A mini-guide about MicroService design for Data Pipeline: Part II
 Photo credit: Pixabay
Photo credit: PixabayIn Part I, Modularization Using Python and Docker for Data Pipeline, I presented a framework on how to use Docker to adopt the data pipeline. If you haven’t read it yet, please follow the link above.
Using serverless to reduce the cost and improve the scale for the whole pipeline framework is important to understand these days. So, how do we adopt serverless cluster or Dataproc into our Python data pipeline framework?
In this blog, I will present a new Graph-Style Serverless Pipeline Framework for Python. It can be used in both data engineering and machine learning engineering.
Agenda
- Challenges
- Serverless
- Graph-Style Serverless Pipeline Framework
- Example
- Summary
Challenges
- Adopting the serverless process like DataProc
- Reduce the programming effect — Just need to focus on the logic
- Making the pipeline clearer for data lineage?
- Making the code more readable?
Serverless
Serverless is a cloud-native development model that allows developers to build and run applications without having to manage servers.
Graph Style Serverless Pipeline Framework
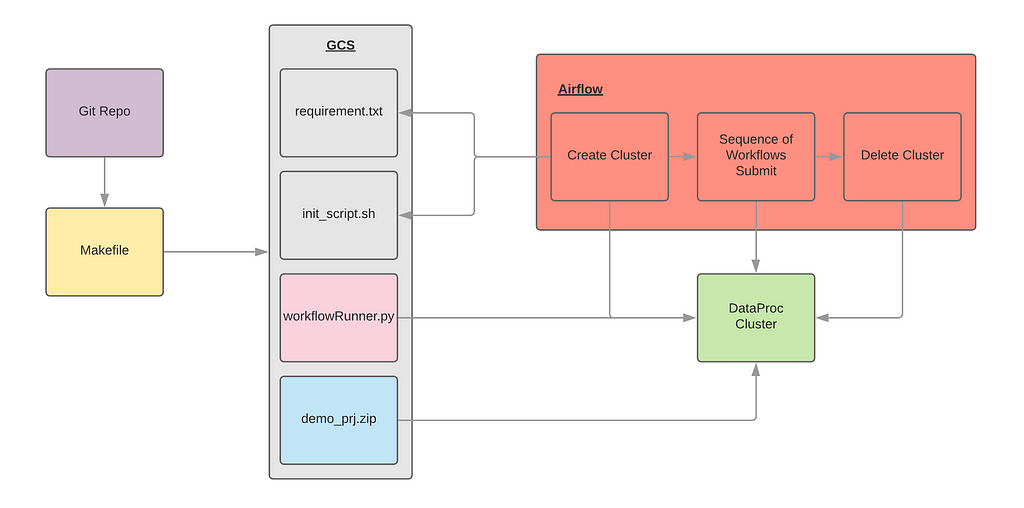 Figure 1. Infrastructure
Figure 1. InfrastructureTo adopt the serverless process, we need to design a new framework for the Python version. Let’s deep dive into each component in Figure 1.
- Makefile / Looper: We use Makefile and looper to do the CICD process from GitHub.
- requirement.txt / init_script.sh: Those two files are used by airflow create cluster operator to initialize the Dataproc cluster.
- workflowRunner.py / demo_prj.zip: Those two files are used by airflow submit operator to initialize the workflow.
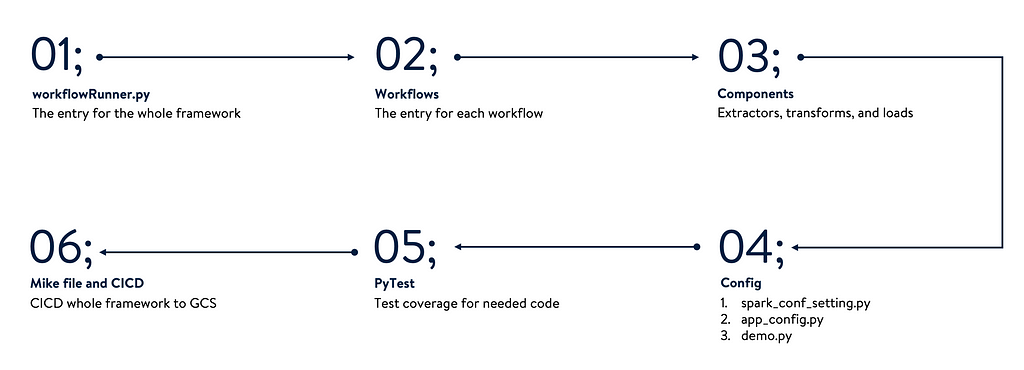 Figure 2. Framework Process
Figure 2. Framework ProcessFor batch pipeline, this approach can meet most of the requirements for serverless.
In Figure 2, outlines each step to be followed. We will deep dive into most of them in the example section.
Another advantage of this framework is the graph-style pipeline. For most of the framework, it has a DAG style, but is just applied at the first level (upper level). For example, in Figure 3, most frameworks treat Extractor Runner, Transformer 1 Runner, Transformer 2 Runner and Loader Runner as nodes in the whole DAG. However, for the deeper level, they just put the code line by line or many functions together to make that component works. In our new design, we treat both horizontal and vertical levels into nodes like Figure 3 as a graph. We will see more examples under the example section.
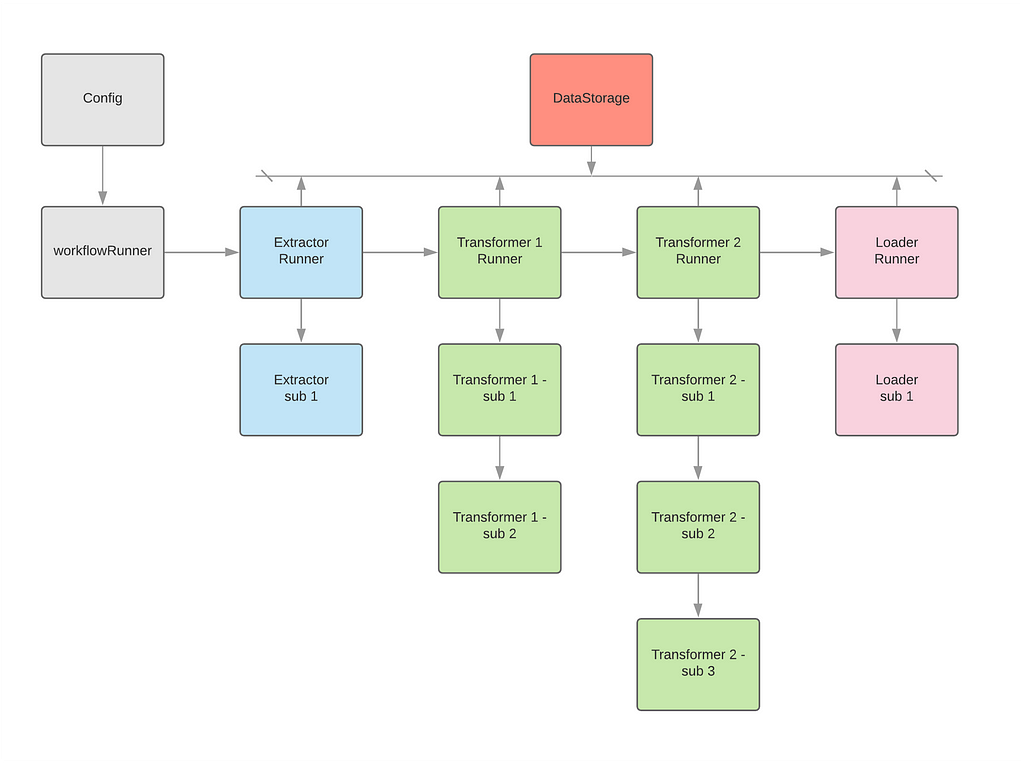 Figure 3. Framework Process — Graph Style
Figure 3. Framework Process — Graph StyleIn Figure 4, we can find the benefits if we use this new design.
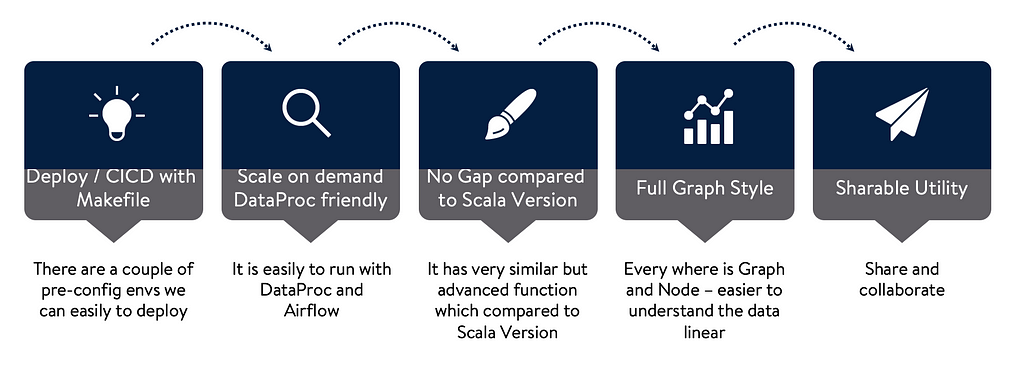 Figure 4. Benefits
Figure 4. BenefitsExample
In this example, I will go through the code part which has been discussed in Figure 2. This ETL process is reading CSV, deduplicating data, and generating the aggregation.
1. Entry of Framework
workflowRunner.py is the entry point for our framework. It defines each workflow and initializes the spark which can be shared for the whole framework.
<a href="https://medium.com/media/816bd33ba66727ddab083ba5d9dd228d/href">https://medium.com/media/816bd33ba66727ddab083ba5d9dd228d/href</a>2. Workflows
This is one of workflow, the main function is run() and all others’ functions are linked together using a decorator. In this approach, it is easy to understand the data lineage by the code itself.
3. Components/Extractors, Transformers, Loaders
All other components such as extractors, transformers, and loaders have the same logic as workflows. We use df_storage to store all variables which need to be shared among the components.
4. CICD
We use Makefile to zip all needed code and looper to do CICD. gcp_pip_install.sh is to be used to install all needed packages under the cluster.
<a href="https://medium.com/media/9cb6f9f3b0e053f39215d6e80b2526f0/href">https://medium.com/media/9cb6f9f3b0e053f39215d6e80b2526f0/href</a><a href="https://medium.com/media/10bb7655df3029e3bd94f63dca0cefd5/href">https://medium.com/media/10bb7655df3029e3bd94f63dca0cefd5/href</a>Summary
This is another good solution for MicroService design for Serverless Data Pipeline.
Modularization Using Graph-Style Serverless Pipeline Framework was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.