ElasticSearch : Wildcard searches
What is ElasticSearch?
Elasticsearch is a distributed, free and open search and analytics engine for all types of data such as textual, numerical, geospatial, structured, and unstructured. It is built on Apache Lucene which is a full-text search engine and can be used from various programming languages. Owing to its speed, scalability and the ability to index different types of content, Elasticsearch has found application in multiple use cases such as:
- Enterprise search
- Logging and log analytics
- Application search
- Business analytics
- Geospatial data analysis and visualization
How does it work?
Rather than storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialised as JSON documents. Each document consists of a set of keys (names of fields or properties in the document) and their corresponding values (strings, numbers, booleans, dates, arrays of values, geolocations, or other types of data). It uses a data structure called an inverted index that lists every unique word that appears in any document and identifies all of the documents each word occurs in.
Field types — Analyzed or Non-analyzed
String literals in elasticsearch are either analysed or non-analysed. So what exactly does analysed mean? Analysed fields are those, that go through an analysis process before being indexed. The results of this analysis is then stored in the inverted index. The analysis process basically involves tokenising and normalising a block of text. The fields are tokenised into terms, and the terms are converted to lowercase letters. This is the behaviour of a standard analyser, which is the default. However we can specify our own analyser if the need arises, for example, if you want to index special characters as well, which is not done in case of the standard analyser.
 Image credits : Elasticsearch indexing
Image credits : Elasticsearch indexingGET _analyze
{
"analyzer": "standard",
"text" : "Just trying to understand the ANALYZER!"
}
Elasticsearch’s standard analyzer will convert this text into the following
{
"tokens" : [
{
"token" : "just",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "trying",
"start_offset" : 5,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "to",
"start_offset" : 12,
"end_offset" : 14,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "understand",
"start_offset" : 15,
"end_offset" : 25,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "the",
"start_offset" : 26,
"end_offset" : 29,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "analyzer",
"start_offset" : 30,
"end_offset" : 38,
"type" : "<ALPHANUM>",
"position" : 5
}
]
}A quick intro on Wildcard searches
Wildcards are special characters that act as a placeholder for unknown characters in a text value and are handy for locating multiple items with similar, but not identical data. Wildcard searches are based on character pattern matching between the characters mentioned in the query and words in documents that contain those character patterns.
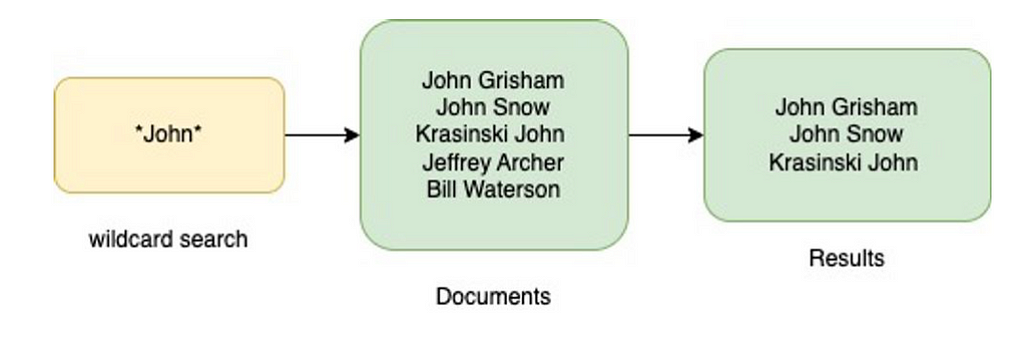 Find everyone who first/last name is John
Find everyone who first/last name is JohnNow that we have a basic understanding of how elasticsearch works, what analysed fields and wildcard searches are, let’s dig deeper into the main theme of this article — string fields and running wildcard searches on it.
String fields and Wildcard search
Each field in elasticsearch has a field data type. This type indicates the kind of data that the field contains, such as strings or boolean values, and its intended use. Two of the field types available for strings in elasticsearch are — text (default) and keyword. The primary difference between them is that text fields are analysed at the time of indexing while keyword fields are not. What that means is, text fields are normalised and broken down into individual tokens before being indexed while keyword fields are stored as it is. Also, as text fields are normalised, they support case insensitive search. To achieve the same for keyword fields, we’ll have to define a normaliser at the time of index creation and then specify the same while defining the field mappings.
PUT /demo-index-normalizer
{
"settings":{
"analysis": {
"normalizer": {
"lowercase_normalizer": {
"type": "custom",
"char_filter": [],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
},
"mappings": {
"properties": {
"text-field": { "type": "text" },
"keyword-field": {
"type" : "keyword",
"normalizer": "lowercase_normalizer"
}
}
}
}
Now coming to wildcard queries, consider we have the following document and we want to run a couple of wildcard searches on it
{
"text-field": "Mockingbirds don’t do one thing but make music for us to enjoy.",
"keyword-field": "They don’t eat up people’s gardens, don’t nest in corncribs, they don’t do one thing but sing their hearts out for us."
}Queries such as the following will work fine with text fields.
"query": "text-field:*birds*"
However, this won’t.
"query": "text-field:*birds*music*"
Reason being, the words of this field have been analysed and stored as tokens. Hence, elasticsearch couldn’t find a token corresponding to the given expression.
However, this works in case of keyword fields, since they are stored as it is.
Now, let us discuss another string field that was introduced from ElasticSearch v7.9 — wildcard. This is a specialised field type that is mainly used for unstructured machine generated content.
Following are the performance stats of running a couple of wildcard queries on these 3 field types:
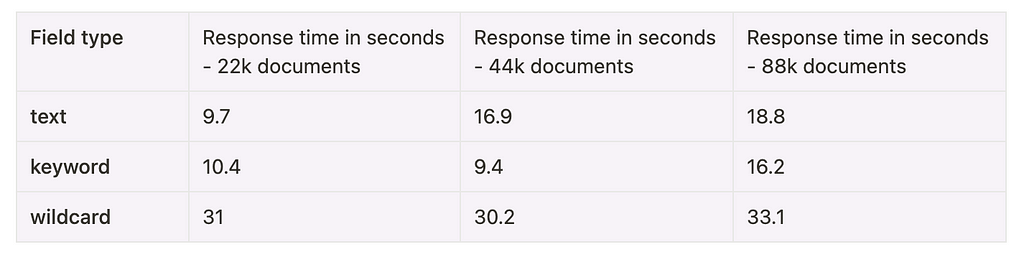 Query : *Elasticsearch* — Full word search
Query : *Elasticsearch* — Full word search Query : *Wal* — Substring search
Query : *Wal* — Substring search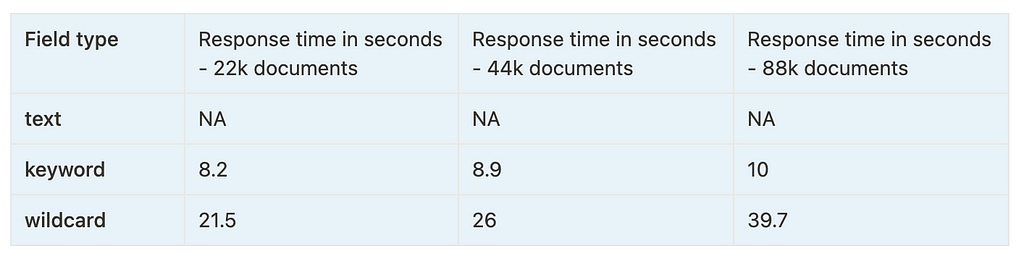 Query : *Elastic*stash* — Search across multiple words
Query : *Elastic*stash* — Search across multiple wordsAs we can clearly see, the performance of keyword field is the most consistent across all the search queries and index size. Text fields also do a decent job, but they can’t be used for searching for values like *Elastic*stash*, which makes keyword type a clear winner.
Why introduce wildcard fields then? Well, wildcard fields were introduced to address the following limitations that exist for text and keyword fields:
- Text field — Limits matching of any wildcard expressions to individual tokens rather than the original whole value held in a field.
- Keyword field — Keyword fields are slow when it comes to searching for substrings and when there are many unique values. Keyword fields also have the disadvantage of data size limit. The default string mapping ignores strings longer than 256 characters. This can be extended until the hard Lucene limit of 32k for a single token. This might create a problem when you’re trying to search through system logs and similar documents.
The wildcard field takes care of the above mentioned limitations. It does not treat strings as a collection of tokens separated by punctuation and performs pattern matching by first doing an approximate match on all the documents and then applying the detailed comparison on the subset of documents received via the match.
Detailed comparison between text, keyword and wildcard fields can be read here.
The stats mentioned have been obtained by running search on an elasticsearch index running on v8.9 with the following mapping
{
"wildcard-search-demo-index": {
"mappings": {
"properties": {
"field1": {
"type": "text"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "wildcard"
}
}
}
}
}The documents indexed had uniform data across all fields, i.e, all the 3 fields in a document had the same value. For example,
"hits": [
{
"_index": "wildcard-search-demo-index",
"_type": "_doc",
"_id": "vlPiHYYB6ikeelRg4I8n",
"_score": 1.0,
"_source": {
"field1": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices.",
"field2": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices.",
"field3": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices."
}
},
{
"_index": "wildcard-search-demo-index",
"_type": "_doc",
"_id": "v1PiHYYB6ikeelRg4I87",
"_score": 1.0,
"_source": {
"field1": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds.",
"field2": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds.",
"field3": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds."
}
}
]
To sum up, there is no fixed rule on selecting the type of a field. It depends on multiple factors such as the type of data, the different set of use cases that have to be covered, etc.
Deciding on the field type is a very crucial factor while setting up a data store as it highly impacts the performance and should be decided by considering all possible scenarios and factors.
Elasticsearch also has a query type called wildcard that can be used to run wildcard queries. We’ll discuss that in another article along with a performance comparison against the method used in this article.
ElasticSearch : Wildcard searches was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: ElasticSearch : Wildcard searches | by Nupur Banerjee | Walmart Global Tech Blog | Aug, 2023 | Medium