 Source: Markempa
Source: Markempa
Introduction
This post demonstrates the usage of Change Feed for Azure Cosmos DB (Mongo API) to design an event-driven system. Cosmos supports Mongo DB v 4.2 when this post is written. As a part of this documentation, we will keep our focus on the design of the event-driven system. If you want to know what is change feed or how to onboard a change stream for a collection I would suggest you go through Azure Cosmos official documentation.
Cosmos change feed use cases
In many ways, you can leverage Change Feed to build a custom solution that can listen to MongoDB database change events and process them. Like typical use cases mentioned in the documentation, you can push events to a scalable data ingestion platform such as Azure Event Hubs for Kafka. Additionally, you can build traditional Kafka client applications (consumer, streams API) or leverage serverless processing with Azure Functions (similar to this one).
- Triggering a notification or a call to an API, when an item is inserted or updated.
- Real-time stream processing for IoT or real-time analytics processing on operational data.
- Data movements such as synchronizing with a cache, a search engine, a data warehouse, or cold storage.
The change feed in Azure Cosmos DB enables you to build efficient and scalable solutions for each of these patterns, as shown below image-
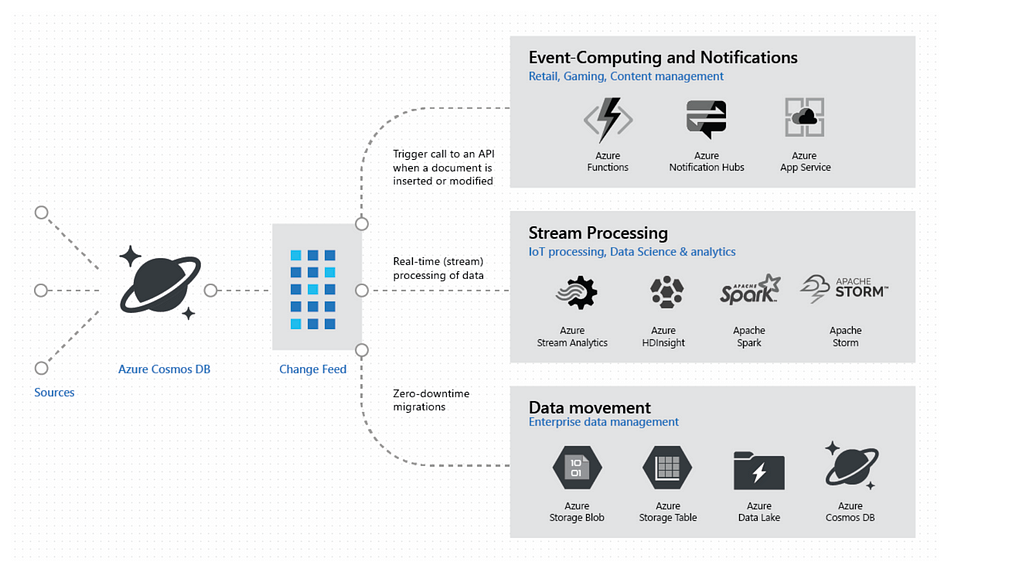 Source: Azure Cosmos
Source: Azure CosmosWhat is Oplog and Watch Function?
Throughout our architecture discussion, I will use Oplog and Watch Function. So here is a brief about Oplog and Watch Function
OPlog: oplog is a special collection that keeps a rolling record of all operations that modify the data stored in databases. All the operations that affect data will be saved here.
Watch Function: It uses information stored in the oplog to produce the change event description and generate a resume token associated to that operation.
High-Level Design
From Azure Cosmos Offical Document Cosmos‘s API for MongoDB(v 4.2) does not have any inbuilt Change Feed Processor Library to consume the change streams.
So we have to implement some kind of system that will consume events from Oplog and trigger an event. It is very similar to reading from a text file through a cursor and notifying about the file content.
- Consume Changes: The application reads changes from Oplog through the Watch Function. The application will have a background job running on an independent thread to continuously check if is there any new change record in Oplog and read the log to trigger an event. This is a pull-based model.
- Trigger Events: After consuming event change events from the Oplog application trigger events based on these changes.
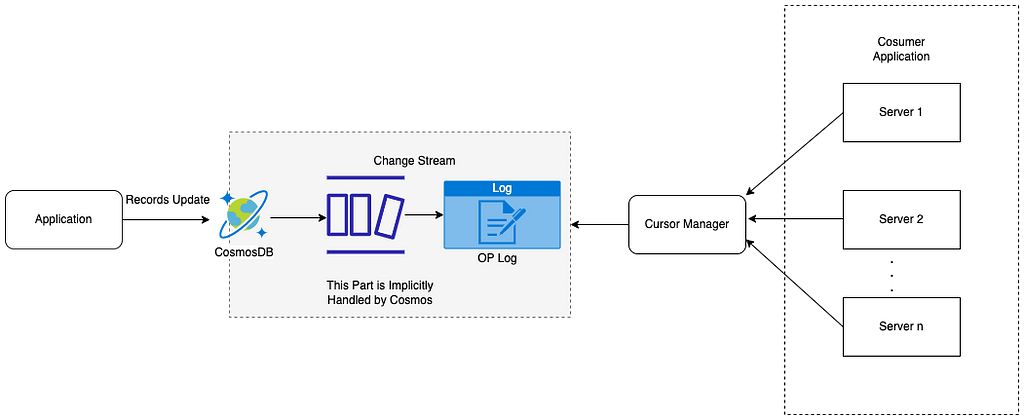 Cosmos Change Feed High-Level Diagram
Cosmos Change Feed High-Level DiagramConstraints of change feed as Event Driven system
If the Consumer Application is hosted on a single server, the design logic will be very straightforward to get the newly changed records from Oplog and trigger events. Here the application does not need to handle one of the main problems of multiple server reads and to make sure one event is triggered against one db record update. But nowadays high availability and fault tolerance are very important mandatory requirements for any application. So it is common that most of the applications are hosted on multiple servers and in different regions. Now the first limitation that we have to resolve during event-driven system design is how multiple servers can read from a single change feed and trigger single events in near real-time. Multiple servers should read from a single Oplog in such a way as
- At a time only one server should be active and all the other servers should be in passive mode to make sure always a single event will be triggered for a single db record change feed.
- After processing, each event server should also update the last read point so that the next active server can resume from the following read point to avoid any duplicate read as much as possible.
- We should rotate the workload between all the servers to make sure the task is evenly distributed across all the servers.
- Make the system highly reliable by detecting faulty server nodes and making another server active if the current active server stops or goes to a dead state.
- Prevent any data loss.
While designing an event-driven system, we have to overcome all the limitations mentioned above.
Handling the constraints
Managing multiple servers to access Oplog:
We can use a resource lock mechanism to make sure at a time only one server remains active. The server that has acquired the resource lock only can read data from the Oplog. For example, one application is hosted on three servers and the application is reading Change Feed from Oplog to trigger events. I have listed all the scenarios that should be addressed while using resource lock to control access to change feed from Oplog.
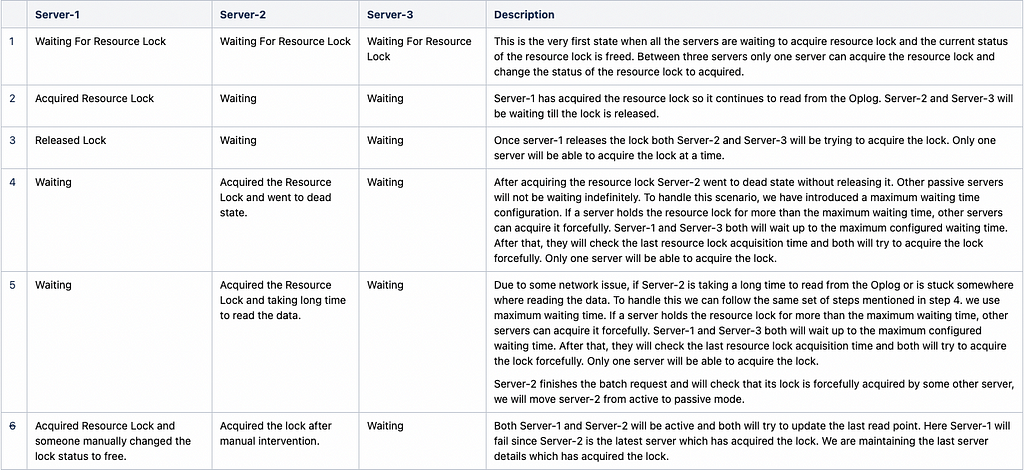 Table to handle different resource lock scenarios
Table to handle different resource lock scenariosResource Lock should be accessible from all the servers. That’s why it needs to be a Global Lock. Store the global lock in a separate lease collection and all the servers should have read and write access. The schema definition of a resource lock is described below-
{
“_id”:<name of the main source collection>,
“lastResourceLockAcquireTime”: <Last resource lock acquire time>,
“isResourceLockFree”: <This is the resource lock>,
“serverUniqueId”: <Server id which currently has acquired resource lock>
}Tracking the last read point
By default, the change stream only watches from the time it has made the connection to the database server. When any server is consuming from a change stream it is essential to keep track last read point to handle failures like the server going to a dead state or taking a longer time to respond. Here Resume Token can help to address the above issue.
What is Resume Token?
Each change stream event has a unique token associated with it called Resume Token. Resume token allows you to continue processing from where you left off — think of its as taking checkpoint. If the processing application stops (or server crashes), it might not be desirable to miss the database changes which happened during this period. You can use the resume token to ensure that the application starts off from where it left off and is able to detect change events during the time period for which it was not operating. In addition to this, if you have a history/changelog of resume tokens, you have the flexibility of choosing from any of these (it’s like walking back in time) and (re)process data from that point in time.
To track the last read point active server always keeps the resume token updated after processing the change event. When another server becomes active it starts the reading from the latest resume token. Now the question is where to keep the resume token so that any server can read and update it. Every time a global resource lock is acquired resume token is also needed to start the processing of change event. So best place to save the resume token is with the Global Resource Lock that I have discussed above. So we can store the resume token in the resource lock schema which is defined above.
Resume token is a critical point. If somehow it got corrupted or deleted, we will lose all the changes. So based on your use case, you can take a backup of the resume token like in Azure Blob storage for some longer time interval. As we are storing both Resume Token with Resource Lock together, will modify the existing Resource Lock schema.
{
“index”:<name of the source main collection>,
“lastUpdateTs”: <last resume token update time>,
“lastResourceLockAcquireTime”: <Last resource lock acquire time>,
“isResourceLockFree”: <Status of resource lock- True/False>,
“serverUniqueId”: <Server id which currently has acquired resource lock>,
“resumeToken”:{} <Resume Token>
}Check Resource Lock status
Whenever an active server acquires releases the resource lock, other passive servers should be aware of it. In the previous section, it is already mentioned that we are storing resource lock and resume token together in a different Mongo collection. Let’s assume the name of the new collection where all these metadata (e.g. resource lock, resume token) will be stored — mongo-lease-collection. Now we can implement this using either of below two approaches-
- Implement a poller that will continuously check the current status of the resource lock from mongo-lease-collection.
- We can check the resource lock status in mongo-lease-collection’s Oplog. Instead of continuously checking the status of the collection, we can wait for the change event generated from the Oplog of mongo-lease-collection.
Approach 2 is more efficient here because it will remove the effort of unnecessary collection read calls and at the same time, it will save RU costs. So other inactive servers will be listening events from mongo-lease-collection and whenever there is a free resource lock event inactive servers will try to acquire the resource lock to be active. Here multiple servers will try to acquire the resource lock and we have to make sure only one server can be active. We can leverage any mongo db atomic operation that supports reading and updating a single document to make sure resource lock is acquired by only one server. We have discussed it in our sample code.
Handling duplicate records
As I have mentioned earlier, the active server reads from Oplog as a batch and processes the batch of change events. After processing the batch, it updates the resume token to the last read point. If the active server dies or stops working while processing the events, another passive server will forcefully acquire the resume token. In this case, there is a probability that the newly active server reprocesses some records from the ongoing batch of events. There is a possibility of duplicate records. If your application is very much sensitive to duplicate events or you don’t have any other way to identify duplicate events, you can configure batch size as one. Then it will resolve the duplicate record issue because now your active server will read a single record at a time, process it and update the resume token.
Distribute the load between all the servers
We can distribute the workload between all the servers by rotating the resource lock. Set a maximum execution time limit for all servers. In my case, the maximum allowed execution time for a server is set to 30 min. Here this execution time is configurable based on application requirements. In my case, the maximum processing time for a single batch event is 5 sec and the batch size is 12. We are keeping a buffer time of 1 min (12*5 Sec) to complete any pending task like completing the processing of the last batch of records or releasing the resource lock. So the total execution time out is (30+1)min = 31 min. This one-minute buffer time will help to avoid any unnecessary race conditions between servers like acquiring the lock before it gets released. Uses the same execution timeout(31 min) to handle cases mentioned in the Table to handle different resource lock scenarios (Points 4 & 5) when the server dies or takes a long time to process.
LLD with pseudocode
Here is a diagrammatical representation of the complete LLD of the Event Driven System. For example, we have a User Management System and we want to send a notification email in an asynchronous way when there is any change in the users-info mongo collection.
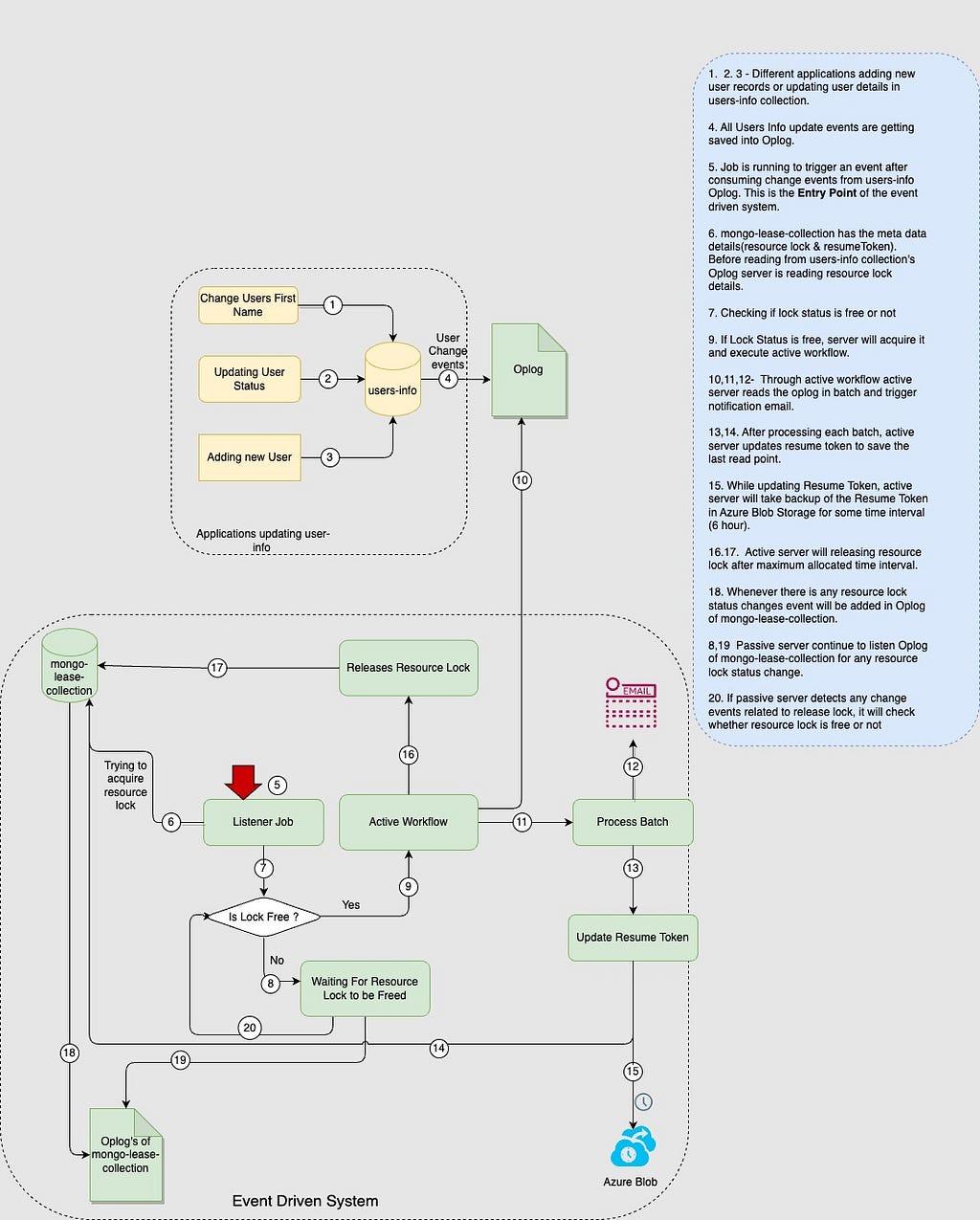 Low-Level Flow
Low-Level FlowAtomic Operation supported by Cosmos MongoDB:
We are dealing with resource lock. We need some atomic operation to make sure at a time only one server can acquire the resource lock. Mongo API for Azure Cosmos provides findOneAndUpdate method. This is an Atomic Operation that can be used to check and update the current status of the resource lock. We are using it to find and acquire a resource lock.
Pseudocode
Pseudocode of starting point
/
* This is the entry point. On an independent thread each server will
* continuously check the resource lock status and executes next step as
* per the resource lock status.
*/
Call() {
while(true) {
switch(checkResourceLockStatus()) {
case : FREE
active();
case : BUSY
wait();
case : EXPIRED
acquireLock();
}
}
Pseudocode for Active Server
// Maximum Processing time is 30 min.
active() {
try{
cursor = getMongoChangeStreamCursor(collectionName);
startTime = Instant.now();
while((currentTime-startTime)< = MAXIMUM_ALLOWED_PROCESSING_TIME) {
// For our case we are using batchSize 1 for low traffic. We can use any batch size if needed.
batchlist= getBatchList(cursor, batchSize);
process(batchlist)
validateResumeTokenHasAccess();
updateResumeToken(batchlist);
} catch (Exception e) {
//Log Error
} finally {
releaseResourceLock();
}
}
Pseudocode to check Resource Lock status
/
* Continuously listening to mongo-lease-collection change stream to check the
* Resource Lock status.
*/
MongoChangeStreamCursor<ChangeStreamDocument<Document>> cursor = mongoDbTriggerDao.watch(collectionName));
lastAcquireTimeMs = getLastAcquireTimeMs(resourceLockDetails);
try {
while (true) {
/
* Checking if resource lock is expired or not to handle if a server holds
* resource lock and dies or taking time to process batch.
*
* Buffer Time : It is for avoiding any unnecessary race condition. You
* can set buffer time as per our application use case.
* maxExecutionTime : Maximum allowed time a server can keep to itself
*/
if (checkIfResourceLockIsExpired(lastAcquireTimeMs, bufferTime, maxExecutionTime) == EXPIRED) {
//If resource lock is expired than try to acquire the resource lock forcefully
if (tryingToAcquireRecourseLockForceFully(lastAcquireTimeMs)) {
return;
}
}
ChangeStreamDocument<Document> csDoc = cursor.tryNext();
if (csDoc != null) {
Document document = csDoc.getFullDocument();
boolean isResourceLockFree = document.getBoolean(Constants.IS_RESOURCE_LOCK_FREE);
if (!isResourceLockFree) {
//If resource lock is acquired by some other server then update the lastAcquireTimeMs.
//This is needed for checking if lock is expired or not.
lastAcquireTimeMs = document.getLong(Constants.LAST_RESOURCE_LOCK_ACQUIRE_TIME);
continue;
}
if (acquireReourceLock()) {
return;
}
}
}
Pseudocode to make sure single ownership of Resource Lock
/
* Changes to make sure only one server can acquire the resource.
*
* Here first finding if IS_RESOURCE_LOCK_FREE is true and after acquiring
* the lock updating IS_RESOURCE_LOCK_FREE with false.
*/
public Document acquireReourceLock() {
try {
Bson idFilter = eq(ID, collectionName);
Bson resourceLockFilter = eq(IS_RESOURCE_LOCK_FREE, true);
Bson filter = and(idFilter, resourceLockFilter);
Update update = new Update();
update.set(IS_RESOURCE_LOCK_FREE, false);
update.set(LAST_UPDATE_TS, Instant.now());
//findOneAndUpdate is an atomic operation.
return mongoCollection.findOneAndUpdate(filter, update.getUpdateObject());
}
}
Advantages of using Mongo Change Stream
RU units will be consumed while reading change events from Oplog for any collection. If you have limited RU and it’s fully consumed by CRUD operations, Cosmos DB will deprioritize the Change Feed processing and process it later when RU units become available. This is because Cosmos DB is designed to prioritize CRUD operations over Change Feed processing. Therefore, no autoscaling or throughput management is needed for Change Feed processing in Cosmos DB. The system will automatically manage and prioritize the workload based on available resources.
Some points regarding Mongo Change Stream
- At a time, multiple applications can process the mongo stream of one collection. However the application owners have to maintain the Resource Lock and Resume token state separately for each application.
- There is no expiry of the resume token.
- You can read the change feed as far back as the origin of your container.
- The delete event is not supported by Cosmos for Mongo API. No change events will be available in Oplog for any deleted records.
- If you delete a collection or database and recreate the collection\database with the same name, your old resume token will not work
How to handle delete events?
Currently, the change feed doesn’t log delete events. You can add a soft marker on the items that are being deleted. For example, you can add an attribute in the item called “deleted” set it to “true” and set a TTL on the item, so that it can be automatically deleted. You can read the change feed for historic items (the most recent change corresponding to the item, it doesn’t include the intermediate changes), for example, items that were added five years ago. You can read the change feed as far back as the origin of your container but if an item is deleted, it will be removed from the change feed.
Limitations of Oplog
You can’t filter the change feed for a specific type of operation (like insert or update). All the insert and update events will be available in the change feed. One possible alternative is to add a “soft marker” on the item for updates and filter based on that when processing items in the change feed.
Reference
- https://docs.microsoft.com/en-us/azure/cosmos-db/sql/change-feed- processor
- https://learn.microsoft.com/en-us/azure/cosmos-db/mongodb/change-streams?tabs=java#examples
- https://learn.microsoft.com/en-us/azure/cosmos-db/nosql/change-feed-processor?tabs=dotnet
- https://learn.microsoft.com/en-us/azure/cosmos-db/nosql/change-feed-design-patterns?tabs=latest-version
Working with the change feed - Azure Cosmos DB
Design Event Driven System Using Azure Cosmos Change Feed for Mongo API was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Design Event Driven System Using Azure Cosmos Change Feed for Mongo API | by Subhadeep Dey | Walmart Global Tech Blog | Medium