 Image by Gerd Altmann from Pixabay
Image by Gerd Altmann from Pixabay
Why should you think like a data scientist?
“All companies fit into one of two buckets: either becoming a software company or being disrupted by one.” — Mike Cannon-Brookes, CEO, Atlassian
Data Science is the application of statistics and computer programming to harness the power of data for an organization’s decision-making. With the capabilities of software increasing beyond just automation, Machine Learning and Artificial Intelligence are becoming as crucial to intelligent software as the software is crucial for disruption. So thinking like Data Scientist is not just required for Data Scientists, but is equally important for business partners, project sponsors, engineering developers, managers, product owners, program managers, and everyone who works in the technology ecosystem. After all, Data Science is only as useful as systems that it powers, and everyone’s role in making those systems is important.
So how do you go about thinking like a data scientist? To begin with, you don’t have to learn data science, but basic familiarity helps. Here is one 5 minute video which is a good starter. But really, thinking like a data scientist is not about knowing algorithms and statistics, but a paradigm shift in how you see the world. Here are three important dimensions which can help you hone your data-science thinking to get maximum mileage from your data science engagement:-
1. Why am I using Data Science?
“A man always has two reasons for what he does-a good one, and the real one.” — John Pierpont Morgan
Data Science is neither a magic trick nor a metric. It’s the art and science of solving problems using data. Data Science works well when (a) the problem is well specified and (b) doesn’t shift goal post frequently.
 Image by Gerd Altmann from Pixabay
Image by Gerd Altmann from PixabayA well-specified problem looks to achieve a well-specified set of statable (and preferably, measurable) outcomes. Giving offers to customers to increase customer satisfaction isn’t a well-specified problem. Giving offers to increase referrals is. (Because customer satisfaction is intangible.)
Similarly, the goal of the problem shouldn’t change often. This is not to say that Data Science development isn’t agile. In fact, iterative delivery and constant feedback are foundational to Data Science delivery. However, the destination shouldn’t change. For instance, if I started by looking to increase customer referrals and pivoted to increasing customer retention as a measure of customer satisfaction, then I am essentially asking for starting from scratch.
This is not something related to how Data Scientists work but is inbuilt in process of analytic design and the underlying mathematics. What Data Science can adapt to is the changing data availability, quality, and business constraints. What Data Science cannot adapt to is changing the very purpose of analysis.
Or, using the canonical example, if we wanted an airplane rather than a car then we cannot pivot from the motorbike in the middle of the modeling process!
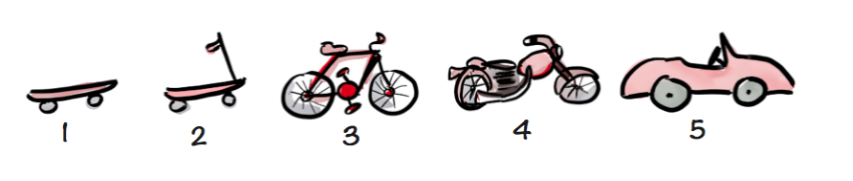 Image from Agile Bicyle: dotdev.co
Image from Agile Bicyle: dotdev.coIt’s also important to know that for all its hype, Data Science is still a computer program following instructions. Hence it cannot solve ethical dilemmas, arbitrate strategic priorities, and replace years of experience in the field by domain experts. Business partnership on subjective decisions and the ability to take the decisive call and move on are important requirements to get out from perpetual analysis-paralysis or perpetual branching out of what-if scenarios. That is not to say that alternatives should not be explored, but you’d be surprised that, in practice, this hinders more than it helps by delaying value delivery.
2. What do I expect out of Data Science?
“It is better to be roughly right than precisely wrong.” — John Maynard Keynes
Because Data Science leverages data, any limitation about availability, completeness, and quality of data will impact the outcome. This seems reasonable enough on the face, but the number of times Data Scientists have to measure up to standards of accuracy expected by the business which is clearly not supported by data is just too many to count. Being in line with the realities of quality of data and tempering expectations, while planning for improved data collection and labeling are ways to set up work for success.
 Image by Dilbert.com
Image by Dilbert.comSince Data Science is, at its core, built on statistical foundations, all data science outcomes are probabilistic outcomes, even if they are not presented as such sometimes. Being comfortable with probabilistic outcomes and confidence intervals helps obviate the need for arbitrary levels of certainty not shown even by the real world.
Another facet of probabilistic thinking is understanding that there is no model which is perfectly right in real-world use cases for all scenarios. No model can be, nor should expected to be, right everywhere, always, all the time. Focusing on margins is a recipe for stalemate and analogous to throwing away the baby with the bathwater. A data scientist’s way of thinking focuses on accepting an approach that is better than the status quo — what would the organization have done without data science inputs — and then aspiring for continuous improvements on top of that. Expecting a solution to be perfect in the first version is essentially implicit acceptance of an even worse status quo.
3. How do I get the best of Data Science?
“If you don’t know where you’re going, any road will get you there.” — Lewis Carroll
When looking to build a model or starting an analysis, a Data Scientist often thinks about how the results will be used. This helps in two ways: one, it helps guide the analysis, and two, it helps focus on what matters.
 Image by Oberholster Venita from Pixabay
Image by Oberholster Venita from PixabayIf I am looking to identify top products by customer, the underlying ML approach will be different if the outcome is expected to be used for auto-populating customers’ shopping cart, versus if the outcome is expected to be used for giving discounts. In absence of outcome and actionability driven thinking, focus diverts to what’s understandable and easy, but not what’s right and useful, and often gets trapped into the unending discussion on this or that way of doing feature engineering, this or that way of selecting model parameters, and so on. But if the product, engineering, business, and data science functions are aligned on the outcome, then those debates naturally find a resolution.
One way to keep the focus on outcomes is to define outcomes through a few well-defined measurable metrics. Under the hood of Machine Learning, all Data Science analyses have an underlying measure they are optimizing for. Technically called a “cost function”, both supervised and unsupervised algorithms work towards optimizing certain metrics. If the business outcome is not specified in terms of metrics, you aren’t getting away from specifying one, you are simply surrendering your thinking to default by the model. Being explicit in thinking of a metric that reflects the expected impact of the data-driven decision, is important to get the most value from the Data Science product while mitigating analysis-paralysis and what-if cycle.
 Image by XKCD
Image by XKCDThe analytic design process should take as long as needed to think of the right set of metrics, but once they are specified, we must trust them to do their job and deliver a solution that positively impacts the outcome. In practice, the discussion often digresses to the palatability of solutions and recommendations, which cannot be tweaked in itself without tweaking either the data or the outcome metric. The ‘Learning’ in Machine Learning implies that the approach cannot be tinkered from the outside except through levers of data and cost function. If the quality of recommendations leads to a flaw in metric, sure, go ahead and change, but the repeated cycle of change just implies a preference for getting the desired result irrespective of what data tells, and at that point, one may as well do away with Data Science in the decision process.
While obvious, it remains worth being cautious that specified metrics must reflect the desired real-world outcome, in that change in the metric in the right direction should incentivize the desired direction of business outcome. For instance, if I am measuring the ability of the Machine Learning model to discover expense frauds through dollar values of expenses rejected, then I am essentially incentivizing the model to reject all expenses and not really discover frauds. For another example, a metric to measure customer referral should not focus on new customers (since there are other marketing channels), nor new referrals (growing customer base may increase in referral count), but referrals per existing customer. Of course, how would you know if these referred customers wouldn’t have come on their own (want=referrals, need=customer growth)? Hence the experimentation!
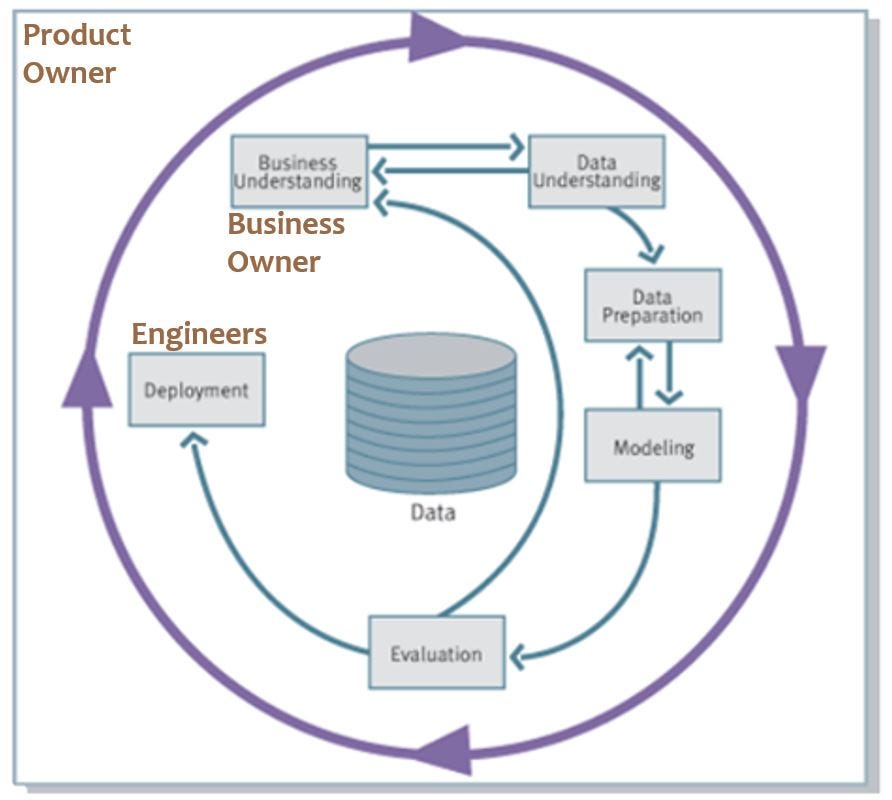 CRISP-DM process from Wikipedia
CRISP-DM process from WikipediaGiven that the data quality plays important role in the accuracy of Machine Learning predictions, and given that waiting for perfection is an unachievable goal, how do we decide when we are ready for production deployment? Data Scientist’s way of thinking is by focusing on the outcome, through the right metric, and aiming for the process to do better than what would have been done otherwise. As long as the model does that, and differential improvement in accuracy over the status quo is worth technology investment to bring model output to fruition, Data Science has done its job and ready for use. And ready for the next iteration.
Being comfortable with experimentation, trials, A/B testing is important to arbitrate some of the subjective decisions we outlined above and to distinguish value addition from the ML component from the rest of the product and business process.
Parting Words
A business need requires a solution. A product requires functionalities. It is immaterial whether they are Machine Learning driven functionalities or not. Hence the application of Data Science in the product has to be inherent and tightly integrated into the design, architecture, and UX of the product from the beginning. A good Machine-Learning solution is an invisible one.
In cases where business and product stakeholders aren’t versed with the capabilities of Data Science, product “wants” may refer to feature they can envision. Asking series of ‘so-what’ and ‘why’ leads to potential opportunities for Data Science to add value even if that’s not what’s originally asked. If a car mechanic is looking for a product with an alarm feature based on engine oil level, it can be a simple rule to implement. But digging deeper may discover if engine oil level deviation from expected behaviour based on car’s maintenance history is what is actually desired. It can help to go beyond what’s wanted and identify the needs to actually create impact and drive innovation.
Thinking like a Data Scientist is not about understanding algorithms and statistics, it is a paradigm shift in how one sees the world — and it’s worth it.
What lessons can you share in thinking like a data scientist? What did I miss? Comment and let me know!
How to think like a Data Scientist? was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: How to think like a Data Scientist? | by Ashish Gupta | Walmart Global Tech Blog | Medium