Why do we need Versioning?
Tim is a data scientist, he works around analysing data and crunching numbers. Back in the days, he had smaller datasets to look into which were manageable in folders.
 Tim analyzing data in 2015
Tim analyzing data in 2015In the era, where applications of ML have become multifold, touching domains like Retail, Healthcare, Supply-Chain, etc. it brought with it a plethora of different complications with data and usecases involving experimentation. Now it becomes difficult for Tim to keep track of multiple results and experiments.
 Tim compiling results in 2022
Tim compiling results in 2022Enter MLOps, as a saviour for data scientists and machine learning engineers. To enable them to focus on insights while taking care of all the result compilation in a jiffy. We’ll focus on MLflow and DVC as tools for versioning our models and data.
Introduction
Version control helps tracking changes in the environment. In ML, the process includes data, experimentation, analytical reports, model tuning and much more. Keeping these components in mind, MLOps comes into play as a tool which consists of a set of practices for collaboration and communication between data scientists and machine learning engineers to track experiments with respect to data, models, and results.
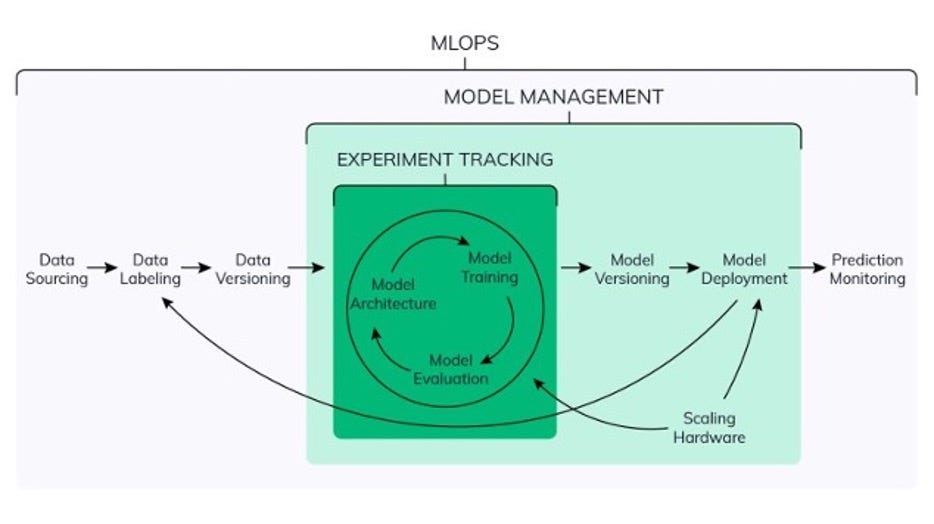 Fig. 1: MLOPS — Processes and Flow
Fig. 1: MLOPS — Processes and FlowData Science Lifecycle
The DS lifecycle is driven by business objectives which provide input from a real world scenario to produce insights and patterns to understand the given system.
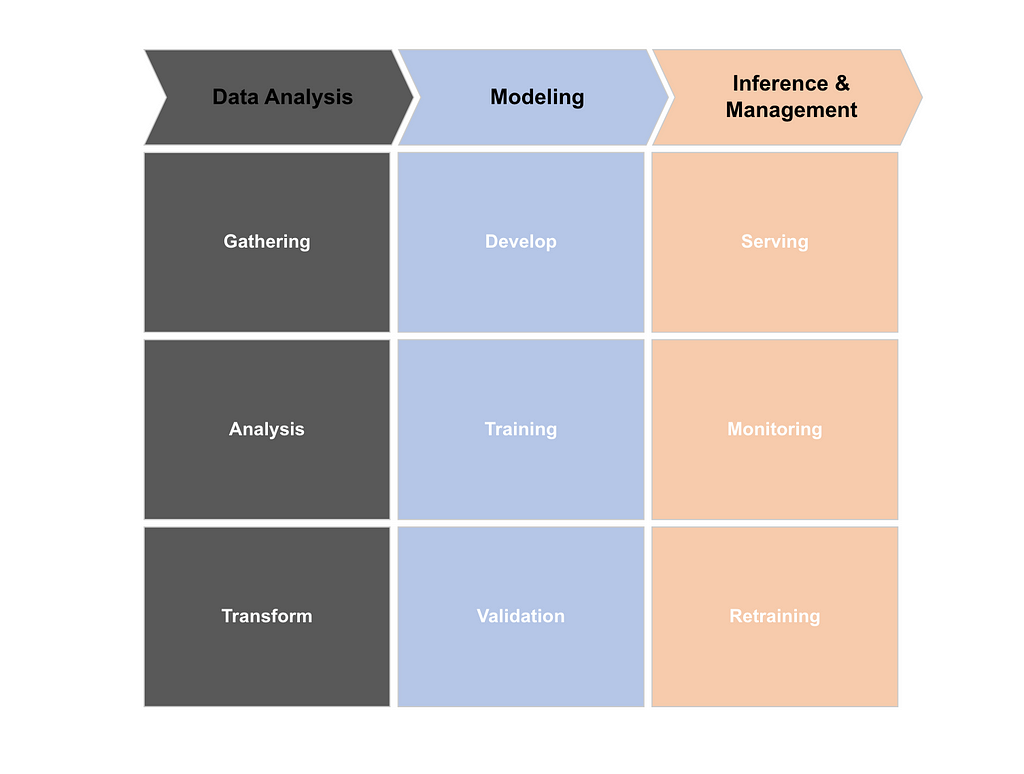 Data Science Lifecycle
Data Science LifecycleModel management is a part of MLOps. ML models should be consistent and meet all business requirements at scale. To make this happen, a logical, easy-to-follow policy for model management is essential.
Common components of ML Model Management workflow:
- Data Versioning: Version control systems help developers manage changes to source code. While data version control is a set of tools and processes that tries to adapt the version control process to the data world to manage the changes of models in relationship to datasets and vice-versa.
- Code Versioning/Notebook checkpointing: It is used to manage changes to the model’s source code.
- Experiment Tracker: It is used for collecting, organizing, and tracking model training/validation information/performance across multiple runs with different configurations (lr, epochs, optimizers, loss, batch size and so on) and datasets (train/val splits and transforms).
- Model Registry: Is simply a centralized tracking system for trained, staged, and deployed ML models
- Model Monitoring: It is used to track the models inference performance and identify any signs of Serving Skew which is when data changes cause the deployed model performance to degrade below the score/accuracy it displayed in the training environment
Tools and Techniques
There are many tools which can be used for Model Versioning and Storing, including the following:
- MLFlow
- GIT & DVC
- Neptune AI
- Pachyderm
- Modzy
MLFlow
MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. The MLflow Tracking component is an API and UI for logging parameters, code versions, metrics, and output files when running your machine learning code and for later visualizing the results. MLflow Tracking lets you log and query experiments using Python, REST, R API, and Java APIs.
Sample Code for tracking models
import mlflow ## Import MLFlow
import mlflow.sklearn ## Import specific models within MLFlow
import pandas as pd
data = pd.read_csv(csv_url, sep=';')
train, test = train_test_split(data)
mlflow.set_experiment("MLflow Demo") with mlflow.start_run(): ## Use this to start logging
model = """<Any Model of Choice>"""
model.fit(train_x, train_y)
predicted_y = model.predict(test_x)
rmse, mae, r2 = eval_metrics(test_y, predicted_qualities)
mlflow.log_param("A", hyper_parameter1)
mlflow.log_param("B", hyper_parameter2)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.sklearn.log_model(model, "model")
MLflow Model Registry
The mlflow Model Registry component is a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of an MLflow Model. It provides model lineage (which MLflow experiment and run produced the model), model versioning, stage transitions (for example from staging to production), and annotations.
- Registered Model: An MLflow Model can be registered with the Model Registry. A registered model has a unique name, contains versions, associated transitional stages, model lineage, and other metadata.
- Model Versioning: Each registered model can have one or many versions. When a new model is added to the Model Registry, it is added as version 1. Each new model registered to the same model name increments the version number.
- Model Stages: ach distinct model version can be assigned one stage at any given time. MLflow provides predefined stages for common use-cases such as Staging, Production or Archived. You can transition a model version from one stage to another stage.
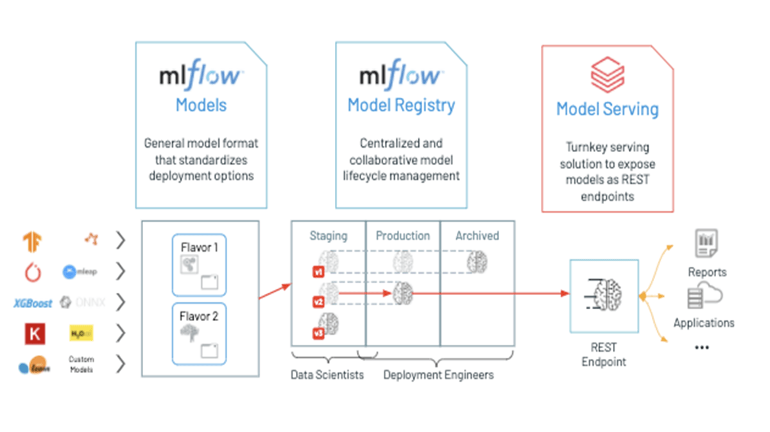 Mlflow Experiment Tracker and Registry
Mlflow Experiment Tracker and Registry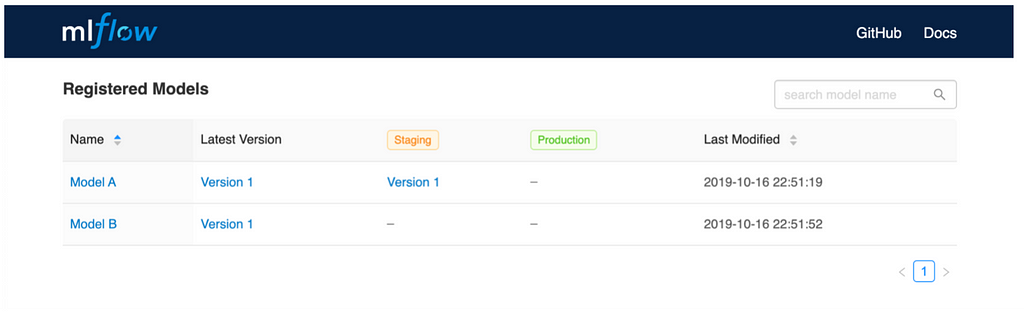 List of registered models with environment
List of registered models with environment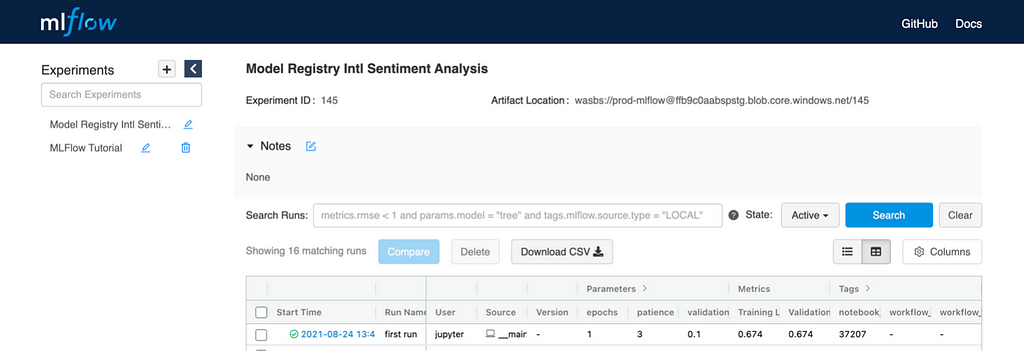 Accessing experiments for different runs
Accessing experiments for different runsAdding an MLflow Model to the Model Registry
Option 1: use the mlflow.<model_flavor>.log_model() method.
import mlflow
import mlflow.sklearn
mlflow.set_experiment("Model Registry")m1 = 0.7
m2 = 0.8
with mlflow.start_run(run_name="first model run") as run:
params = {"parameter1": 1, "parameter2": 2}
sk_learn_model = """<Model of choice>(**params)"""
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_param("param_1", randint(0, 100))
mlflow.log_metrics({"metric_1": m1, "metric_2": m2})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(sk_model=sk_learn_model,
artifact_path="model",
registered_model_name="ModelOfChoice")
In the above code snippet, if a registered model with the name doesn’t exist, the method registers a new model and creates Version 1. If a registered model with the name exists, the method creates a new model version.
Option 2: Use the mlflow.register_model() after all our experiment runs complete and when you have decided which model is most suitable to add to the registry. For this method, we will need the run_id as part of the runs:URI argument.
result = mlflow.register_model("runs:/<run_id>/<path>", "model")If a registered model with the name doesn’t exist, the method registers a new model, creates Version 1, and returns a Model Version MLFlow object. If a registered model with the name exists, the method creates a new model version and returns the version object.
Option 3: We can use the create_registered_model() to create a new registered model. If the model’s name exists, this method will throw an MlflowException because creating a new registered model requires a unique name.
from mlflow.tracking import MlflowClient
client = MlflowClient()
"""Creates an empty registered model with no version associated"""
client.create_registered_model("model-of-choice ")
"""create a new version of the model"""
result = client.create_model_version(name="model",
source="mlruns/0/<path>",
run_id="<run_id>")
"""Renaming a Registered model"""
client.rename_registered_model(name="<old_model>",
new_name="<new_model>")
"""Promoting a model to Production stage"""
client.transition_model_version_stage(name="<model>",
version=2,
stage="Production")
"""Archive an old version of model"""
client.transition_model_version_stage(name="<model>",
version=3,
stage="Archived")
"""Deleting Model Version & Complete Model"""
client.delete_model_version(name="<model>", version=3)
client.delete_registered_model(name="<model>")
The above codes will be required during model training and saving the model.
Model Prediction and Scoring Pipeline
After we have registered an MLflow model, we can fetch that model using mlflow.<model_flavor>.load_model(), or more generally, load_model().
"""Loading specific version of model"""
import mlflow.pyfunc
model_name = "<model-of-choice>"
stage = 'Staging'
model_uri = f"models:/{model_name}/{stage}"
model = mlflow.pyfunc.load_model(model_uri=model_uri)
model.predict(data)
"""Loading specific type of models like sklearn"""
mlflow.sklearn.load_model("models:/<model>/<version>")
"""Loading Latest Production Version of model"""
import mlflow.pyfunc
model_name = "<model-of-choice>"
stage = 'Production'
model_uri = f"models:/{model_name}/{stage}"
model = mlflow.pyfunc.load_model(model_uri=model_uri)
model.predict(data)The latency while loading a model stored in MLFlow registry for prediction/scoring is very low. Following is a benchmark of time taken to Load a Keras model from MLFlow registry vs. time taken to load the same model from local storage.
%%time
model = mlflow.keras.load_model("models",custom_objects={'KerasLayer':hub.KerasLayer})
# CPU times: user 10.6 s, sys: 1.18 s, total: 11.7 s
# Wall time: 17 s
%%time
model = tf.keras.models.load_model('models')
# CPU times: user 18.6 s, sys: 138 ms, total: 18.8 s
# Wall time: 21.8 spy
In conclusion, it is faster to load a model from MLFlow registry than a locally saved version of the same model.
Serving an MLflow Model from Model Registry
After we have registered an MLflow model, we can serve the model as a service on our host.
#!/usr/bin/env sh
# Set environment variable for the tracking URL where the Model Registry resides
export MLFLOW_TRACKING_URI=http://localhost:5000
# Serve the production model from the model registry
mlflow models serve -m "models:/<model-of-choice>/Production"
# Logging the model
mlflow.sklearn.log_model(lr, "model")
An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools — for example, real-time serving through a REST API or batch inference on Apache Spark.
In the example training code, after training the linear regression model, a function in MLflow saved the model as an artifact within the run.
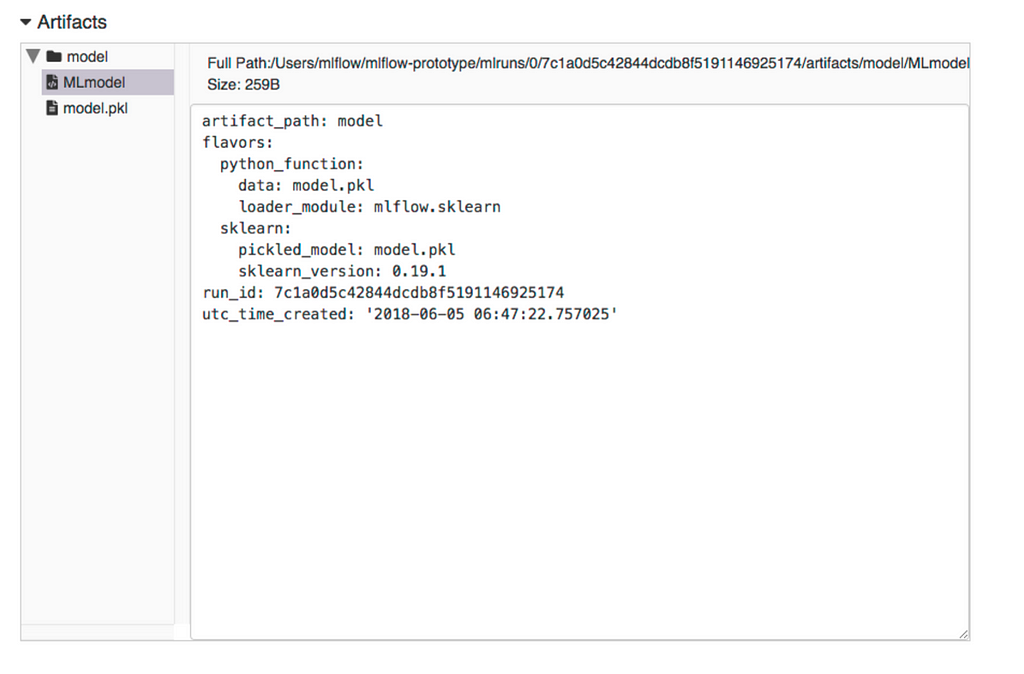 Model saved as an artifact
Model saved as an artifactmlflow.sklearn.log_model produced two files in path, which are:
# log path
/Users/mlflow/mlflow-prototype/mlruns/0/7c1a0d5c42844dcdb8f5191146925174/artifacts/model
- MLmodel — is a metadata file that tells MLflow how to load the model
- model.pkl — a serialized version of the model we trained
To deploy the server, run (replace the path with your model’s actual path):
mlflow models serve -m /Users/mlflow/mlflow-prototype/mlruns/0/7c1a0d5c42844dcdb8f5191146925174/artifacts/model -p 1234
Note: The version of Python used to create the model must be the same as the one running mlflow models serve
Once we have deployed the server, we can pass it some sample data and see the predictions. The following example uses curl to send a JSON-serialized pandas DataFrame with the split orientation to the model server
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"],"data":[[12.8, 0.029, 0.48, 0.98, 6.2, 29, 3.33, 1.2, 0.39, 75, 0.66]]}' http://127.0.0.1:1234/invocationsA comparison of potential Pros/Cons of using MLFlow is shown below:
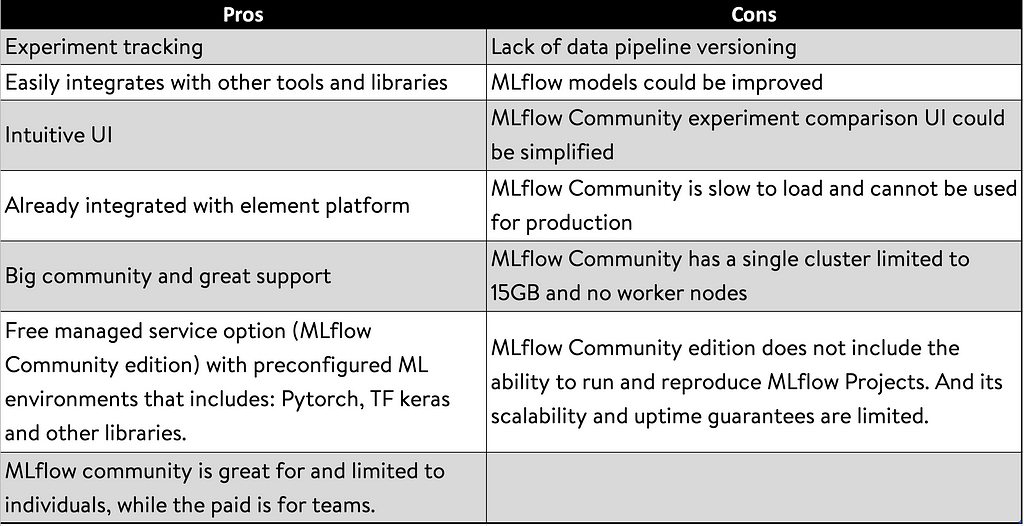 MLFlow Pros & Cons
MLFlow Pros & ConsPS: element is Walmart’s in-house platform for Machine Learning & Analytics
DVC
Data Version Control, or DVC, is a data and ML experiment management tool that takes advantage of the existing engineering toolset like Git, CI/CD, etc. Just like Git is for our code, DVC is for our data & model.
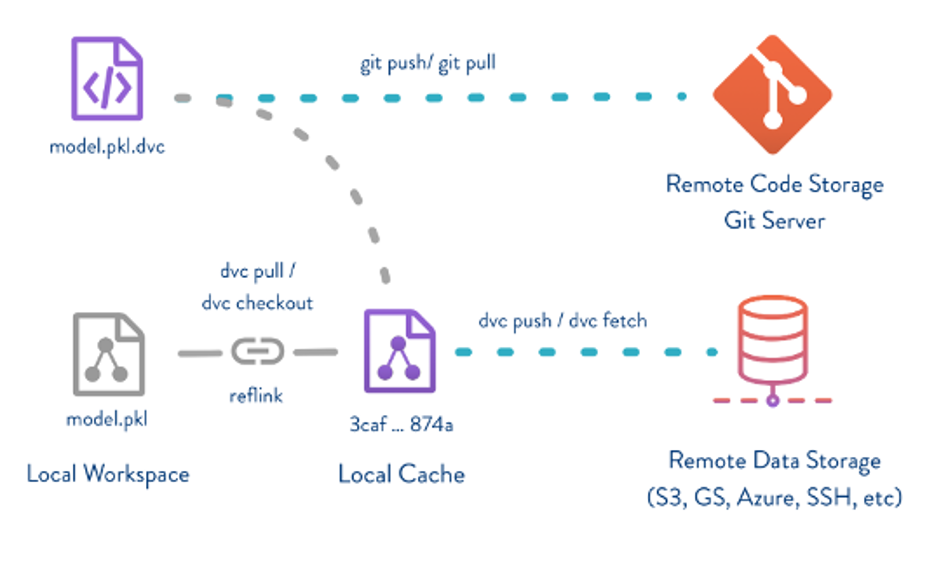 DVC flow — https://github.com/iterative/dvc
DVC flow — https://github.com/iterative/dvcThe solution includes two layers of version control:
- git: handles code and metadata (of dataset and model artifact)
- dvc: handles large dataset and model artifact
Installing DVC
DVC can be installed via pip or conda as below
pip install dvc # Vanilla installation
pip install dvc[azure] # If remote-storage is azure blob
pip install dvc[hdfs] # If remote-storage is hadoop
OR
conda install -c conda-forge mamba
mamba install -c conda-forge dvc
Since DVC also utilizes a remote storage, we can install dvc for specific storage system — i.e., Azure Blob Storage, Amazon S3 or GCP Bucket (here).
Steps to integrate DVC
Suppose we train a model and we want to track it via DVC, we can follow the steps below:
- Step 1: add model metadata to dvc
dvc add model.h5
We use the above to start tracking the model. It can be observed that the “real” model is stored under .dvc/cache/<> model metadata model.h5.dvc records where it is.
- Step 2: persist model by pushing it to backend storage
dvc push model.h5.dvc
- Step 3: persist model metadata with git
It is the model metadata that can lead us to the real model object which is stored in backend storage. To prevent from losing the metadata, it should be added to version control using git.
git add .gitignore model.h5.dvc data.dvc metrics.json
git commit -m "model first version"
git tag -a "v1.0" -m "model v1.0"
“git tag” can be used here to record version of the model.
- Step 4: access the model anytime
It is easy to fetch a specific version of the model by searching for the tag on git branch. From git we can check out the model metadata.
git checkout tags/<tag_name> -b <branch_name>
Following the metadata we can find the model object and download it into current workspace with command
dvc pull model.h5.dvc
For more details, please refer to the tutorial videos at https://dvc.org/doc/start/data-and-model-versioning, and a detailed User Guide at https://dvc.org/doc/user-guide
Data Versioning with DVC
We initialize DVC after git init using dvc init
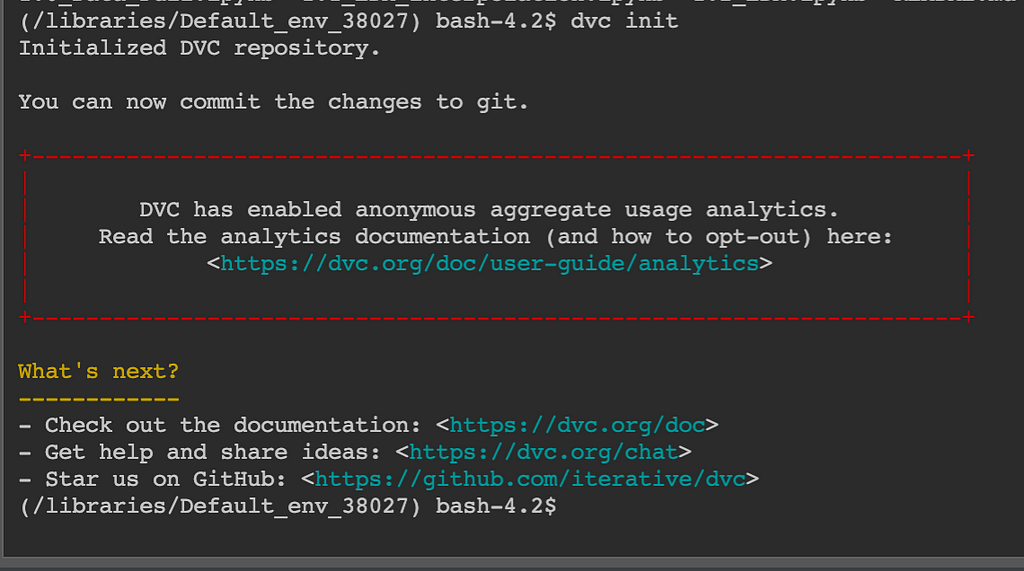 Initializing a DVC repo in local
Initializing a DVC repo in localWe create dummy dataset (in this case Iris) and start tracking it
 Track data folder containing data.csv
Track data folder containing data.csvA data.dvc file is created which we track via git
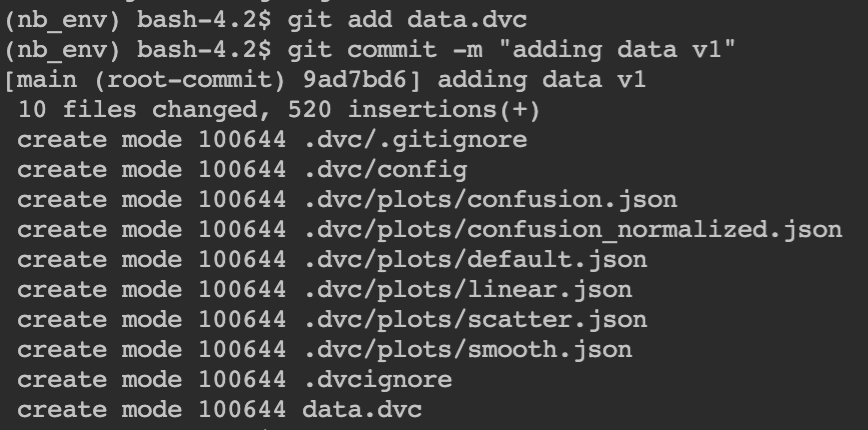 Track data.dvc metadata file
Track data.dvc metadata fileChecking logs — we can use specific commits in git to go back and forth to a specific checkpoint and fetch the relevant data.
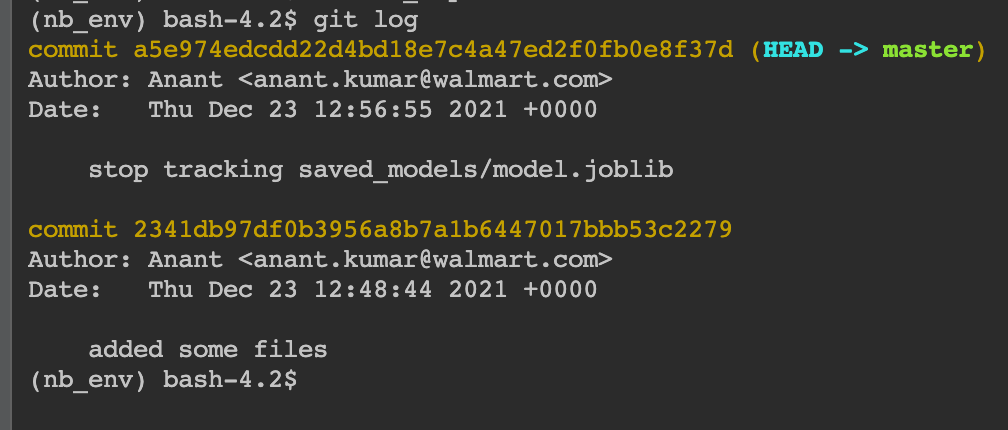 Checking logs to find our latest commit
Checking logs to find our latest commitHence, we can continue to overwrite data.csv without the hassle of creating data1.csv, data2.csv, data_final_final.csv and keep track of all datasets together and streamline our experimentation.
Challenges with Data Versioning
- Refreshing Cache
It creates a copy of the entire data versions and stores it in .dvc/cache folder. The size of the folder will keep on expanding depending on the commit history of git.
Solution: We can set a commit history limit e.g., keep the top n commits and delete the rest. We will discuss this in detail in our next article.
Conclusion
In this article we learnt about MLFlow and DVC as tools of implementing MLOPS in our projects. In continuation, we’ll be releasing more interesting implementations of topics concerning MLOPs.
Please feel free to reach out to us in the comments for future articles and suggestions.
Authors: Anant Kumar | Somedip Karmakar
References
- Data Version Control · DVC
- A Comprehensive Guide to Data Versioning: Benefits & Formats
- MLflow - A platform for the machine learning lifecycle
Model and Data Versioning: An Introduction to mlflow and DVC was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Model and Data Versioning: An Introduction to mlflow and DVC | by Anant Kumar | Walmart Global Tech Blog | Medium