DuckDB vs. The Titans: Spark, Elasticsearch, MongoDB — A Comparative Study in Performance and Cost
A mini-guide about Duck as an Engine
 Photo credit: Pixabay
Photo credit: PixabayDuckDB is a rising star in the realm of database management systems (DBMS), gaining prominence for its efficient columnar storage and execution design that is optimized for analytical queries. But how does it stack up against industry veterans like Apache Spark, Elasticsearch, and MongoDB? In this article, we will dive into a comparative study, examining their performance and cost implications.
Agenda
- What is DuckDB?
- The Titans: Apache Spark, Elasticsearch, and MongoDB
- Performance Comparison
- Cost Analysis
- Case Studies and Limitations
- Duck as an Engine with Databathing
- Summary
What is DuckDB?
DuckDB is an in-process SQL OLAP database management system
Its core strengths lie in three essential characteristics — analytical processing, in-memory operations, and a column-oriented structure, making it akin to what SQLite is for PostgreSQL, DuckDB is for Redshift, Snowflake, and others.
However, DuckDB is not without its limitations. Its scalability is relatively limited, and it is not optimized for heavy data writing workloads. Its application in production environments is also restricted due to its newness in the market. Moreover, as it is an in-memory system, DuckDB’s performance may degrade or become infeasible for datasets larger than the available memory.
The Titans: Apache Spark, Elasticsearch, and MongoDB
These three tools have now become industry mainstays, with numerous companies employing them to accelerate their data processing and searching capabilities.
Apache Spark is an open-source distributed computing system known for its speed, versatility, and sophisticated analytics.
Elasticsearch is a robust search and analytics engine.
MongoDB is a source-available, NoSQL database program offering a flexible, JSON-like document model.
Performance Comparison
To gain a deeper understanding of DuckDB, we’ll conduct a performance analysis involving three types of data processing tasks.
For Apache Spark, our test setup involves a ‘n1-standard-16’ master with ten ‘n1-standard-32’ workers. For DuckDB, we’ll utilize a ‘n2d-highmem-16’.
Our testing scenario involves two tables:
- T1: A table with 500 million records spanning 80 columns, totaling approximately 30GB of data.
- T2: A table with 5 million records across 60 columns, totaling around 8GB of data.
The three operations we’ll analyze are as follows:
- Aggregation: This involves various operations like WHERE, GROUP BY, HAVING, MAX, AVG, etc.
- Join: We join T1 and T2 in this test with a limited column selection.
- Search: Here, we search T2 using a single column ID.
You can find all the detailed information in the table below.
| Type | Data Size | VM (Spark) | VM (DuckDB) |
|--------|:-----------------------:|:------------------------:|:------------------:|
| Agg | T1:500M, 30G | n1-standard-16/32 (1+10) | n2d-highmem-16 (1) |
| Join | T1:500M, 30G; T2:5M, 8G | n1-standard-16/32 (1+10) | n2d-highmem-16 (1) |
| Search | T2:5M, 8G | n1-standard-16/32 (1+10) | n2d-highmem-16 (1) |
Table 1: Type, Data Size and Parameters of VM
Post completion of our tests, we’ve gathered performance metrics for Apache Spark, MongoDB, BigQuery (BQ), Elasticsearch, DuckDB with external tables (DuckDB ext.), and DuckDB with internal tables (DuckDB int.) across all three types of data processing. The details of these metrics can be found in Table 2.
-- Table
| Type | Spark | Mongo | BQ | ES | DuckDB ext. | DuckDB int. |
|--------|-------|-------|----|-------|-------------|-------------|
| Agg | 28.8 | 5 | 16 | -- | **0.7** | ---- |
| Join | 130 | -- | 47 | | 10 | **8** |
| Search | 7.58 | -- | 2 | 0.015 | 0.2 | **0.014** |
Table 2: performance metric among all candidates
* All units are in seconds.
In summary, DuckDB outperforms the other database systems in these three operations, especially in its internal configuration. This might be due to its in-memory and columnar architecture, making it a strong candidate for aggregation, join, and search operations tasks.
Cost Analysis
Beyond performance, cost-effectiveness is a crucial factor that warrants consideration.
| | VM (Spark) | Mongo | ES | VM (DuckDB) |
|--------------------|:-----------------:|:-----------:|:--:|:--------------:|
| VM | n1-standard-16/32 | RU: 400,000 | -- | n2d-highmem-16 |
| Cost (dollar/hour) | 55.64 | 5.5 | 11 | **1.02** |
Table 3: Cost for different methods
* All units are dollar/hour.
The cost for running Apache Spark, MongoDB, Elasticsearch, and DuckDB, predicated on the selected Virtual Machine (VM), can be viewed in Table 3. A more detailed examination in Table 4 reveals that DuckDB yields substantial cost savings: around 90% compared to Spark, approximately 63% to MongoDB, and about 81% to Elasticsearch.
| | Vs. Spark | Vs. Mongo | Vs. ES |
|--------|:---------:|:---------:|:------:|
| DuckDB | 98% | 63.28% | 81.64% |
Table 4: Cost Saving - DuckDB Vs. Others
In conclusion, while each of these DBMS has unique strengths in terms of capabilities and performance, DuckDB emerges as the most cost-effective option, according to this table.
Case Studies and Limitations
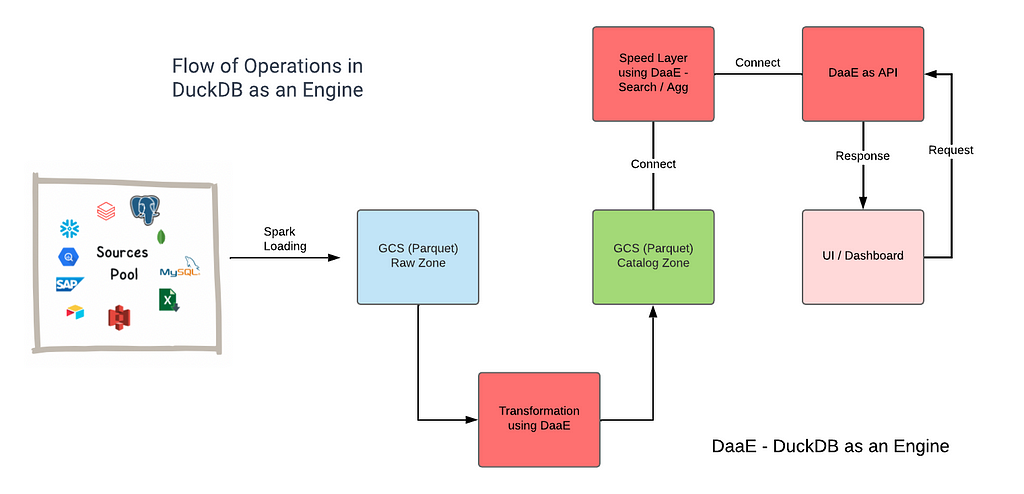 Figure 1. e2e workflow for DaaE
Figure 1. e2e workflow for DaaEDuckDB as an Engine is the concept of utilizing DuckDB as a primary tool for database management and processing in an application or system.
Figure 1 illustrates an end-to-end workflow leveraging DuckDB as an Engine. We can utilize DuckDB as an Engine (DaaE) in three specific areas: conventional ETL transformation, the speed layer for search and aggregation, and backend service-side API processing. We will delve into each of these areas in the subsequent sections.
Conventional ETL Transformation:
In the realm of ETL processes, tools like Spark or BigQuery are commonly employed for data handling. However, they can encounter certain constraints. For instance, Spark requires careful tuning to deliver effective data processing, while BigQuery can be costly when dealing with high-volume and complex queries.
DuckDB as an Engine (DaaE) offers notable solutions for performance tuning and cost-saving. As seen in Table 5, DaaE can significantly enhance performance — in most cases offering over a 90% increase — without necessitating any specific tuning. As highlighted in Table 4, DaaE also excels in facilitating cost savings.
| Type | DuckDB ext. Vs Spark | DuckDB ext. Vs BQ | DuckDB int. Vs BQ |
|------|:--------------------:|:-----------------:|:-----------------:|
| Agg | 97.65% | 95.6% | --- |
| Join | 92.30% | 78.72% | 82.97% |
Table 5: Improvement for % among DuckDB, Spark, BQ
* Improvement for %
The speed layer for search and aggregation:
Users anticipate swift responses to search requests or intricate SQL queries as data reaches the final speed layer. The table below offers a comparative analysis between DuckDB with external tables (DuckDB ext.) and MongoDB, Elasticsearch (ES), as well as DuckDB with internal tables (DuckDB int.) and Elasticsearch (ES).
| Type | DuckDB ext. Vs Mongo | DuckDB ext. Vs ES | DuckDB int. Vs ES |
|--------|:--------------------:|:-----------------:|:-----------------:|
| Agg | 86% | --- | --- |
| Search | --- | _-123%_ | 6.6% |
Table 6: Improvement for speed layer
- Aggregation: In aggregation tasks, DuckDB with an external table configuration achieves an 86% performance improvement compared to MongoDB. No comparison data are available for Elasticsearch in this category.
- Search: In search operations, we see a slightly more complex scenario. Compared to Elasticsearch, DuckDB with an external table configuration shows a performance decrement of 123%, indicating that Elasticsearch outperforms in this case. However, DuckDB, in its internal table configuration, gives a performance boost of 6.6% over Elasticsearch, which indicates the benefits of internal over external configurations for search operations in DuckDB.
Backend service-side API processing:
In data-intensive applications that offer user-facing analytics, developers often utilize backend services for data transformations, such as formatting or computations. If developers are primarily performing SQL-style processing, incorporating DuckDB as an Engine (DaaE) can significantly enhance the performance of these transformations.
Potential Constraints of DuckDB as an Engine (DaaE):
- Connection: DaaE provides a limited set of native connections, which include formats such as CSV, JSON, Parquet, among others.
- Scalability: ETL processes involving distributed processing over numerous nodes or handling extremely large datasets may necessitate alternative solutions like Apache Spark. However, this constraint may not pose a significant issue if ample memory is available.
- Write-Heavy Workloads: DaaE is primarily optimized for read-heavy operations. We need to find more solution for data streaming.
- LData Loss: For tables within the internal configuration of DaaE, there’s a need to reload data if the service encounters downtime. However, the reloading speed is typically acceptable.
Duck as an Engine with DataBathing
I plan to integrate DuckDB as an Engine (DaaE) into the DataBathing framework. This way, users can leverage the advantages of both Spark and DaaE.
If you’re unfamiliar with DataBathing, additional information can be found in the blogs listed below:
- DataBathing — A Framework for Transferring the Query to Spark Code
- Modularization Using Auto-Generated Pipeline With DataBathing
Summary
DuckDB as an Engine (DaaE) is a strong choice for certain scenarios. However, when selecting a database management system (DBMS) for your specific needs, balancing cost, performance requirements, and specific needs is critical. The optimal system will hinge on factors such as the tasks' nature, data volume, and budget limitations.
DuckDB vs. The Titans: Spark, Elasticsearch, MongoDB — A Comparative Study in Performance and Cost was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.