Binay Gupta, Anirban Chatterjee, Kunal Banerjee.
Introduction:
Label noise refers to errors or inaccuracies in the assigned labels or annotations of a dataset. While supervised machine learning algorithms rely on correctly labeled data, real-world scenarios often introduce incorrect labels for various reasons. In this blog, we will explore the sources and challenges associated with label noise, as well as the solution offered by the Progressive Label Correction (PLC) technique. Additionally, we will showcase a project where PLC has significantly improved the model’s performance, as measured by the balanced accuracy score. Join us as we delve into the intricacies of label noise and its impact on machine learning models.
How Label Noise Gets Introduced:
Label noise can stem from multiple sources, including human error, inconsistent annotation guidelines, biases, resource limitations, ambiguity, and adversarial manipulation. In this context, our focus will be on two additional factors that contribute to label noise. Rather than examining the well-explored aspects, we will delve into these less-explored reasons in greater depth.
Missing Value Imputation: Real world data often contains sparse features. When we try to impute in these missing values, label noise can be introduced. To understand why these imputation errors lead to label noise, let’s consider a simple example (fig. below). Imagine we have a data point with two features f1 and f2. In its original state, it belongs to ‘class 1’. Now, suppose f1 is missing and we impute a value for it. After imputation, the data point moves to a different region, say ‘class 2’, even though its original label was ‘class 1’. This discrepancy between the imputed location and the original label creates label noise. It’s important to note that data points near the class boundary are more likely to experience label noise when missing values are imputed.
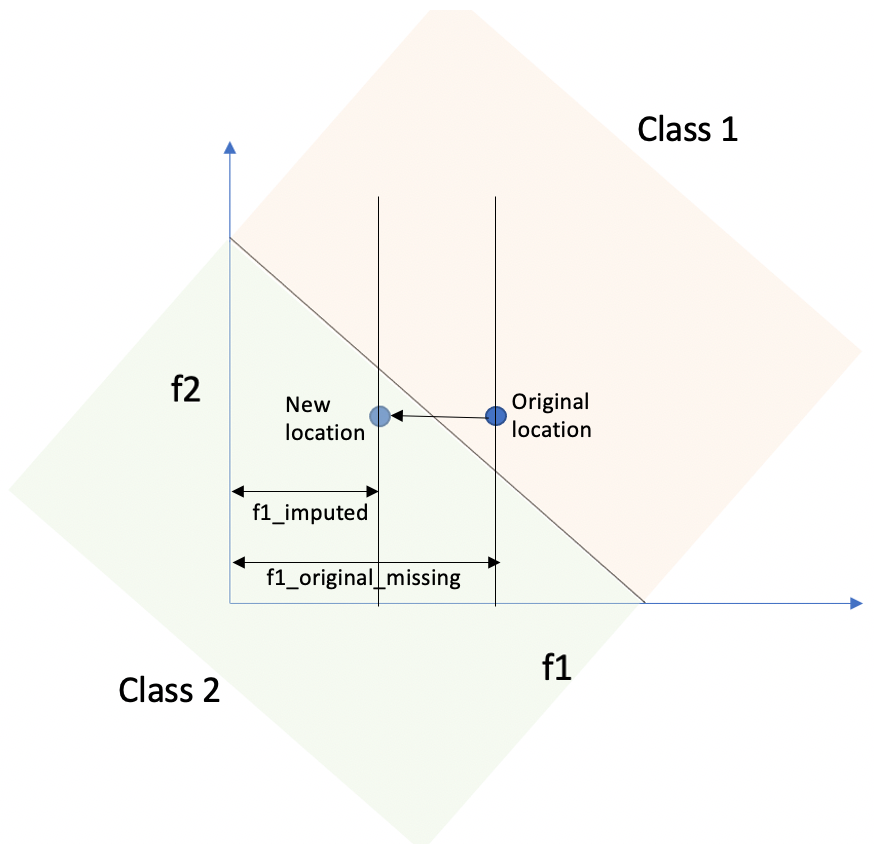 Label Noise Due to Missing Value Imputation
Label Noise Due to Missing Value Imputation- Business Process: Sometimes, the business processes within an organisation can contribute to label noise, leading to misleading conclusions. For instance, in healthcare, a patient’s blood report indicates that (s)he has a high risk of developing an infection. However, due to additional checks and measures taken by the doctor, the patient didn’t develop any severe infection. Here, the intervention by the doctor creates label noise, as the record falsely appears as a ‘non-infectious’ in the dataset used for ‘infection modeling’.
Problems of Label Noise:
Label noise presents several challenges and problems in machine learning, impacting model performance, robustness, data collection efforts, model outputs, interpretability, and evaluation.
- Degraded Model Performance: Models trained on noisy labels learn incorrect patterns, leading to reduced predictive accuracy and poor generalisation to unseen data.
- Decreased Robustness: Noisy labels make models more sensitive to variations, resulting in lower robustness, poor generalization, and increased vulnerability to adversarial attacks.
- Increased Data Collection Effort: Handling label noise requires additional efforts to clean or collect new labeled data, leading to delays and increased costs in the machine learning pipeline.
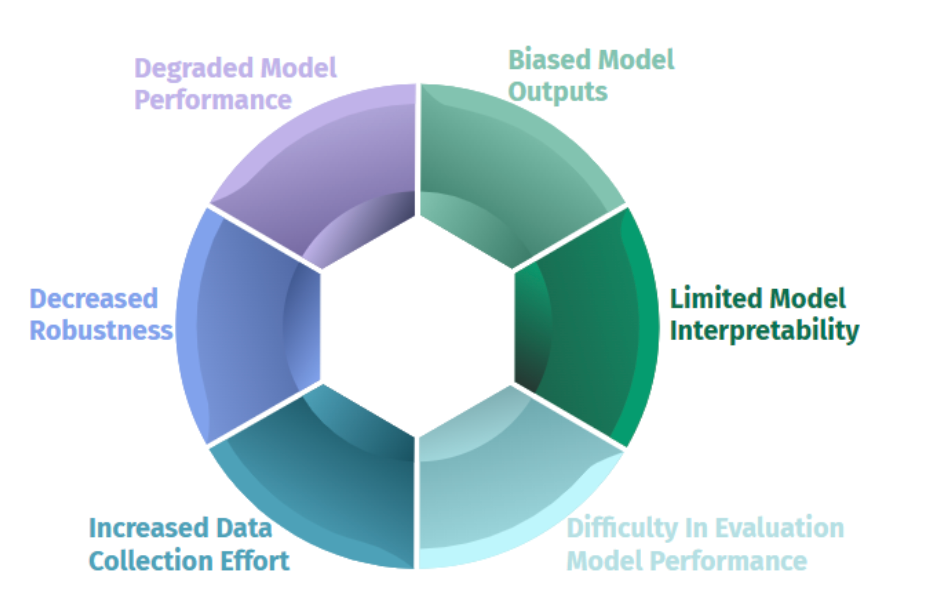 Problems of Label Noise
Problems of Label Noise- Biased Model Outputs: Label noise can introduce biases by replicating unfair outcomes.
- Limited Model Interpretability: Noisy labels make it challenging to interpret and explain model predictions, hindering transparency, trust, and accountability.
- Difficulty in Evaluating Model Performance: When the dataset contains label noise, the model’s predictions may not align with the actual ground truth labels. As a result, standard evaluation metrics, which assume the correctness of labels, may provide misleading insights into the model’s performance.
Addressing label noise is essential to mitigate these challenges and ensure the reliability and effectiveness of machine learning models in practical applications.
How PLC Helps to Mitigate Label Noise:
PLC, or Progressive Label Correction, is an iterative algorithm that aims to remove label noise from training data by iteratively correcting mislabeled instances based on the model’s predictions. Let us see step-by-step algorithm for Progressive Label Correction (PLC):
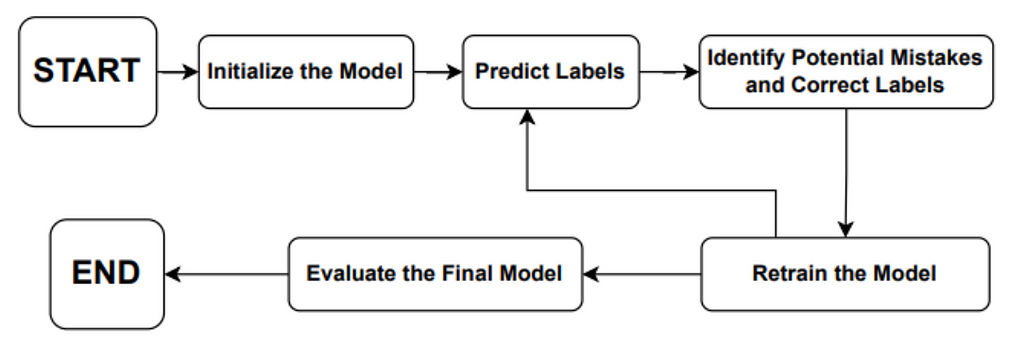 Steps for Progressive Label Correction (PLC)
Steps for Progressive Label Correction (PLC)- Initialise the Model: Start training machine learning model with (mis)labeled dataset. Tune model’s hyper-parameters to make accurate predictions.
- Predict Labels: Let the trained model make predictions on the entire dataset. For each instance, the model will provide a prediction along with a confidence score.
- Identify Potential Mistakes and Correct Labels: Look for instances where the model’s predictions are very confident but conflict with the original labels. These instances are considered potential mislabeled examples. Update the labels of the identified potential mistakes based on the model’s predictions. Replace the incorrect labels with the new predictions.
- Retrain the model: With the corrected labels, retrain the model using the updated dataset. Tune model’s hyper-parameters to make accurate predictions.
- Repeat Iterations: Repeat steps 2 to 4 for a certain number of iterations or until a desired level of label correction is achieved. In each iteration, the model becomes better at identifying and correcting noisy labels.
- Evaluate the Final Model: After the desired number of iterations, evaluate the performance of the final model on a separate validation or test dataset. This helps determine the effectiveness of the PLC process in reducing label noise and improving the model’s performance.
By iteratively correcting labels and training the model on the updated dataset, PLC aims to progressively improve the accuracy and reliability of the model, leading to better predictions and performance.
An Example:
Reducing the number of failures in a production system is one of the most challenging problems in technology driven industries, such as the online retail industry. To address this challenge, change management has emerged as a promising sub-field in operations that manages and reviews the changes to be deployed in production in a systematic manner. However, it is practically impossible to manually review a large number of changes on a daily basis and assess the risk associated with them. In a recent project, our goal was to automatically evaluate the risk category (such as ‘risky’ or ‘non-risky’) of change requests.
Initially, our model exhibited satisfactory performance. However, we noticed a decline in its accuracy over time after retraining it with updated data. Upon closer examination, we identified that label noise was being introduced into the dataset due to manual intervention by the change management team. To illustrate this, let’s consider a scenario where a change request (CRQ) carries a high risk of causing production failures. The change manager and the requesting team take measures to mitigate this risk and prevent failures. Nevertheless, due to their manual intervention, the CRQ may not result in any production failures. Consequently, when this particular CRQ is included in the historical dataset used for training a risk prediction model, it erroneously appears as belonging to the ‘normal’ or ‘non-risky’ class since it did not lead to any failures. In reality, its label should have been different, taking into account its potential to cause production failures. Thus, manual intervention in the change management process, which is not reflected in the change data, introduces label noise into the dataset, thereby impacting the model’s performance.
To address the problem of label noise, we have employed Progressive Label Correction (PLC) to rectify the labels in the dataset. After label correction, we retrained the model while keeping all other factors constant, resulting in a notable 20% enhancement in balanced accuracy. The result against 200K sample change request is shown in figure below:
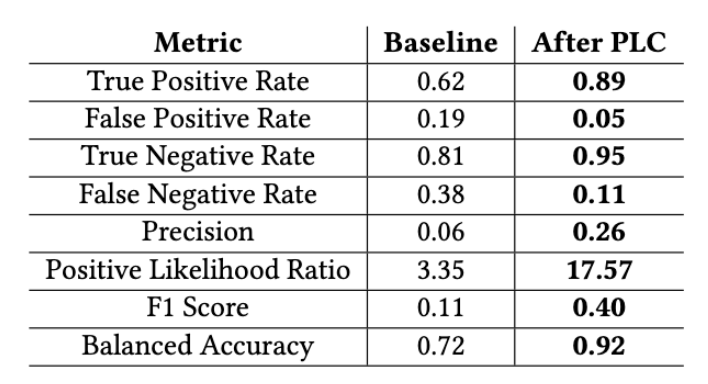 Experimental Result Before and After Applying PLC
Experimental Result Before and After Applying PLCLimitation of PLC:
While PLC is effective in addressing label noise, it does have limitations. One drawback is its computational expense, making it less scalable for handling large datasets. This requires significant computation power, which can be costly. To mitigate this, data scientists can strategically select a representative sample for PLC training, treating the remaining training data as validation data and correcting its labels. Finally, the combined dataset can be used to train the original model. This approach helps alleviate the impact of computational constraints while still benefiting from the label correction offered by PLC.
Conclusion:
In this blog, we have discussed Label noise, how it gets introduced in training data, and poses significant challenges in machine learning models. In real-world scenarios, label noise can stem from various sources, including human intervention. The case of manual intervention in change management processes introduces label noise, affecting the accuracy of risk prediction models. To mitigate this, Progressive Label Correction (PLC) proves valuable by iteratively correcting mislabeled instances. We have concluded the blog discussing how implementing PLC leads to improved model performance, ensuring the reliability and effectiveness of machine learning applications.
References:
[1]TianqiChenandCarlosGuestrin.2016.XGBoost:AScalableTreeBoostingSystem. In KDD. 785–794.
[2] Digital.ai. 2019. Change Risk Prediction. (2019). https://digital.ai/change-risk- prediction.
[3] BinayGupta, AnirbanChatterjee, SubhadipPaul, HarikaMatha, LalitduttParsai, Kunal Banerjee, and Vijay Agneeswaran. 2022. Look before You Leap! Designing a Human-centered AI System for Change Risk Assessment. In ICAART. 655–662.
[4] Yang Liu. 2021. Understanding Instance-Level Label Noise: Disparate Impacts and Treatments. In ICML (Proceedings of Machine Learning Research, Vol. 139). PMLR, 6725–6735.
[5] Yikai Zhang, Songzhu Zheng, Pengxiang Wu, Mayank Goswami, and Chao Chen. 2021. Learning with Feature-Dependent Label Noise: A Progressive Approach. In ICLR. https://openreview.net/forum?id=ZPa2SyGcbwh
Label Noise, Problems and Solutions was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Label Noise, Problems and Solutions | by bguptaiitb | Walmart Global Tech Blog | Sep, 2023 | Medium