malware trends page, and randomly picked a sample. I ended up picking a Nanocore sample to analyze. Nanocore has been around for many years and is one of the simpler and cheaper malware familieis out there but I never had the availability during work to look at it. Since I generally focus on targeted malware, I knew this was going to be a good change of pace. The sample can be found here if you wish to follow along.
Technical Analysis
First step as usual, is opening the sample in PE studio for a quick triage.
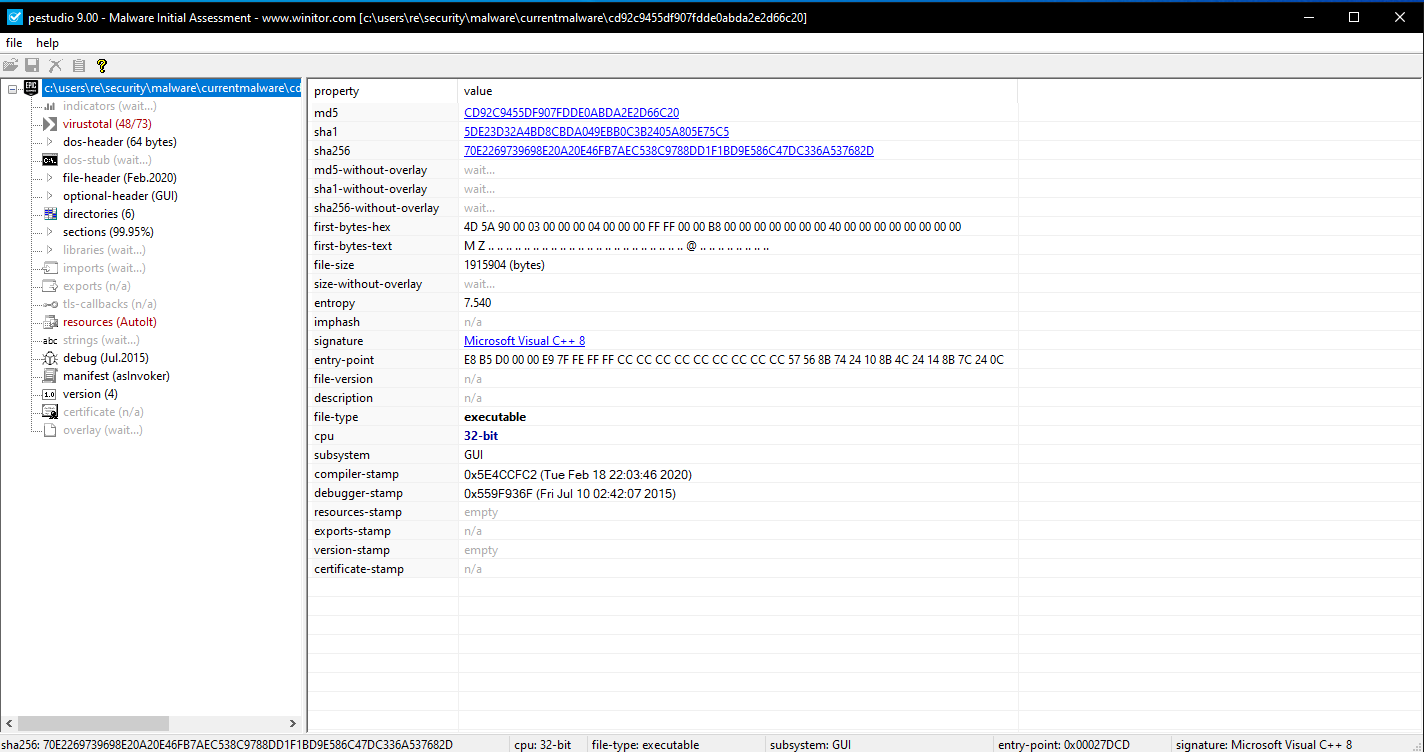
From the output here you can see its a Cpp application with a rather high entropy of 7.5. So there is definitely some encrypted or compressed content here. You can also see that there is an embedded resource within the application. Immediately the AutoIT caught my eye as that’s not something I have dealt with before.
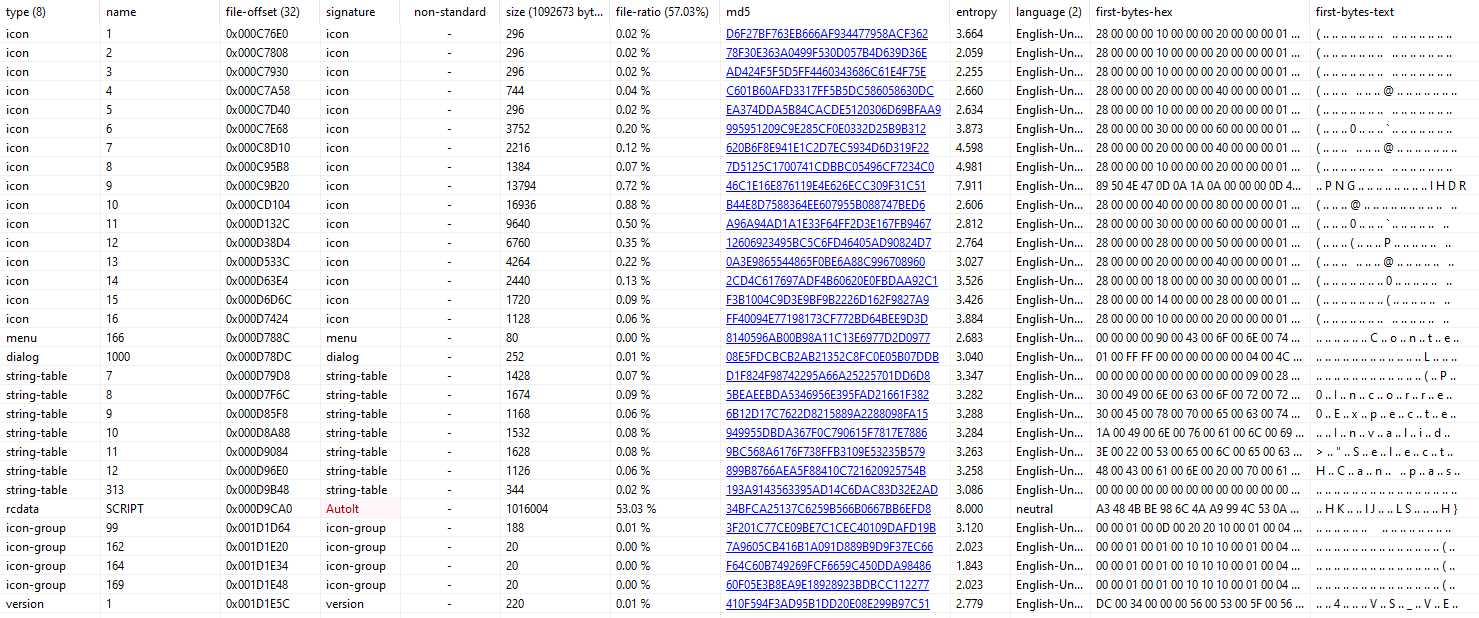
Even more suspicious is that its almost 53% of the file, and a maximum entropy value of 8. Seeing the large resource immediately leads me to look for resource related calls such as LockResource, SizeOfResource, LoadResource etc.
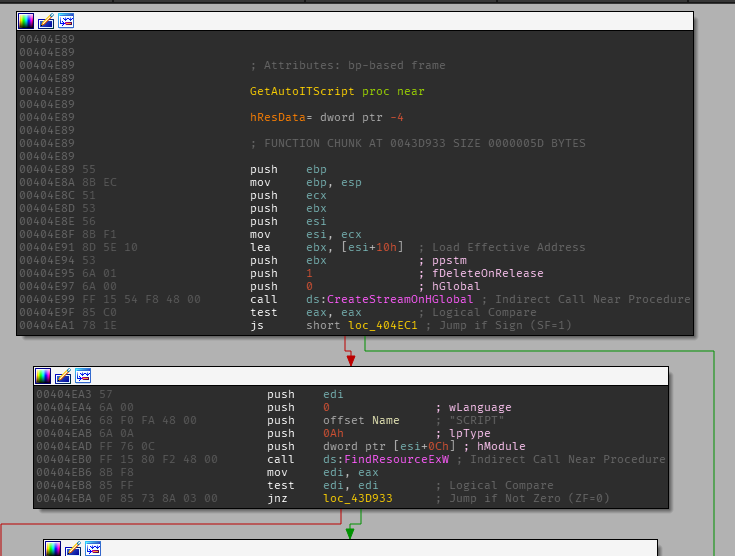
FindResource is only called within this function so if we assume that the AutoIT script is part of the malware, this function becomes increasingly important. This function will load the resource make some calls and load the resource data within [ebp+var_4].
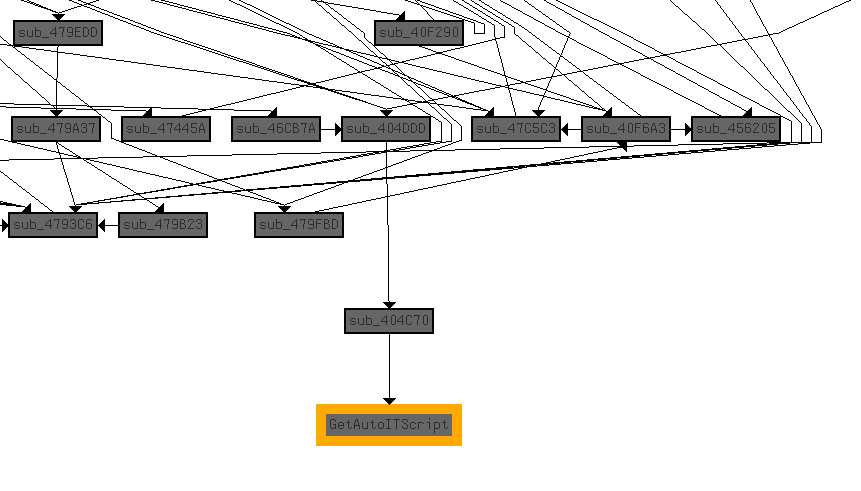
Looking at the call graph shows this is a leaf node for the call graph, which can potentially mean that execution will continue outside of the scope of this application or all the information for this chain of calls was acquired. Looking at the parent function it opens a file passed as an argument.
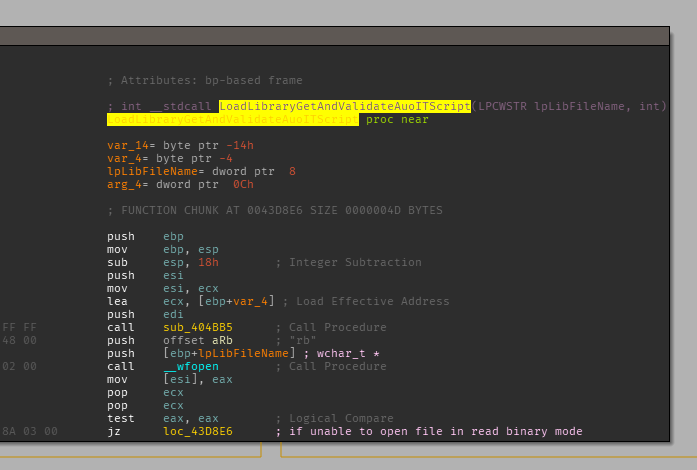
Looking at calls to this function, there are references to various AutoIT strings.
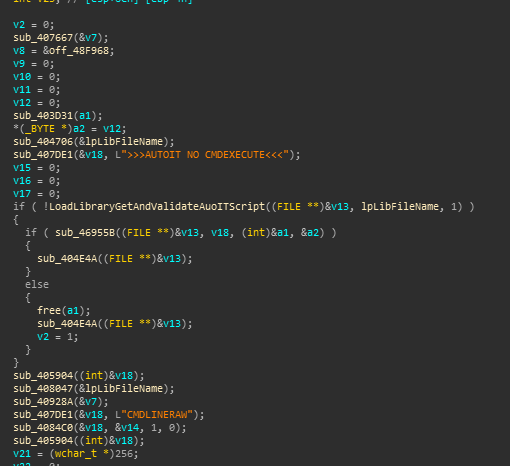
Jumping to the Main function it calls sub_403B3A which has a anti-debugger check. It calls IsDebuggerPresent and if it is, opens a message box and the process terminates
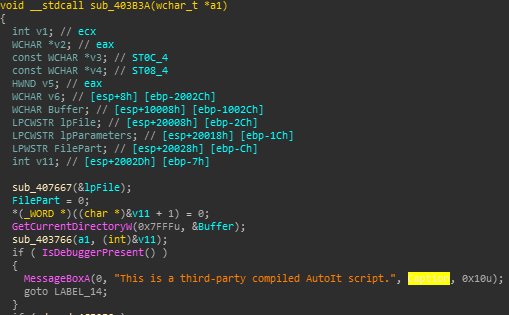
Following sub_408667, eventually the resource will be loaded from memory, and compared against a the compiled AutoIT header
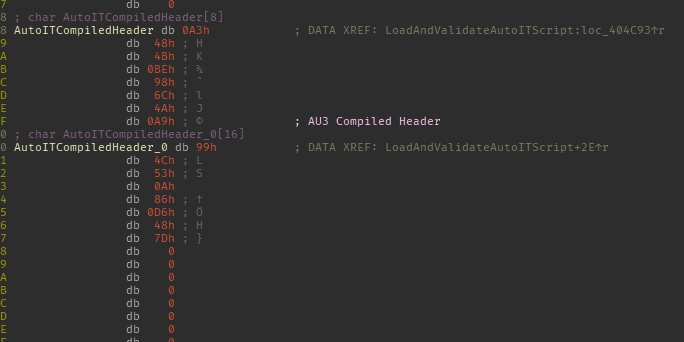
Execution only continues if the header is correct, so we can assume it’s going to load an AutoIT script. This coupled with the fact that it quits if you try to debug the executable, I’m comfortable in assuming this executable is going to load and run the compiled AutoIT script from its resource section.
AutoIT Script
Now that we know the binary file we have been looking at is just a runtime environment for the AutoIT script resource we can take a look at the script itself. Extracting the resource with Resource Hacker and throwing it in a hex editor shows that it’s a compiled script. Now there are a couple tools out there used to decompile AutoIT scripts. There is Exe2Aut which is what I went with to handle this compiled script. Although running this script through the application gave the following error…
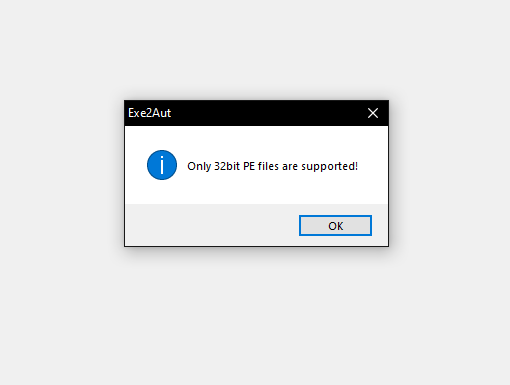 Aut2Exe Error
Aut2Exe ErrorGoogling around for this I found Hexacorn’s post about this exact issue! Following his post we append our compiled script to the 32 bit stub and we get a valid decompilation of the script!
Copying the contents to a new file in VSCode and giving it a look over immediately shows something interesting. This script is 10901 lines long. The majority of the file looks like the following.
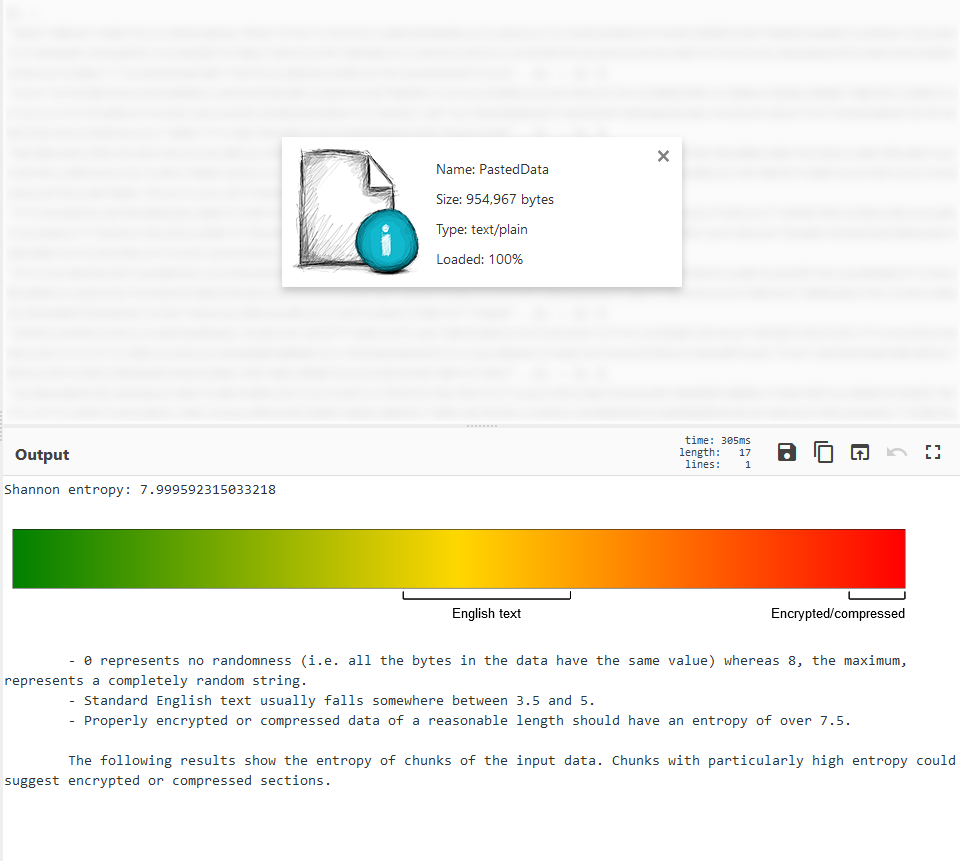
At the end of the file there is a large data blob that spans 3500 lines just on its own. Generally this means it’s some sort of payload. Loading this data blob into CyberChef shows that it is most likely either compressed or encrypted. This rules simpler techniques such as XOR encryption.
With this information I knew I’d have to give the script a good hard look. After some googling about AutoIT crypters I came across CypherIT. CypherIT is a AutoIT crypter that is sold at 5 separate tiers. the first tier is 33$ for 1 month, 57$ for 2 months and 74$ for 3 months, 175$ for FUD for 2 weeks and finally a 340$ lifetime model.

Interestingly enough they even have a discord server that users can join for troubleshooting and getting updates on new versions.
Going back to the script… After the large data blob is finished being initialized, it is passed to a function called skpekamgyg. This function takes the large data blob, a random string and a number as a string.
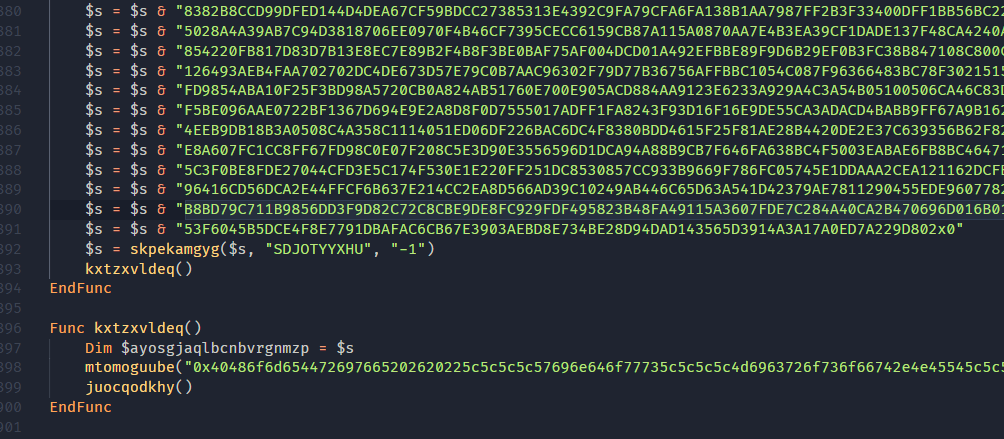
There is way too much to go into here for the crypter but these are the basic characteristics of it:
- unused variables
- unused functions
- string decryption
I ended up writing a golang based script that can handle those 3 above cases! For this sample it turned the the 10901 line script into a 6600 line one. There is some more analysis that can happen to remove function calls that aren’t actually called by the main payload decryption routine, but that would require actual function call analysis and that is out of scope for this article. The script can be found here
String Decryption
For decrypting the strings there are a couple pieces to it.
func decryptStrings(lines []string) ([]string) {
var re = regexp.MustCompile((?m)"\b[0-9A-F]{2,}\b")
modLines := []string{}
for i, line := range lines {
matched := false
tempLine := ""
tempLine += line
for _, match := range re.FindAllString(line, -1) {
matched = true
cleaned := strings.Replace(match, "\"", "", -1)
dec, err := hex.DecodeString(cleaned)
if err != nil {
modLines = append(modLines, tempLine)
break
}
decodedStr, err := xorBrute(dec)
if err != nil {
modLines = append(modLines, tempLine)
break
}
if len(decodedStr) < 2 {
modLines = append(modLines, tempLine)
break
}
if decodedStr[0:2] == "0x" {
temp, err := hex.DecodeString(strings.Replace(decodedStr, "0x", "", -1))
if err != nil {
modLines = append(modLines, tempLine)
break
}
decodedStr = string(temp)
}
if isASCII(decodedStr) {
tempLine += " ;" + decodedStr
fmt.Printf("[+] decoded string at line %d: %s\n", i, decodedStr)
} else {
tempLine += " ;" + "BINARYCONTENT"
}
modLines = append(modLines, tempLine)
break
}
if !matched {
modLines = append(modLines, tempLine)
}
}
return modLines
}
I look for hex encoded strings with a regex. Then I clean the string removing extraneous characters. Once we have a valid hex string like 307832343639373037393643363836353…33303330333033303232 we pass it to a the function xorBrute.
func xor(enc []byte, key byte) (string, error) {
ret := []byte{}
for i := 0; i < len(enc); i++ {
temp := enc[i] ^ key
ret = append(ret, temp)
}
return string(ret), nil
}
func xorBrute(encodedStr []byte) (string, error) {
switch string(encodedStr[0]) {
case “0”:
// lazy
return xor(encodedStr, 0)
case “1”:
return xor(encodedStr, 1)
case “2”:
return xor(encodedStr, 2)
case “3”:
return xor(encodedStr, 3)
case “4”:
return xor(encodedStr, 4)
}
return "", errors.New("not a valid nanocore encoding")
}
A neat little property I found about this is that the first character must decode to 0 since the actual string must start with 0x for it to be processed properly. Now in the AutoIT script the function that decodes these hex strings takes 2 arguments, a large hex string and a single character that is some number between 0 and 4 which is the XOR key. Since the value we are looking for here with the first character is 0, we can use the fact that anything XOR’d with itself is 0. So while the second argument is being passed we can figure out the 1 byte key with the switch statement.
Once we have the decoded string as a large hex value we do a check on the size to make sure we aren’t dealing with a single byte value that the regex might’ve picked up. Followed by a check to make sure it starts with 0x, if all those conditions are met we decode the hex value into ASCII and add it as a comment to the script.
Variable Cleaning
Considering that these CypherIT scripts generally have thousands of lines, it’s pretty clear they have unused variables. My technique for removing variables is simplistic but effective. I have a loop that can extract all of the variable names via a regex
getVarName := regexp.MustCompile((?m)(Dim|Local|Global Const|Global)\s\$(?P<Name>\w+)\s)If I get a variable if the “Name” regex group I scan every line for that name. In the script itself Ive done this step after decoding the strings so that all variable names are in the clear.
// count the number of occurences
occurences := 0
for _, secondLine := range lines {
if strings.Contains(secondLine, result[“Name”]) {
occurences++
}
}
// if the variable is used multiple times keep it
if occurences > 1 {
modLines = append(modLines, line)
}
Function Cleaning
Removing functions were a bit more in depth than variables as you need to be able to find the start and end of a function. Functions also have the added complexity that if you are removing a function that isn’t being called anywhere else, you might’ve isolated another function that isn’t going to reached either. So this is function that works the best when you call it multiple times. To get started, we define our regex.
var getFuncName = regexp.MustCompile((?m)Func\s(?P<Name>\w+))Then for every function name we extract, we check if it’s being called anywhere else in the script. If it’s not being called anywhere else we add it to a list that contains all functions we are going to remove.
for i, line := range lines {
// If it is a func declaration get the func name
match := getFuncName.FindStringSubmatch(line)
if len(match) == 0 {
continue
}
result := make(map[string]string)
// turn the regex groups into a map
for k, name := range getFuncName.SubexpNames() {
if i != 0 && name != "" {
result[name] = match[k]
}
}
// count the number of occurences in the new file
occurences := 0
for _, secondLine := range lines {
if strings.Contains(secondLine, result["Name"]) {
occurences++
}
}
// if the function is just used once, find it and dont write it to the file
if occurences == 1 {
unusedFuncs = append(unusedFuncs, result["Name"])
}
}
Once we have this list we iterate over it and find the function start with 2 string.Contains and we iterate over the lines from that point until we find the EndFunc keyword.
// now that we have all of the unused functions, we need to remove them
for i := 0; i < len(lines); i++ {
for , unusedFunc := range unusedFuncs {
if strings.Contains(lines[i], unusedFunc) && strings.Contains(lines[i], “Func”) {
for j, secondLine := range lines[i:] {
if strings.Contains(secondLine, “EndFunc”) {
i = i + j + 1
break
}
}
}
}
modLines = append(modLines, lines[i])
}After running the script against the crypter we have reduced it from 10901 lines to 6195 lines. This function needs to ran a couple of times to catch code branches that do have child function calls but aren’t reachable from the main function. Results will vary from script to script, but I now have a script that only contains used functions, used variables and decrypted strings.
The Final CypherIT Script
These were the high level concepts I used to simplify my CypherIT crypters, the actual script itself will be listed here.
The Bad News
Sadly, even with all of this analysis and development work that made this crypter a lot easier to look at, reconstructing the shellcode itself that will AES decrypt the actual Nanocore sample is out of scope for this project… Luckily the wonderful people over at Unpac.me maintain a incredible service that was actually able to get the payload for me! If you haven’t checked out their service I’d definitely give it a try with some difficult crypters.
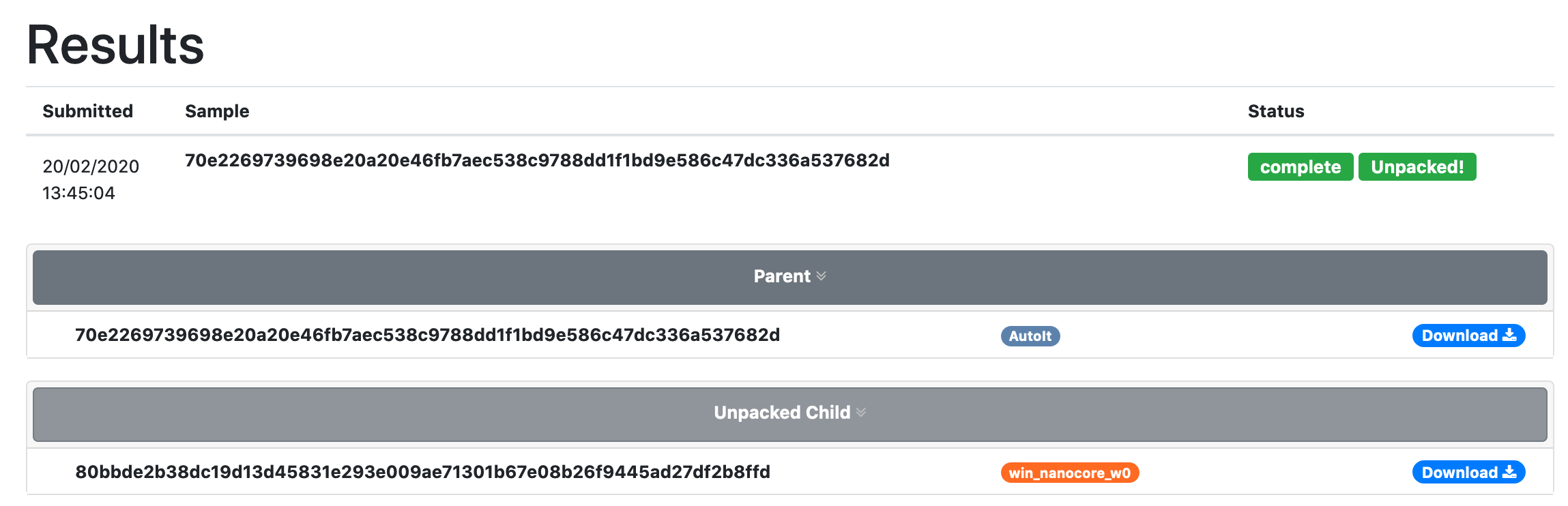
As you can see there is the unpacked Nanocore sample! Onto the actual analysis of the sample.
Nanocore Payload Analysis
So going ahead with the analysis of 80bbde2b38dc19d13d45831e293e009ae71301b67e08b26f9445ad27df2b8ffd, Nanocore is written in .NET so dnSpy will be our tool of choice. Loading it up in dnSpy shows that the internal classes are obfuscated.
One of the first steps I take when I see any sort of obfuscation in .NET malware is run it through de4dot. De4dot is a .NET deobfuscator for many well known .NET obfuscators.
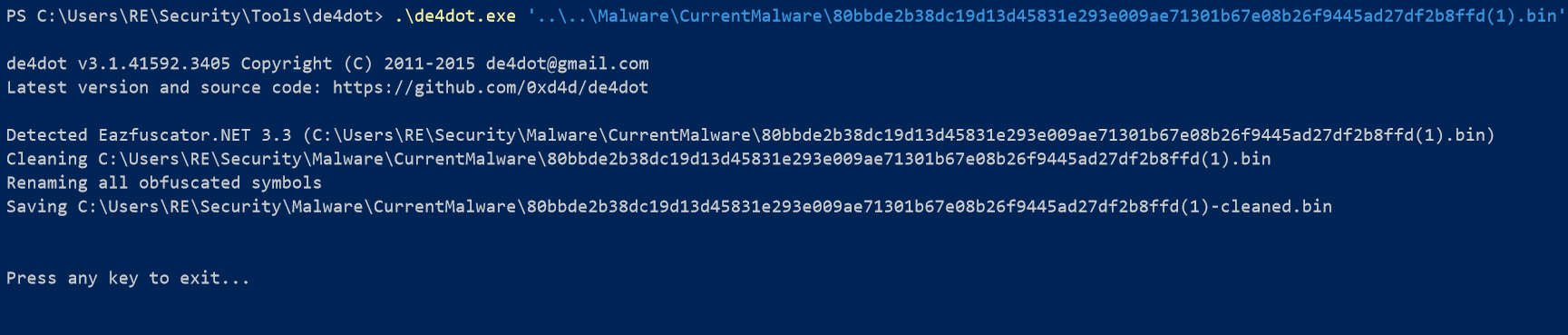
Output shows that de4dot was able to identify the obfuscator used, Eazfuscator. This obfuscator can be found free to use here. Now that we have a cleaned version of the Nanocore sample we are ready to actually analyze it.
Static Config Decryption
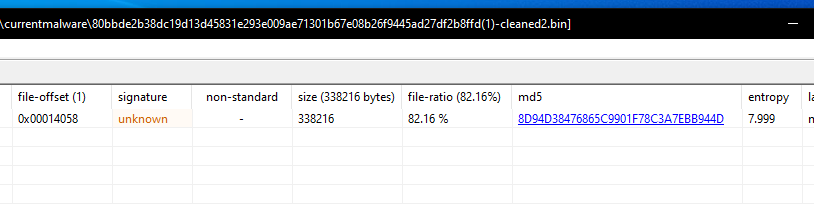
Looking at PE Studio results though there is yet another encrypted resource that we need to deal with.
Searching for function calls within our .NET application that handle resources leads us to the following
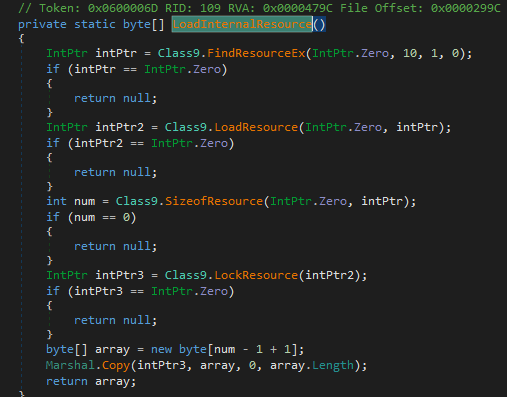
Pretty standard loading of a resource and checking the xrefs to this function we find
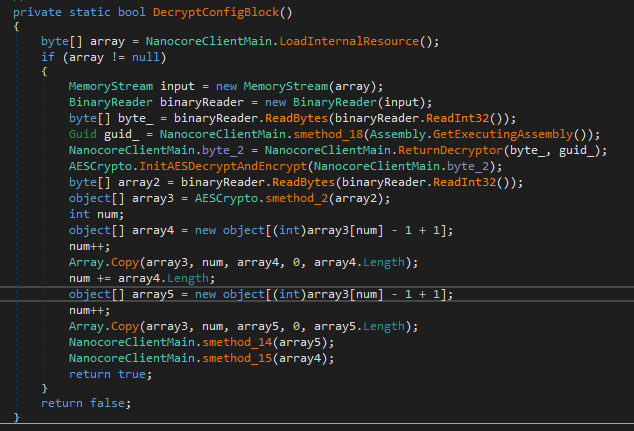
Now we are at the the point where we can recreate this code assuming that its going to decrypt the encrypted resource. As you can already see I’ve annotated a lot of the code already to make this blog post a tad shorter.
byte[] byte = binaryReader.ReadBytes(binaryReader.ReadInt32());This is the first line that we have to pay attention to. This line will read a 32bit integer from the encrypted resource. Then get the GUID of the .NET application and pass it to a function that is going to return a Decryptor object for us

This function starts off initializing a Rfc2898DeriveBytes object with the GUID as the password and the salt. That will return a Key and IV that is then used in Rijndael in CBC mode to create the next piece in this chain. This function will decrypt the first 8 bytes on the resource and pass that back. Immediately after the 8 bytes is returned, its passed to this function below where a DES decryptor is created. These 8 bytes and then used as the Key and IV for the DES decryptor that will decrypt the rest of the contents of the resource.
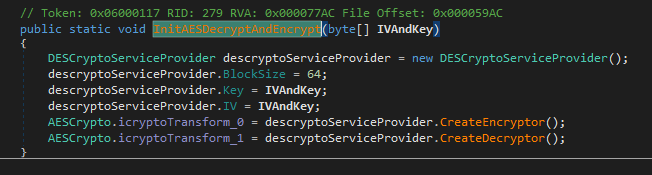
After this function is called, all we have is a initialized decryptor, and our content is still encrypted. Although a couple lines after our init function this function below is called.
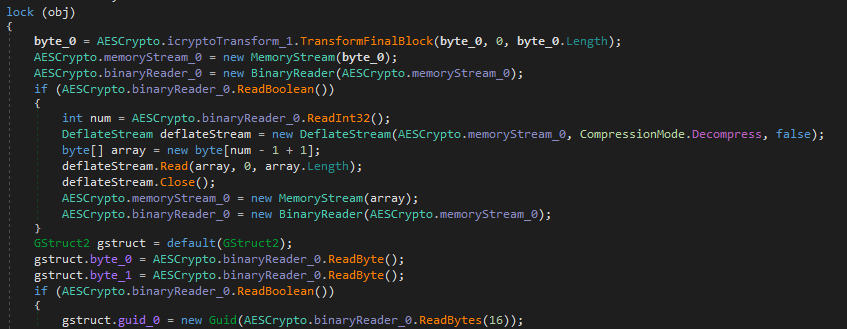
byte_0 = AESCrypto.icryptoTransform_1.TransformFinalBlock(byte_0, 0, byte_0.Length);This line will decrypt all the contents. Now as soon as that’s finished a boolean is read from the start of the decrypted contents. If the boolean is true, the rest of the contents has to be zlib decompressed. In total this breaks down to the following python code to re-implement. Now the GUID has to be changed and since I was working with a single sample I didn’t write any code to handle the boolean being read to decompress or not, so that will have to be modified as well.
def decrypt_config(coded_config, key):
data = coded_config[24:]
decrypt_key = key[:8]
cipher = DES.new(decrypt_key, DES.MODE_CBC, decrypt_key)
raw_config = cipher.decrypt(data)
new_data = raw_config[5:]
decompressed_config = zlib.decompress(new_data, -15)
return decompressed_config
def derive_pbkdf2(key, salt, iv_length, key_length, iterations):
generator = PBKDF2(key, salt, iterations)
derived_iv = generator.read(iv_length)
derived_key = generator.read(key_length)
return derived_iv, derived_key
get guid of binary
guid_str = ‘a60da4cd-c8b2-44b8-8f62-b12ca6e1251a’
guid = uuid.UUID(guid_str).bytes_le
AES encrypted key
encrypted_key = raw_config_data[4:20]
rfc2898 derive IV and key
div, dkey = derive_pbkdf2(guid, guid, 16, 16, 8)
init new rijndael cipher
rjn = new(dkey, MODE_CBC, div, blocksize=len(encrypted_key))
decrypt the config encryption key
final_key = rjn.decrypt(encrypted_key)
decrypt the config
decrypted_conf = decrypt_config(raw_config_data, final_key)
Loading the decrypted contents in a hex editor does show in fact that we have a valid decrypted blob.
This blob contains various PE files being the plugins loaded as well as standard config information below
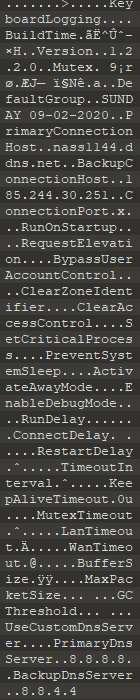
Config Parsing
Now that our config blob is properly decrypted, we need to parse it. Running binwalk on our output contents shows some interesting results.
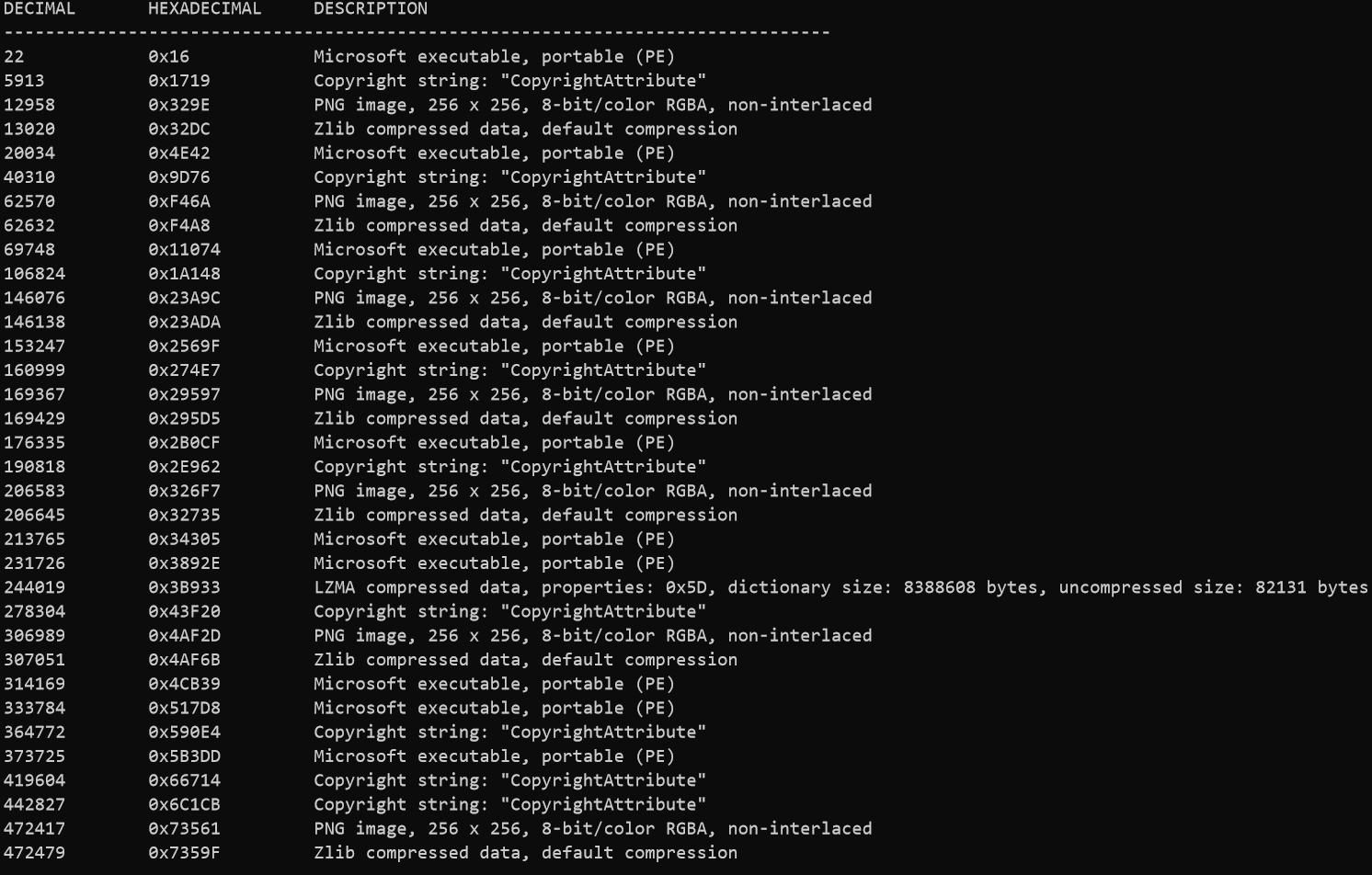
In between the zlib compressed contents and the PNGs there are valid PE files. Now Nanocore is a modular RAT as I had mentioned earlier. These PE files are the plugins that are loaded immediately after config decryption. With the following snippet I was able to dump each individual PE file that Nanocore is going to load.
plugins = decrypted_conf.split("\x00\x00\x4D\x5A")
remove first snippet as its junk code
plugins = plugins[1:]
Add the MZ header back cuz python is hard
remove the config struct at the end of the file
while i < len(plugins):
plugins[i] = ‘\x4D\x5A’ + plugins[i]
if “\x07\x3E\x00\x00\x00” in plugins[i] and i == len(plugins)-1:
plugins[i] = plugins[i].split("\x07\x3E\x00\x00\x00")[0]
i += 1
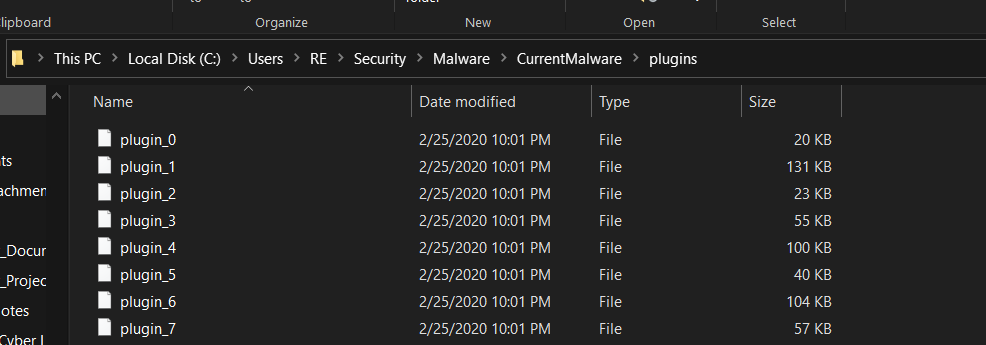
Here we iterate over the config blob that’s split by 2 null bytes and the MZ header. With Nanocore’s config being at the end of the file that means the last element in our list from the split is going to contain the config data when it shouldn’t. The config data itself starts with 0x07 0x3E followed by 3 null bytes. Splitting on that when we’re at the last plugin and selecting the first element keeps the last plugin intact. Once they are split and dumped to a directory we get 8 plugins to analyze.
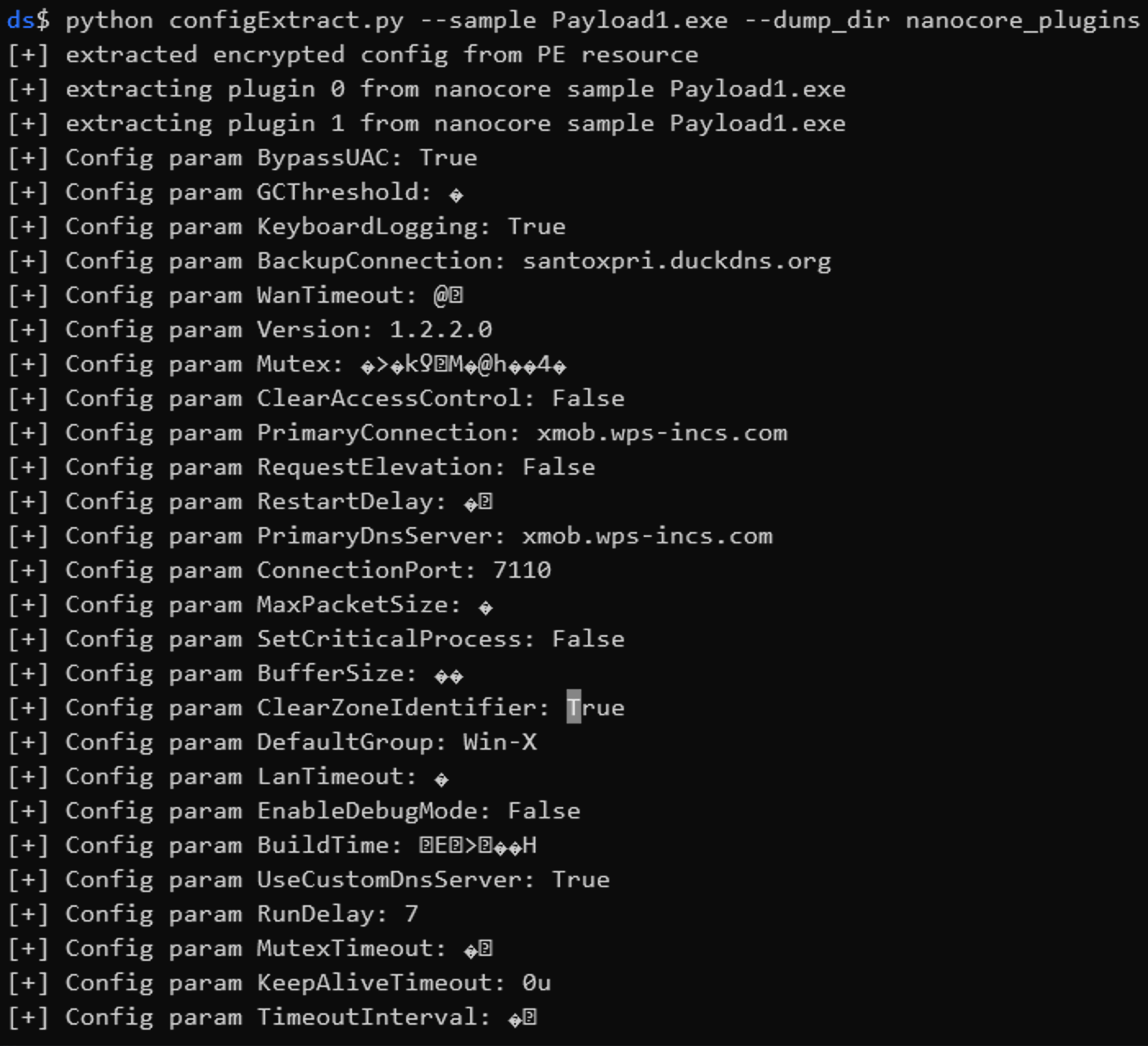
For the config values of the sample, each field starts with a 0x0c, a null byte, the field name, another null byte then the value of the field name. In the script I search for the hardcoded field names in this specific format.
logging_rule = re.search("\x0c.KeyboardLogging(?P<logging>.*?)\x0c", decrypted_conf)
logging = logging_rule.group(‘logging’)
if ord(logging[1]):
config_dict[‘KeyboardLogging’] = True
else:
config_dict[‘KeyboardLogging’] = FalseAfter doing this for each configuration field of the sample we can get a clear picture of this sample.
Some of the fields aren’t parsed properly but that is mainly due to lack of time. The values are all correct they just need to be interpreted correctly.
Nanocore as malware is pretty straightforward to analyze and hasn’t changed much so I’ll be skipping the analysis of the plugins. If there is demand I can write a follow up on the plugins as well as flaws within Nanocore’s network comms.
In an effort to keep this post short, I’m going to end the analysis here but there is more work to be done on Nanocore and the CypherIT crypter. If anyone would like to collaborate and make a true unpacker for CypherIT, please reach out.
Article Link: https://malwareindepth.com/defeating-nanocore-and-cypherit/