Authored and contributed by: Abhimanyu Mitra & Afroza Ali
 Figure 1: How do kids discover their favorite flavor of ice cream? Photo Credit: iStock Photos
Figure 1: How do kids discover their favorite flavor of ice cream? Photo Credit: iStock PhotosMuch like a child choosing a flavor of ice cream, it’s often best to explore a few options before enjoying the best choice. Knowing when to explore options before settling upon the right choice is also key for personalized recommender systems seeking to generate the most relevant items. A robust exploration-exploitation framework helps the personalized recommendation system to balance dual objectives of exploring new products to gain knowledge and maintaining a relevant customer experience in industrial scale systems.
With a large pool of recommendation options available, modeling for each individual customer (using limited engagement feedback) may not be possible, potentially creating a less relevant customer experience. To avoid such optimization delays, relevant customer contexts must be built to leverage patterns. These contexts can be built using customer demographic features, items semantic structures, and shopping behaviors common across time and geographical locations. A new product that has not generated good engagement among a targeted group should be quickly retired from being exposed to that group.
However, contextual explore-exploit models are optimal only to learn and extend expected customer experience at the contextual level and may minimize a customer’s specific needs. Even in a group of customers with similar preferences for content, everyone will not equally like or dislike all the contents.
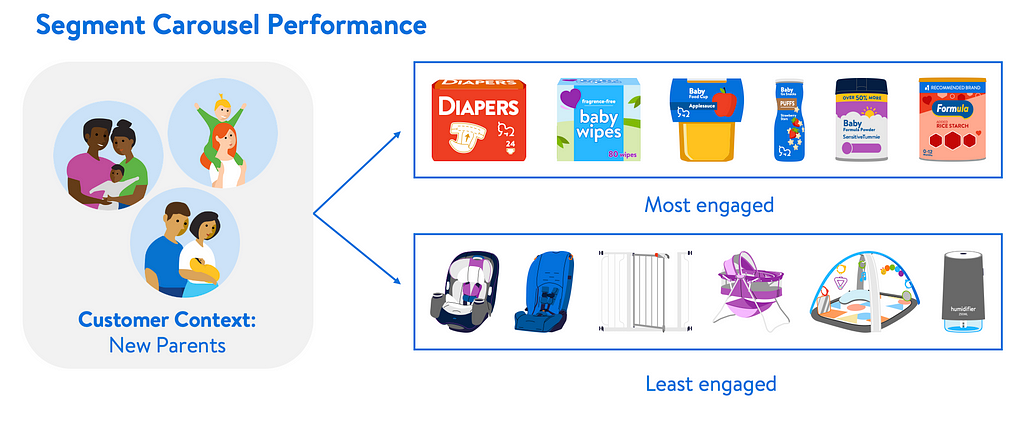 Figure 2: An example of best and worst carousel performance for the customer context of new parents.
Figure 2: An example of best and worst carousel performance for the customer context of new parents.For example, in the customer segment “New Parents,” the top performing carousel contains a variety of recommendations including diapers, baby food, and formula. A sample customer from that segment is the Q family, who has specifically searched for “car seat” and “baby carrier.” Taking their shopping behavior into consideration, carousel that generates less engagement for the context “New Parent” is tailored to the Q family’s taste. Customizing content at greater depths of granularity achieves better relevance.
 Figure 3: Final recommendation ranking is the function of explore-exploit and personalized signals
Figure 3: Final recommendation ranking is the function of explore-exploit and personalized signalsA personalized recommender system must:
- Quickly learn the best performing content for the context
- Consider the nuances in content preference among customers belonging to the same context, thus customizing and personalizing recommendation to the highest degree possible
- Solve the cold start problem by offering some exposure to its huge item space
- Cater to a consistently evolving customer base and content preferences
To achieve these goals, the problem space is factored into two separate models -
- An explore-exploit framework, which figures out broad trends for customer segments while enabling exploration,
- A recommender model trained on historical data to recognize granular customer preferences.
At the final stage, the models are integrated by combining their ranked content pools into one final ranking. This allows for defining independent development cycles in each model, which is also operationally convenient.
This post discusses a broad overview of the explore-exploit platform architecture, its integration with the recommender model trained on historical data and the challenges in quantifying the impacts.
Overall Architecture:
On high-level the integrated backend architecture contains 3 main sub-systems:
1) Explore-exploit modeling framework,
2) Content generators, consisting of (sub-)category specific curated recommendation sets and content pieces, as well as output of other offline ranking models, ads ranker output, deals set, etc., and,
3) Serving layer, which hosts the models and real-time ranking functions to serve the most relevant recommendations for each request.
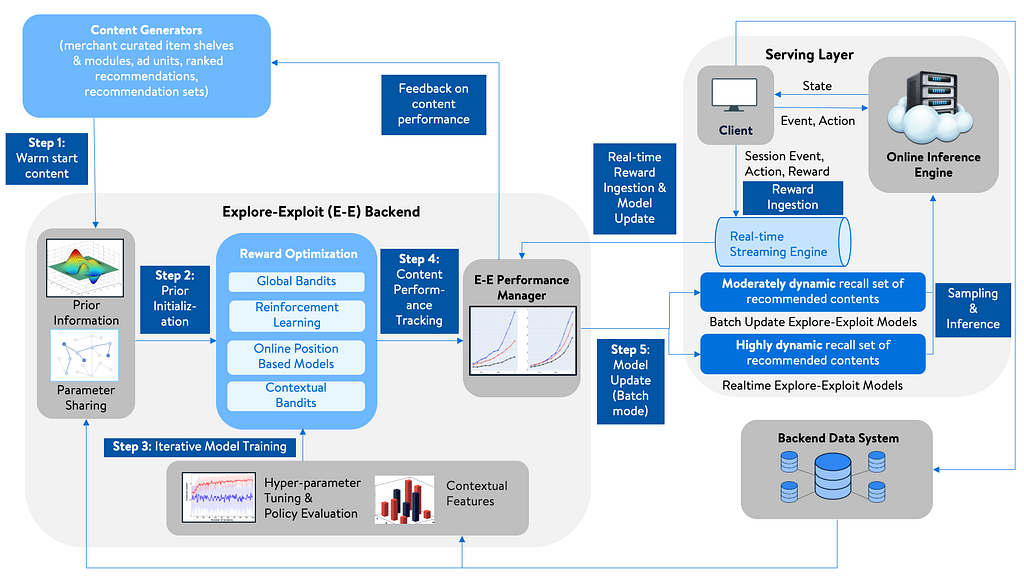
Explore-exploit framework:
Now let us dive into the details of the explore-exploit framework.
- As a first step, new or cold content is consumed from content generators and goes through a “warm start” stage. Warm start models are used to bootstrap unseen pieces of content or items that lack any customer interactions feedback in a given recommendation context. Different warm start models are defined for different use cases such as discoverability and exploration of new items, or best item(s) selection for very focused and granular targeting.
- Next, using a multi-armed-bandit framework, a measure of content relevance is decided for each arm (or item in our implementation) as a reward, such as click-through rate, conversion rate, or attributed revenue from the web sessions for the reward optimization model. Our base model is the well-known Thompson Sampling [8], which works well in these problems and scales well as documented in [1–3, 5–6], as well as our own empirical observations. Our team made several adaptations to the base Thompson sampling model, which may be discussed in a later blog.
- Once the reward optimization model for a given recommendation module is generated, it goes through our performance tracking manager which performs two main functions:
- Detect any anomalous behavior such as skewed traffic allocation to certain set of candidates in the pool or if there is a sudden change in the expected reward distributions of the arms in the model. Our (online learning) model evaluation library is deployed to measure and detect any outlier behavior before pushing the model to the serving layer model repository.
- Provide direct feedback to content generators on over-exposure of low performing content or under-exposure of high performing content. This helps them to reduce presentation bias faster compared to the indirect process, where the model ingests customer interaction data influenced by explore-exploit thereby updating its offline model inference.
4. Once the performance manager approves the updated model, the reward optimization models are pushed into the serving layer model repository. Here, they are used for real-time ranking along with customer-centric click prediction models tasked with capturing subtle nuances of content preferences at each customer level (e.g., the Q family).
As shown in the architecture diagram, the explore-exploit framework uses both real-time updates and batch updates to generate the latest posterior distribution parameters in the serving layer.
Integration of explore-exploit framework with other personalization and recommendation rankers:
The explore-exploit framework must be integrated with the recommender model trained on historical data to produce the final content ranking for the customer at run-time. The recommender model trained on historical data could be an offline ranker, or an online learning framework which, for each customer visit to a webpage, generates a score for each content and if left alone, will rank the contents in the decreasing order of the score. Similarly, in Thompson Sampling, which is the base model of our explore-exploit framework, the contents are ranked according to the sample generated from the posterior distribution of the reward associated with the content.
To define the final ranking function using the two scores from the two different models, we apply monotonically increasing functions on both to bring them to a more comparable state. We then add these two scores to arrive at a final score to rank the contents.
Mathematically speaking,
- if x is the score of a content by the recommendation model trained on historical data,
- and w is a sample from the appropriate posterior distribution for the content of the explore-exploit framework,
final score for any item (content) i is given by
S(i) = f(x(i)) + g(w(i)), where the transformations f(.) and g(.) are monotonically increasing functions.
Examples of f(.) and g(.) could be {exp (β .), β> 0 }, {log(β .), β > 0 }, { ( + β . ), a real number, β > 0}, which could be chosen differently for each web application.
Finally, we rank the contents according to final scoring function S() for each customer request at run-time. Note that this integration is done at the serving time and since the posterior sample w(i) is random, so is g(w(i)), allowing content ranking to be changed without any change in the estimated parameters of any of the models. Thus, there exists randomization and experimentation in content ranking, so a customer revisiting the same webpage in the same or future web sessions may observe a different ranking of the contents.
The integration of the two scores (f(x) + g(w)) could be interpreted in two ways. In one way, one could think of f(x) as the base score (note that ranking contents with respect to x and with respect to f(x) will produce identical result), which is perturbed by introducing a noise term g(w) to enable exploration to break the presentation bias.
On one hand, this perturbation term shifts the base score to reconcile with the performance of the content captured in broad trends, and on the other hand allows a noise term in the shifted score according to the volatility of the performance of the content observed in broad trends. This interpretation makes this model integration like Plackett-Luce estimators used in ranking contents [4, 7]. The difference is that in a Plackett-Luce estimator, no mean-shift is done, and the volatility of the noise term is the same for each content ranked. We believe this makes our exploration more informative than Plackett-Luce type of estimators and we are actively conducting research to theoretically establish it.
Another way of interpreting the integration (f(x) + g(w)) could be where we take g(w) as the base score enabling exploration-exploitation balance (note that ranking of contents using w and ranking them using g(w) will produce identical ranking of contents) and f(x) is a mean-shift in the posterior distribution customizing it to the particular instance.
How do we estimate impact?
The explore-exploit platform we described above is integrated with multiple personalization and recommendation models on multiple types of webpages. As is now standard in the process of deploying new features, enabling the explore-exploit framework went through standard rigorous A/B testing for each web application. However, these standard tools fail to capture the full impact of enabling explore-exploit and only offer a lower bound of the impact for two reasons:
- The model does not attain maturity while being subjected to measurement. In other words, when the framework is A/B tested for the first time, like any other artificial intelligence system, it has only started learning (i.e., exploration is still dominant). Over time, the system uses its learning to provide higher impact results.
- During the A/B test, the experimentation is done by the variation with the explore-exploit framework enabled, thereby restricting experimentation to only a fraction of the traffic, making the learning process of the framework slower, compared to a full launch with 100% traffic going through explore-exploit.
Therefore, once the system reaches maturity, it produces higher impact than at its launch. Mitigation of this effect by rejecting the first few days of data in the A/B test seems possible, but no one can be sure exactly when the system achieves maturity since the content pool, customer base, and other inputs keep changing. Therefore, despite mitigation attempts, the best evaluation can merely measure the directionality of improvement and a lower bound.
Additionally, although it’s possible to run the models repeatedly to produce separate outputs for tests and controls, this is discouraged due to operational convenience and added computational costs. Therefore, the improvement of the recommender model based on historical data due to enrichment of historical data through additional exploration is not captured in the A/B tests.
Improvement to Normalized Discounted Cumulative Gain (NDCG) metrics
To estimate the impact brought on by enriched input to the recommender model based on historical data, we took an alternative route. We compared the NDCG score of the recommender model output with respect to engagement metrics before and after the launch of explore-exploit framework. We made sure no model change happened during the time of this measurement and looked at a long enough period both before and after the launch to reduce any effect of seasonality. Thus, we could better estimate the impact of the change to the new recommendation model.
Note that this measurement only compares outputs of the recommendation model and thus does not include any impact we already measured through the A/B test, where we compared the ranking from static recommendation ranker model output against the output of the final ranking function that combined static ranking score with explore-exploit model output.
Thus, to measure the total impact of an explore-exploit framework, we need to add (after bringing them to the same metric) the two impacts, one where value is added by informatively perturbing the output of the recommendation model trained on historical data and another, where value is added through an enriched input to the recommendation model trained on historical data created by balanced exploration. Even then, we would only be estimating a lower bound of the impact as the full impact is not captured in the A/B tests.
Measured Impact at Scale:
On item pages, the measured business metrics improved more than 11%. The framework’s impact was harder to measure on the homepage due to its simultaneous launch with other features, but it contributed to a 30% lift in business metrics for multi-item carousels and a 35% lift for single-item recommendations.
On category-specific content pages with human curated content, there were between 14 to 35% lift in engagement metrics. Due to the lower volume of traffic in these pages, the impact was analyzed through comparing pre-launch and post launch engagement metrics.
Conclusion:
Balancing the dual goals of exploring to gain knowledge and presenting personalized recommendations in large-scale personalization and recommendation can be accomplished by integrating two models: an explore-exploit framework and a recommender model trained on historical data to make granular content recommendations. Our solution is both operationally convenient and produced significant lift in business metrics for a wide variety of applications, demonstrating robustness even though some challenges remain in estimating its full impact.
References:
[1] Agarwal, D., Long, B., Traupman, J., Xin, D. and Zhang, L. 2014. “Laser: a scalable response prediction platform for online advertising”. In: Proceedings of the 7th ACM international conference on Web search and data mining. ACM. 173–182.
[2] Hill, D. N., Nassif, H., Liu, Y. , Iyer, A. and Vishwanathan, S. V. N. 2017. “An efficient bandit algorithm for realtime multivariate optimization”. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1813–1821.
[3] Li, Lihong, Chu, Wei, Langford, John and Schapire, Robert E. 2010. “A Contextual Bandit Approach to Personalized News Article Recommendation”. CoRR abs/1003.0146 (2010). arXiv:1003.0146 http://arxiv.org/abs/1003.0146.
[4] Oosterhuis, Harrie. 2021. “Computationally Efficient Optimization of Plackett-Luce Ranking Models for Relevance and Fairness” arXiv:2105.00855. https://arxiv.org/abs/2105.00855.
[5] Russo, Daniel, Van Roy, Benjamin, Kazerouni, Abbas, Osband, Ian and Wen, Zheng. 2017. “A Tutorial on Thompson Sampling”. arXiv:1707.02038. https://arxiv.org/abs/1707.02038.
[6] Scott, S. L. 2015. “Multi-armed bandit experiments in the online service economy”. Applied Stochastic Models in Business and Industry. 31(1): 37–45.
[7] Singh, Ashudeep and Joachims, Thornsten. 2019. “Policy learning for fairness in ranking” NIPS’19: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Article No.: 487, Pages 5426–5436.
[8] Thompson, W. 1933. “On the likelihood that one unknown probability exceeds another in view of the evidence of two samples”. Biometrika. 25(3/4): 285–294.
Lessons from Adopting Explore-Exploit Modeling in Industrial-Scale Recommender Systems was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.