Health Data Interoperability — Message Exchange Standards
 Image source: https://www.adalovelaceinstitute.org/project/boundaries-of-health-data/
Image source: https://www.adalovelaceinstitute.org/project/boundaries-of-health-data/In the first article in this series, we discussed the ‘What?’ and the ‘Why?’ Of Health Data Interoperability (HDI).
Health Data Interoperability — The What And the Why.
In the previous article, we discussed the ‘How?’ part. We discussed various vocabulary standards like ICD, SNOMED-CT, LOINC, etc.
Health Data Interoperability — The Vocabulary
So, now we know why health data interoperability is important and we also know a variety of terminologies commonly used in Health Data. We know the words and the spellings of health data language. However, for any reasonable information exchange, we must also learn the grammar (structure) of the data. Before you feel a strong urge to run away, please be assured we will not discuss any grammar here. This is just a loose analogy.
Here is a more precise demonstration of what can go wrong with ineffective messaging standards.
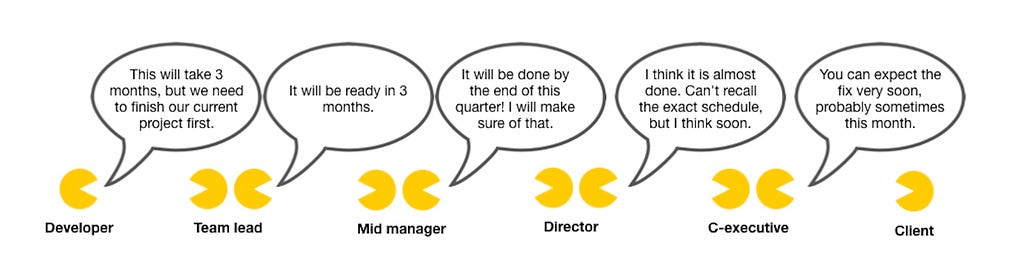 source — https://assertiveprogrammer.com/
source — https://assertiveprogrammer.com/Imagine such a confusing communication between your healthcare providers .
Health data interoperability is all about sharing health data between different systems and making sure they can understand each other. To do that, we need some standards for how the data should look when it is exchanged. These Messaging standards help healthcare systems and providers exchange information in a standardised and consistent way. They define how data is organised, what data elements are required, and how data is transmitted between systems.
History and Evolution
The concept of Messaging standards is not new to us techies. We already know messaging standards like JSON and XML that are widely used in web applications. Why then do we need separate messaging standards for health data?
Half of the answer lies in the history of the HDI. While HTTP messaging standards evolved from HTML to XML to JSON, HDI standards also had an evolution of their own. Standards were crafted in the days before the Transmission Control Protocol — A layer below HTTP in the software hierarchy — commonly known as the TCP. Consequently, they look alien to modern human programmers. Given the complexity, HDI messaging standards were also slower to evolve than web messaging standards. So the most widely used HDI Standards still look similar to the old ones.
In the early days of health data exchange, the domain was replete with many proprietary messaging formats, making it difficult to share information between different systems. In the 1980s, the American Society for Testing and Materials developed the first healthcare messaging standard (ASTM E1238). However, ASTM E1238 was limited in scope and was not widely adopted.
In the 1990s, a new messaging standard was developed by HL7 international organisation, called Health Level Seven (HL7) Version 2. It allowed for the exchange of clinical data, such as lab results, patient demographics, and medication orders. In the early 2000s, a new messaging standard called HL7 Version 3 was introduced, which was designed to be more flexible than the V2. But it was not as widely adopted due to its complexity. The 30-year-old HL7 V2 remains the most widely used standard to date.
Another reason why HDI standards are hitherto different from web standards is the technical requirements. Health data requires a specific structure and context. It requires stricter regulatory requirements for privacy and security. Data governance — i.e. the ability to track the version history and the change history of the data — is also an important requirement for health records. Any health data system must satisfy the strictest of the regulations, HIPAA compliance, to operate legally. We will talk more about that in a subsequent article.
Historically, web messaging standards were not subjected to such regulatory concerns. But the good news is that the HDI and Web messaging standards are starting to converge. The newer ones increasingly look alike.
In recent years, there has been a push towards more modern messaging standards, such as Fast Healthcare Interoperability Resources (FHIR). FHIR is a web-based messaging standard that is designed to be more flexible, user-friendly, and human-readable than HL7 V2 or V3.
There is no dearth of literature on the internet about health data messaging standards. So we may do well not going deep into each of them. However, It may be a worthy pursuit to look at some of the most commonly used ones with an intent to gaze at the landscape of the lore.
HL7 V2

HL7 standards started in 1987 with V1 and evolved to now V4. But it was the V2 that stole all the thunder. It is a 30-year-old standard that has no resemblance to any modern data standards. And yet It remains the most widely used standard to date.
This is what a message written in HL7V2 looks like.
- Warning: Boring part, TL;DR
- Example HL7V2 message
-----
MSH|^~\&|MegaReg|XYZHospC|SuperOE|XYZImgCtr|
20060529090131–0500||ADT^A01^ADT_A01|01052901|P|2.5
EVN||200605290901||||
PID|||56782445^^^UAReg^PI||KLEINSAMPLE^BARRY^Q^JR||
19620910|M||2028–9^^HL70005^RA99113^^XYZ|
260 GOODWIN CREST DRIVE^^BIRMINGHAM^AL^35200^^M~NICKELL'S PICKLES^1000 W
100TH AVE^BIRMINGHAM^AL^35200^^O|||||||0105I30001^^^99DEF^AN
…
_____
The message is hierarchically organised into
Segments > Fields > Components
- Segments are the basic block of the messages. They start
with a segment types identifier, like MSH or PID (Header and
Patient demographic information respectively).
- Fields are the ordered units of data within each segment.
For example, in the PID segment, the first field is
the patient identifier.
- Components are the sub-elements of each field, like first
name, middle name, and last name, separated by a delimiter
character such as a ^ or a |.
BTW HL7V2 is also called the Pipehat standard, no points
for guessing why.
I know… quite a tongue twister, right?
Despite being illegible to humans, the structure of HL7 V2 messages is similar to any hierarchical data format. Every message comes with a header (MSH) that contains information about the message type, the sender and receiver, and the message version. The above message, for example, is an ADT A01 message, which is emitted on a patient’s admission. The message body contains the actual data of the message in the form of segments, fields, and components.
HL7V2 was designed to work with MLLP — Minimal Lower Layer Protocol — A lightweight protocol that provides reliable and secured transmission of messages over the TCP. MLLP also includes error checking and retransmission capabilities to ensure fault tolerance in the presence of network errors.
Most healthcare systems in the USA currently use the HL7V2. However, HL7 V4 — aka FHIR — promised to change this.
FHIR
Fast Healthcare Interoperability Resource

15 years ago when I was an engineering student, sometimes all it took to hack a site and see other users’ data was to change the user IDs embedded in the URL of a page. Thankfully we have moved on from those simple days. Web standards these days are increasingly cautious about security, privacy and regulatory concerns. FHIR takes advantage of these developments and brings the format of health data exchange closer to the web standards.

FHIR, pronounced as ‘fire’, is an HDI messaging standard that looks like the standard we techies love… JSON. It uses a resource-based approach to represent healthcare data. Each resource represents a discrete piece of data, such as a patient record, a medication order, or a laboratory test result. Resources are identified by a unique URL, and they can be accessed and manipulated using standard HTTP verbs such as GET, PUT, POST, and DELETE. I guess any full-stack developer will be complete at REST with that, pun intended.
When talking about RESTful APIs, one can never overstate the importance of data schema and validation. That remains true for FHIR as well.
Let us take a small detour to understand what are schema and validations.
Schema is like the blueprint of a piece of data, also called a resource, which tells the server the elements to expect in a resource. For example, a person’s data should definitely include a name field of the ‘type’ string and an age field of the ‘type’ number. Optionally it may include an email, which must be of the ‘type’ string and the format [email protected].
Validations, as it sounds, refer to the process of validating if a piece of data follows the given blueprint. The API designers design their data schema and share it with the data’s consumers and producers. The server validates the incoming messages and determines whether the resources included in it are in accordance with this schema before accepting the request.
In the case of FHIR, the schema is called the profile, and It is a much more universal concept because the base profiles are defined by the HL7 organisation itself. The base profile of a patient resource, for example, mandates that it must include the patient’s name and date of birth, or the resource will be considered invalid. HL7 also enumerates the various resources predefined in the given version. The current version of the FHIR standard is called R4, likewise, the current base profile is called the R4 profile.
The base profiles are very general and designed to fit every possible use case. But they can be further restricted or extended based on an organisation’s business needs. For example, a Telehealth service provider may mandate that, apart from the base profile, the patient resource must have at least one phone number and at most one medical record number. Profiles are a part of the FHIR Implementation guides of an organisation. Implementation guides, provide detailed instructions on how to implement FHIR profiles and resources within a specific healthcare ecosystem.
The concept of profiles and implementation guides is so important to the FHIR standard that an entire DSL (Domain specific language) is invented to simplify the process of creating and maintaining them. The DSL is called FSH — FHIR Short Hand — pronounced as Fish. It also has its own compiler which is called… surprise surprise… SUSHI. If nothing else, FHIR standards surely win the naming game.
Using FSH and SUSHI, an organisation can create its own Implementation guides, profiles, and Structured definitions for their FHIR validations.
Sorry if that was a tad too technical… Unfortunately, my writing skills are not as good as Stephen Hawking who could explain the theory of everything without being technical. But I deserve some points for fighting my urge to paste an example FHIR resource somewhere in between and then describe it.
SMART on FHIR

Substitutable Medical Apps, Reusable Technologies
With SMART, FHIR takes interoperability (and its collection of cool names) a few notches further.
SMART on FHIR is a platform that allows developers to build healthcare apps that can seamlessly integrate with Electronic Health Record systems to access FHIR data. SMART provides standard components like OAuth2 for authentication, an App launch framework, a Standard way to manage Scopes and Consents, etc., out of the box. For a vague analogy, SMART is similar to the Google Play Store, or the Apple App Store, for healthcare apps.
 A Caution, FHIR may be a good step in the right direction, but still not be the magic wand we expect: https://healthapiguy.substack.com/p/a-song-of-health-and-fhir
A Caution, FHIR may be a good step in the right direction, but still not be the magic wand we expect: https://healthapiguy.substack.com/p/a-song-of-health-and-fhirDICOM
Digital Imaging and Communications in Medicine
FHIR and HL7 are all right but what about medical images like X-rays, MRIs, Ultrasounds or CT Scans?
Hence… DICOM.
DICOM is widely used around the globe for the communication and exchange of medical images between healthcare providers, systems, software, and medical imaging devices. The DICOM standard is not one but rather a set of standards that include:
- Information Object Definition: IOD specifies how data elements should be organised and represented within a DICOM object. For example, a CT image IOD specifies what a CT Scan DICOM object should look like.
- Data Elements: DICOM uses a predefined set of data elements to represent information within a DICOM object. For example, patient information, imaging parameters, study details, image pixel data, and more.
- Network Communication Protocol specifies the use of the TCP/IP protocol suite for network communication between DICOM devices. It defines how DICOM messages are encapsulated within network packets and transmitted over the network.
- Media Storage defines the format and organisation of medical images and related information when stored. It specifies the file format, directory structure, and metadata requirements for media storage.
Apart from this, DICOM defines interactions and operations, like acquisition, storage and printing, on objects with Service Class Specifications (SCS). It also defines Data Transfer Syntaxes to govern how the data is encoded and compressed for transmission.
DICOM was first released in 1985. Since then, it has continuously evolved to accommodate the latest technology and industry needs. Recent versions of DICOM include DICOM Web, a set of RESTful web services that aim for easier integration of DICOM into web-based applications and workflows. DICOM has been updated to better accommodate AI algorithms and workflows in medical imaging. This includes defining new data elements and modules for AI-related metadata and annotations. It has also evolved to support emerging imaging technologies, such as 3D printing, molecular imaging, and advanced visualisation.
CDA
Clinical Document Architecture

CDA is a standard developed by HL7 to represent and exchange clinical documents. CDA is focused on the structure and format of these documents, providing a standardised way to capture and share clinical information in a human-readable format. CDA is typically used for document-centric information exchange, preserving the original narrative and layout of the clinical documents.
CDA is based on XML and follows a familiar hierarchical structure that includes Header, Body and Sections. CDA also provides templates that specify which sections and data elements are required, optional, or repeatable in a document. In that sense, it looks very much like an HTML page. Some common types of CDA documents are Continuity of Care Documents (CCD), Discharge Summaries, Laboratory Reports, etc.
While HL7 v2 and FHIR are more focused on real-time data exchange, CDA is designed for sharing clinical documents in a structured format. While HL7 v2 and FHIR are suitable for transactional data exchange and accessing discrete data elements, CDA is commonly used for longer, narrative-based documents that need to be preserved in their original form.
 https://medcitynews.com/2020/01/medcitys-weekly-cartoon-whither-interoperability/
https://medcitynews.com/2020/01/medcitys-weekly-cartoon-whither-interoperability/We discussed some common standards for data exchange in Health and Wellness. We are now empowered to understand the various data regulations and technology initiatives adopted by public health organisations across the globe.
Governments worldwide are actively implementing regulations and technology for health data interoperability. For example, The USA Government emphasises using FHIR for data exchange and encourages data sharing among healthcare providers. The UK, Australia, Netherlands, Estonia, Singapore and almost every other country with a vision for public health is implementing similar regulations and technology to improve health data exchange and promote interoperability in their healthcare systems. India too has an ambitious plan for the National Health Stack that envisions a unified and interoperable framework that connects various stakeholders in the healthcare ecosystem, including patients, healthcare providers, insurance companies, and government agencies.
Learning various data exchange formats also provides a leeway into the exciting field of data architectures in Health-tech. How should the data be stored in a Health Information System? How and when should it be transformed for Interoperability? Can or should the Interoperability standards like FHIR also govern the data storage models? What are the security and compliances concerns with Health Data Storage and Exchange?
So many exciting questions remain to be discussed. However, as much as I want to delve into these aspects of Health-tech, this article is already too long. So, let us leave it for another day.
I hope this article added a little bit to your repertoire of knowledge. Any suggestion will be highly appreciated with
Thanks for reading.
About me
I am a learner of architecture (not the buildings… the tech kind). In the past, I have worked with Semiconductor modelling, Digital circuit design, Electronic Interface modelling, and the Internet of Things. Currently, I am working with Data Interoperability and data warehouse architectures for Health and Wellness, at Walmart Health and Wellness.
Health Data Interoperability — Message Exchange Standards was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Health Data Interoperability — Message Exchange Standards | by Rahul Nayak | Walmart Global Tech Blog | Medium