Deploying RAGs in production — Part 2
Authors: Chinmay Jain, Osheen Nayak
In the preceding section, we delved into the diverse elements of a RAG, set up a basic RAG, and explored the algorithms and benefits of advanced RAG systems.
Now, we will shift our focus to implementing RAG in a production setting, where we will navigate through the installation and configuration of various components and tools. Additionally, we will highlight the process of validating a RAG using TruLens, a tool designed to provide insights into the inner workings of deep learning models.
To grasp this aspect, we will establish a ‘survey playground’, essentially a Q&A chatbot that utilizes store survey data. This data is comprised of tabular information from various types of surveys, such as store surveys, e-commerce surveys, returns, and so on. The data includes fields such as the survey date, store number, and customer comments.
This application is a valuable tool for store managers to analyze feedback on numerous aspects of their store, such as cleanliness, staff performance, issues with returns, etc. Furthermore, it allows them to compare and contrast their feedback with that of other stores, facilitating the identification and implementation of necessary improvements.
This application simplifies the task for the store manager by providing a summarized report of survey feedback over various periods such as the last week, three months, or six months. This saves them from the arduous task of manually sifting through hundreds of customer comments.
Vector Database
Vector databases, essential for managing vector embeddings in machine learning and data analysis, offer efficient nearest neighbor search and scalable indexing. They also integrate well with various data types, providing a unified data management platform. Open-source databases like FAISS, Annoy, and Milvus offer scalability and efficiency. Paid services such as Pinecone and Vector.ai provide advanced features and dedicated support.
Milvus stands out among these databases as an open-source vector database designed for managing, indexing, and searching massive vector data. It is built with flexibility, reliability, and speed in mind, providing a comprehensive solution for feature extraction, storage, and search. It is particularly useful in retrieval-augmented generation (RAG), a method that combines the benefits of retrieval-based and generative models. Milvus can store and retrieve vectors representing different information pieces, thereby speeding up the process.
Milvus boasts several advantages over other databases. It is scalable, capable of handling large-scale datasets, and supports distributed search and computing. Efficiency is a key highlight, with high-speed vector similarity searches powered by advanced indexing techniques. Milvus is also highly flexible, supporting a wide range of machine learning algorithms and vector data types, making it adaptable to various use cases.
Setting Up Milvus
Our first step will be to install the Python Software Development Kit (SDK) for Milvus, known as PyMilvus, using pip3. This will give us access to all the tools we need to interact with Milvus.
Next, we’re going to import some essential modules from PyMilvus. We’ll bring in ‘connections’, ‘Collection’, ‘FieldSchema’, ‘CollectionSchema’, and ‘DataType’. With these modules, we’ll be able to establish a connection, create collections, and define the schema of those collections in Milvus.
Once we’ve set everything up, it’s time to make a connection to our Milvus server. We’ll use the ‘connections.connect()’ function for this.
Make sure to replace “host_name”, “8080”, “<user_name>”, and “<password>” with your own Milvus server details. Ready? Let’s dive right in!
Install Milvus
pip3 install pymilvus
Import all the required Libraries
from pymilvus import connections, Collection
from pymilvus import FieldSchema, CollectionSchema, DataType
Connect to milvus
connections.connect(host = “host_name”, port = “8080”, user = “<user_name>”, password = “<password>”)
Creating a milvus collection for tabular data
Next, we’ll define our collection’s schema. We’ll set up a list of fields, each with specific properties such as name, data type, and whether it’s a primary key and the maximum length for certain data types.
We’re defining fields like ‘id’, ‘response_id’, ‘store’, ‘date’, ‘content’, and ‘text_embedding’. After that, we’ll use the ‘CollectionSchema’ function to define the schema for our collection, which we’ll describe as ‘Tabular search’.
Define the schema for the collection
fields = [
FieldSchema(name = “id”, dtype = DataType.INT64, is_primary = True, auto_id = False),
FieldSchema(name = “response_id”, dtype = DataType.INT64),
FieldSchema(name = “store”, dtype = DataType.INT64),
FieldSchema(name = “date”, dtype = DataType.VARCHAR, max_length=20),
FieldSchema(name = “content”, dtype = DataType.VARCHAR, max_length=10000),
FieldSchema(name = “text_embedding”, dtype = DataType.FLOAT_VECTOR, dim = 768)]
schema = CollectionSchema(
fields,
description=”Tabular search”
)
Adding data to the collection
collection_name = “Tabular search”
cln = Collection(collection_name, schema)
df = pd.read_csv(“data.csv”)
cln.insert(df)
Creating Text Embeddings
In this example we use Gecko embedding from vertex AI. Gecko embedding is a compact and versatile text embedding model that leverages the knowledge of large language models (LLMs) through a two-step distillation process. The main idea is to generate diverse synthetic data using LLMs and then refine the data quality by retrieving and relabeling positive and negative passages using the same LLMs.
We’ll start by importing necessary modules from the `vertexai.language_models` package, and the `typing` module for type hinting.
We then define a function, `embed_text()`, which will be used to transform our text data into a numerical representation (or embedding) using a pre-trained model. This function takes a list of texts and other optional parameters like the model name and dimensionality.
Within this function, we load our pre-trained model using `TextEmbeddingModel.from_pretrained()`, create an `TextEmbeddingInput` object for each text, and then generate the embeddings using the `get_embeddings()` method of our model. This function will return a list of the embeddings.
After defining this function, we’ll load a CSV file named `data.csv` into a DataFrame using pandas. We’ll then create a new column, `text_embedding`, in our DataFrame by applying the `embed_text()` function to our text data.
Finally, we save our DataFrame back to the `data.csv` file.
from typing import List, Optional
from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel
def embed_text( texts: List[str] ,task = “RETRIEVAL_DOCUMENT”,model_name = “text-embedding-004”,dimensionality = 768,
) :
“””Embeds texts with a pre-trained, foundational model.”””
model = TextEmbeddingModel.from_pretrained(model_name)
inputs = [TextEmbeddingInput(text, task) for text in texts]
kwargs = dict(output_dimensionality=dimensionality) if dimensionality else {}
embeddings = model.get_embeddings(inputs, **kwargs)
return [embedding.values for embedding in embeddings]
df=pd.read_csv(“data.csv”)
df [“text_embedding”]=embed_text(list(df[content]))
df.to_csv(“data.csv”,index=False)
Search in the collection
Navigating through a collection is a straightforward process. Firstly, we take the query posed by the user and transform it into an embedding utilizing Vertex AI. Following this, we proceed to scour the collection in Milvus, pinpointing the top 100 results that display the greatest similarity to the initial query.
Question = “What is HSNW?”
search_params = {
“metric_type”: “IP”,
}
# Load the collection
collection = Collection(collection_name)
# Perform the search
results = collection.search(
data = embed_text([question]),
anns_field = vector_field_name,
param = search_params,
limit = 100,
consistency = ‘Strong’,
output_fields = [“store”, “response_id”, “date”,”content”]
We can also use filters in Milvus. This enables us to initially sift the data in line with a particular query before carrying out a semantic search. Subsequently, the results, along with the user’s query, are fed into a Language Model (LLM) using a specific prompt. This process allows us to generate the final response.
# Search for the k nearest neighbors
filter_query= f”(date> ‘{start_dt}’ && date< ‘{end_dt}’) && (store in {store_number})”
Question = “What is HSNW?”
search_params = {
“metric_type”: “IP”,}
# Load the collection
collection = Collection(collection_name)
# Perform the search
results = collection.search(
data = [embedding_output(question)],
anns_field = vector_field_name,
param = search_params,
limit = 100,
consistency = ‘Strong’,
output_fields = [“store”, “response_id”, “date”,”content”],
expr = filter_query,
Prompt = “Context provided: “”” + str(result) +”””
Here is the question you need to answer: “”” + str(question) +”””
Don’t return duplicates.
Return around 5 points mostly, unless there are more relevant points
Don’t return dictionary or list unless asked.
Be concise.“
Using LLM
Finally, the generated prompt is processed through a LLM to get the answer to the User query. We use Element, Walmart’s own AI platform which provides an option to select from a variety of LLMs. For the purpose of this application, we have chosen to use the GPT-4 model with a context length of 8192.
The final response is an answer generated by an LLM which is enhanced by the usage of augmented retrieval earlier.
We architect our application by integrating a suite of technologies including Milvus, Vertex AI, and Language Learning Models (LLMs), all operating on an infrastructure that utilizes Retriever-Augmented Generation (RAGs). Now that we have gained proficiency in creating and deploying a RAG-based application in a production environment, our next step is to learn how to validate a RAG. This will allow us to evaluate its performance effectively.
Validating RAGs using Trulens
RAGs have become the standard architecture for providing LLMs with context to avoid hallucinations. However, even RAGs can suffer from hallucination, as is often the case when the retrieval fails to retrieve sufficient context or even retrieves irrelevant context that is then weaved into the LLM’s response.
TruLens is a tool designed to provide interpretability for deep learning models. It offers a suite of attribution methods that can explain the output of a model in terms of its input features. This can be helpful for understanding, debugging, and improving model performance. TruLens can be particularly useful for validating RAG as it can provide insights into how the model is making its predictions.
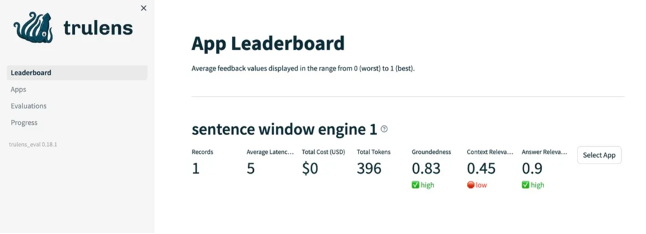
Before we delve deeper, let’s familiarize ourselves with the key evaluation metrics of the Retriever-Augmented Generation (RAG) triad.
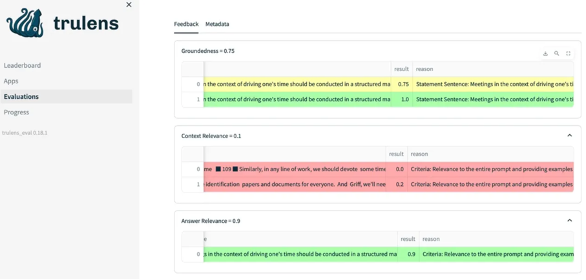
This triad consists of three important evaluations: Context Relevance, Groundedness, and Answer Relevance. The Context Relevance refers to how closely the retrieved information aligns with the given query. Groundedness measures the degree to which the generated response is based on the retrieved information, ensuring it doesn’t stray from the facts. Lastly, Answer Relevance assesses how accurately the generated response answers the query.
A satisfactory score on each of these evaluations instills confidence in us that our Language Learning Model (LLM) application is free from any sort of ‘hallucination’, or false generation. Now, let’s dive into more details.

Context Relevance
The first step of any RAG application is retrieval; to verify the quality of our retrieval, we want to make sure that each chunk of context is relevant to the input query. This is critical because this context will be used by the LLM to form an answer, so any irrelevant information in the context could be weaved into a hallucination. TruLens enables you to evaluate context relevance by using the structure of the serialized record.
LLM query for Context Relevance
system_prompt:
“””You are a RELEVANCE grader; providing the relevance of the given CONTEXT to the given QUESTION.
Respond only as a number from 0 to 10 where 0 is the least relevant and 10 is the most relevant.
A few additional scoring guidelines:
- Long CONTEXTS should score equally well as short CONTEXTS.
- RELEVANCE score should increase as the CONTEXTS provides more RELEVANT context to the QUESTION.
- RELEVANCE score should increase as the CONTEXTS provides RELEVANT context to more parts of the QUESTION.
- CONTEXT that is RELEVANT to some of the QUESTION should score of 2, 3 or 4. Higher score indicates more RELEVANCE.
- CONTEXT that is RELEVANT to most of the QUESTION should get a score of 5, 6, 7 or 8. Higher score indicates more RELEVANCE.
- CONTEXT that is RELEVANT to the entire QUESTION should get a score of 9 or 10. Higher score indicates more RELEVANCE.
- CONTEXT must be relevant and helpful for answering the entire QUESTION to get a score of 10.
- Never elaborate.”””
user_prompt:
“””QUESTION: {question}
CONTEXT: {context}
RELEVANCE: “””
Groundedness
After the context is retrieved, it is then formed into an answer by an LLM. LLMs are often prone to stray from the facts provided, exaggerating or expanding to a correct-sounding answer. To verify the groundedness of our application, we can separate the response into individual claims and independently search for evidence that supports each within the retrieved context.
LLM query for Groundedness Relevance
system_prompt:
“””You are a INFORMATION OVERLAP classifier; providing the overlap of information between the source and statement.
Respond only as a number from 0 to 10 where 0 is no information overlap and 10 is all information is overlapping.
Never elaborate.“””
user_prompt:
“””
SOURCE: {premise}
Hypothesis: {hypothesis}
Please answer with the template below for all statement sentences:
Statement Sentence: <Sentence>,
Supporting Evidence: <Identify and describe the location in the source where the information matches the statement. Provide a detailed, human-readable summary indicating the path or key details. if nothing matches, say NOTHING FOUND>
Score: <Output a number between 0–10 where 0 is no information overlap and 10 is all information is overlapping>“””
Answer Relevance
Last, our response still needs to helpfully answer the original question. We can verify this by evaluating the relevance of the final response to the user input.
LLM query for Answer Relevance
system_prompt:
“””You are a RELEVANCE grader; providing the relevance of the given RESPONSE to the given PROMPT.
Respond only as a number from 0 to 10 where 0 is the least relevant and 10 is the most relevant.
A few additional scoring guidelines:
- Long RESPONSES should score equally well as short RESPONSES.
- Answers that intentionally do not answer the question, such as ‘I don’t know’ and model refusals, should also be counted as the most RELEVANT.
- RESPONSE must be relevant to the entire PROMPT to get a score of 10.
- RELEVANCE score should increase as the RESPONSE provides RELEVANT context to more parts of the PROMPT.
- RESPONSE that is RELEVANT to none of the PROMPT should get a score of 0.
- RESPONSE that is RELEVANT to some of the PROMPT should get as score of 2, 3, or 4. Higher score indicates more RELEVANCE.
- RESPONSE that is RELEVANT to most of the PROMPT should get a score between a 5, 6, 7 or 8. Higher score indicates more RELEVANCE.
- RESPONSE that is RELEVANT to the entire PROMPT should get a score of 9 or 10.
- RESPONSE that is RELEVANT and answers the entire PROMPT completely should get a score 10.
- RESPONSE that confidently FALSE should get a score of 0.
- RESPONSE that is only seemingly RELEVANT should get a score of 0.
- Never elaborate.“””
user_prompt:
“””PROMPT: {prompt}
RESPONSE: {response}
RELEVANCE: “””
Trulens Evaluation for RAGs
The ‘trulens_eval’ library includes different modules such as Select, TruVirtual, VirtualApp, VirtualRecord, Feedback, LiteLLM, TruLlama, Groundedness, Tru which are used for evaluating, interpreting and understanding the behaviour of deep learning models. These modules help in dissecting the model’s decisions, providing model-agnostic interpretations and feedback, and understanding the model’s groundedness (how well the model’s outputs are grounded in its inputs).
import os
from trulens_eval import Select
from trulens_eval.tru_virtual import VirtualApp
from trulens_eval import Select
from trulens_eval.tru_virtual import VirtualRecord
from trulens_eval import Feedback, LiteLLM, TruLlama
from trulens_eval.feedback import Groundedness
import numpy as np
from trulens_eval.tru_virtual import TruVirtual
from trulens_eval import Tru
import litellm
os.environ[“VERTEX_PROJECT”] = “hardy-device-386718”
os.environ[“VERTEX_LOCATION”] = “us-central1”
Creating Trulens Virtual App
The virtual application is designed for the purpose of incorporating records and assessing them utilizing the feedback function. The results of these evaluations will then be displayed on a Streamlit Dashboard.
We configure the application with specific attributes such as the model name, template, and debug level. It then further customizes the application with various components, like the number of tokens and retriever component.
Next, we define feedback functions for groundedness, answer relevance, and context relevance.
An application instance is then created with the defined application and feedback functions. This instance is ready to serve its purpose in model evaluation.
Test cases are then added to the virtual app for evaluation. The user query is utilized to generate LLM Final Output and Retrieved Comments/Documents.
Finally, we launch the Trulens Dashboard. This is an excellent tool for visualizing model performance and understanding how well the model is doing.
virtual_app = dict(
llm=dict(
modelname=”Gemini-pro”
),
template=”information about the template I used in my app”,
debug=”all of these fields are completely optional”
)
virtual_app = VirtualApp(virtual_app) # can start with the prior dictionary
virtual_app[Select.RecordCalls.llm.maxtokens] = 1024
retriever_component = Select.RecordCalls.retriever
virtual_app[retriever_component] = “this is the retriever component”
# Defining the Feedback Functions
GEMINI_PROVIDER = LiteLLM(model_engine=”gemini-pro”)
# Define a groundedness feedback function
GROUNDED = Groundedness(groundedness_provider=GEMINI_PROVIDER)
f_groundedness = (
Feedback(GROUNDED.groundedness_measure_with_cot_reasons)
.on(context)
.on_output()
.aggregate(GROUNDED.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_answer_relevance = (
Feedback(GEMINI_PROVIDER.relevance_with_cot_reasons, name = “Answer Relevance”)
.on_input().on_output())
# Question/statement relevance between question and each context chunk.
f_context_relevance = (
Feedback(GEMINI_PROVIDER.context_relevance_with_cot_reasons, name = “Context Relevance”)
.on_input()
.on(context)
.aggregate(np.mean))
# Creating the App
from trulens_eval.tru_virtual import TruVirtual
virtual_recorder = TruVirtual(
app_id=”App_1",
app=virtual_app,
feedbacks=[f_groundedness,f_answer_relevance,f_context_relevance]
# Creating and adding the test cases to the virtual App for evaluation
context_call = retriever_component.get_context
rec1 = VirtualRecord(
main_input=”User Query”,
main_output=”””LLM Final Output “””,
calls=
{
context_call: dict(
args=[“User Query” ],
rets=[“””Retrieved Comments/Documents”””])})
data = [rec1]
for record in data:
virtual_recorder.add_record(record)
# Lauching the Trulens Dashboard
tru = Tru()
tru.run_dashboard()
Conclusion
Congratulations on reaching this milestone! You’re now equipped to deploy a RAG framework in a production environment. Our journey began by comprehending the integral role of Vector Databases, with a specific focus on the Milvus vector database.
We then delved into the practical usage of Gecko embeddings, a tool that helped us create vector embeddings for our data. Following this, we utilized the capabilities of the recent GPT-4 model to prompt and effectively process user queries. Lastly, we familiarized ourselves with the RAG triad of metrics, and leveraged the TruLens framework to evaluate our RAGs. This comprehensive understanding positions you well in the realm of Natural Language Processing.
RAGs can be used in information retrieval systems, machine translation, and content recommendation systems, where it aids in providing more contextually relevant content. Lastly, it’s also used in developing advanced Question-Answering (QA) systems.
Deploying RAGs in production — Part 2 was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: https://medium.com/walmartglobaltech/deploying-rags-in-production-part-2-ae36f723c0c7?source=rss----905ea2b3d4d1---4