1st in series : In Context Learning
 Source: midjourneyai.ai
Source: midjourneyai.aiThe introduction of chat GPT has sparked a significant increase in curiosity surrounding the inner workings of LLMs. These language models have captivated people with their ability to handle diverse tasks, ranging from simple math problem solving to creative endeavours like composing poems and songs, and even delving into profound philosophical inquiries. It’s a truly remarkable phenomenon! while researchers still have limited understanding of the underlying mechanisms behind LLMs,
the CEO of Google draws an interesting analogy, stating that just as we cannot fully comprehend the intricacies of the human brain, it still functions brilliantly. In a similar vein, the focus lies on uncovering the most effective methods to optimize LLM performance.
In this series of blog, we’ll explore the process of making LLMs work for specific use cases. While LLMs are excellent generalizers and even in understanding context ‘in-general’, they might not always provide optimal results for very specific queries. For example, Search data from E-Commerce sites can be quite noisy and difficult to categorize. It can stretch the context beyond general understanding. Like search for “iPhone back cover” can also be referred as “skin” might also include search terms like “eyephone red skins,” “iPhone covers,” or “iPhone cool covers”. Further search can be very nuanced and narrowing it to specific keywords and relevance among them can get muddier when using any base LLM. To accurately attribute each search keyword to a particular feature like product, product type, or style, LLMs require fine-tuning. We will limit the scope of this first blog in the series to understanding the essential concepts to fine-tuning and in-context learning (ICL).
Fine-tuning is common concept associated with transfer learning in ML. Before going further let’s get clarity on some commonly used and usually misunderstood terminologies.
Transfer learning — This involves taking a pre-trained model on a large dataset and adapting it to a specific task or domain by fine-tuning its parameters on a smaller, task-specific dataset.
Pre-training — The training process of pre-trained model (like BERT or any other LLM) is called pre-training. This requires huge compute budget as well as large, curated datasets (which is the key to train good LLMs).
Fine-tuning –The process of adjusting the weights and biases of a pre-trained model by using a smaller dataset that is specific to a particular task while still retaining the valuable features learned during pre-training. This approach enables users to make the model work accurately on a specific task with a limited amount of resources.
However, in the case of LLMs, full parameter fine-tuning can be prohibitively expensive, as there are trillions of parameters involved!
Let’s draw a rough estimate on resources required. Assuming each model weight requires 4 bytes to be stored for FP32 training, the training process requires approximately 20 bytes additional RAM for overhead processes. Since, GPT-3 was trained on 100’s of billion parameters, to fully fine tune this it would require approximately 4200Gb of RAM! Hence, it would be really difficult to fully fine-tune LLMs. There are several workarounds coming up to fine tune LLMs, this is a very active research topic.
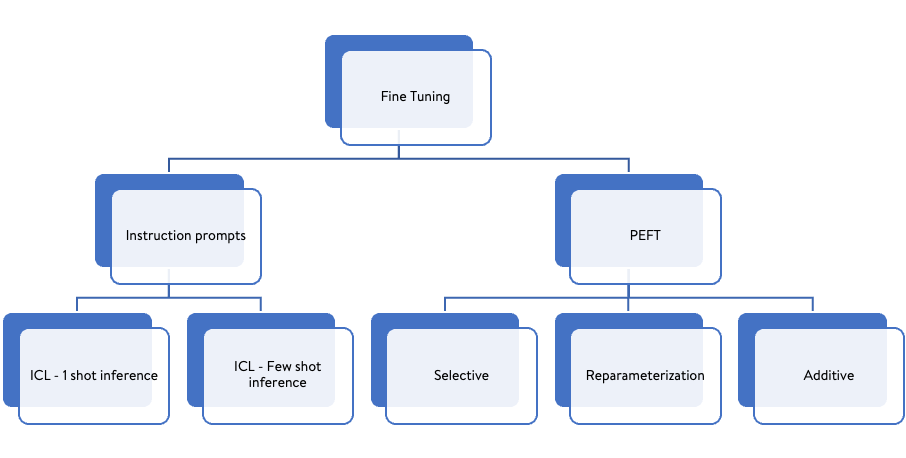 Common Fine tuning techniques (also our blog series scope)
Common Fine tuning techniques (also our blog series scope)Caution: Mostly LLMs are very good generalisers. Only if they are not able to perform well in your task should you consider fine-tuning as it might have some drawbacks, we will discuss them in upcoming blogs.
Extending on the example we discussed above, our primary objective is to identify unfulfilled e-commerce searches in order to enhance our product range based on the popular items customers are actively searching for. Unfulfilled searches are those where customers do not add any items to their cart due to item not available. Once we have identified these unfulfilled searches, our next step is to analyse and categorize their attributes. This categorization will enable us to develop targeted solutions for merchants and search team stakeholders. As it has been determined (Prompt and results are discussed later in the blog) that the current system of recognizing and categorizing these searches using base LLMs is not yielding satisfactory results. Therefore, fine-tuning of the LLM is necessary to improve its effectiveness.
We will start with — Instruction based fine-tuning method In-context learning (ICL)
Before going into that we would like to clear one misleading concept here. Although, we are calling ICL as one of the fine-tuning method but it does not tweak any model weight, no back propagation and no gradient descent! GPT like LLMs which are trained on billions of parameters are showing this mysterious emergent behaviour of being able to learn through context. We don’t yet fully understand how this works, but researches have suggested that LLMs do some kind of Bayesian inference using the prompts. In simple words, using just a few examples, the model is able to figure out the context of the task, and then it makes the prediction using this information.
What is Bayesian inference?
Bayesian inference is a way of updating our beliefs based on new evidence. For example, if we want to know if it will rain tomorrow, we can start with some prior probability based on our knowledge or experience. Say, our prior is probability of rain in a day in October in last 3 years, and then update it based on new information, such as weather forecasts or cloud observations or recently developed depression in Bay of Bengal near Chennai.
In the context of in-context learning, Bayesian inference means that the language model uses the examples in the prompt to infer a latent concept that describes the task. For example, if we give the model some examples of translating English to French, the model will infer that the latent concept is translation and will use its pre-trained knowledge to perform translation for new inputs. The model does not explicitly learn any new parameters or rules, but rather adjusts its internal representations based on the evidence in the prompt.
Apparel search use case with example prompts:
Problem Statement:
Unstructured raw search queries from ecommerce site needs to be structured. Structured query will have clear features with attributions to a specific product and its descriptions which can be utilized as a base to create focussed solutions for merchants, search traffic teams etc,.
Example unstructured search: “Tan coloured women blouse”
Structured search result:
<a href="https://medium.com/media/b6d4eea3fc6a982229ba3214a4e797a5/href">https://medium.com/media/b6d4eea3fc6a982229ba3214a4e797a5/href</a>Steps to solve this using In-Context learning (Prompt Engineering):
We are utilising Chat Bison from Google Vertex AI — chat-bison@001 for solving this use case. With parameters: Temperature — 0.05, Max_token_output — 500, Top P — 0.8, Top K — 20.
Trial 1 — Zero shot learning (Without context)
Zero shot learning means asking LLM to do your specific task without providing any examples.
In here we will try to do the attribution for features — Colour, sleeve, Type, Neck.
Prompt:
Return table containing colour, sleeve, type, neck from ``` womans summer tops with v necks and short sleeves,bodysuits long sleeve boy, sleeveless tops for women, long sleeve cut out workout, open front shrug long sleeve, red t shirts long sleeve 10yrs boy```
Output:
<a href="https://medium.com/media/5995b8849d93c74d7a5bd0f91bac76ae/href">https://medium.com/media/5995b8849d93c74d7a5bd0f91bac76ae/href</a>Clearly, model is hallucinating and creating its own attribution as it predicts colour for all the searches even if no colour is mentioned in the search and likewise on sleeve, type and neck. So, we need to create better prompts.
Trial 2 — Few shot learning (With context)
Few shot learning means asking LLM to do your specific task after providing few examples in your prompt.
Context (to LLM):
We are trying to clean the ecommerce retail searches into a clear set of attributes. For all types of clothing items like shirt, tops, pants, dress etc. Example_input: “Searches — [‘Long Sleeve polo shirts for men’, ‘womens sleevless tops time and tru short sleeve’, ‘copper fit elbow sleeve’,‘3/4 sleeve tees girls 16’puff sleeve dress’,‘womens puff sleeve’]”
Example_output: “Attributes_of -
|Search | Colour | Sleeve | Type | Neck |
| — -| — -| — -| — -| — -| — -|
|Long Sleeve polo shirts for men| Not Applicable | Long | polo shirts | Not Applicable |
|womens sleevless tops time and tru short sleeve| Not Applicable | short | tops | Not Applicable |
|copper fit elbow sleeve| Copper | short | fit | Not Applicable |
|3/4 sleeve tees girls 16| Not Applicable | 3/4 sleeve | tees | Not Applicable |
|puff sleeve dress| Not Applicable | puff | dress | Not Applicable |
|womens puff sleeve| Not Applicable | puff | dress | Not Applicable |
Prompt (to LLM):
Return table containing colour, sleeve, type, neck from [‘womans summer tops with v necks and short sleeves’, ‘bodysuits long sleeve boy’, ‘sleeveless tops for women’, ‘long sleeve cut out workout’, ‘open front shrug long sleeve’, ‘red t shirts long sleeve 10yrs boy’]
Output:
Attributes of -
<a href="https://medium.com/media/afc93ef87fbc6b23a031d801cab70891/href">https://medium.com/media/afc93ef87fbc6b23a031d801cab70891/href</a>Clearly, after providing context with examples attribute segregation is much cleaner and reliable. After some cleaning the output can be saved in tabular format and would be ready for advanced analysis.
In the next blog we will start the discussion on PEFT.
References:
- https://www.standard.co.uk/news/tech/google-ceo-sundar-pichai-understand-ai-chatbot-bard-b1074589.html#:~:text=News%20%7C%20Tech-,Google%20CEO%20Sundar%20Pichai%20admits%20people%20'don't%20fully,understand'%20how%20chatbot%20AI%20works&text=As%20Google%20plans%20the%20further,with%20some%20of%20its%20answers
- https://huggingface.co/docs/transformers/v4.20.1/en/perf_train_gpu_one#anatomy-of-models-memory
- https://ai.stanford.edu/blog/understanding-incontext/#the-mystery-of-in-context-learning
LLM Fine Tuning Series was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: LLM Fine Tuning Series. 1st in series : In Context Learning | by Ishant Sahu | Walmart Global Tech Blog | Medium