Deploying RAGs in production — Part 1
Authors: Chinmay Jain, Osheen Nayak
Large Language Models (LLMs) are a significant advancement in the field of Artificial Intelligence. Their ability to understand and generate human-like text has opened a plethora of opportunities for innovation. They are robust in their abilities and showcase immense potential in various applications.
However, everything comes with its own set of challenges. LLMs at times struggle with precision and providing contextually relevant responses. Effectively handling unseen data and the need for extensive resources for training are among the few challenges they face. Furthermore, they are highly dependent on the input prompt for generating responses, and there can be a lack of transparency in their decision-making process.
Retrieval-Augmented Generation (RAG) framework is a step forward in overcoming many of these challenges effectively. They uplift the precision by retrieving relevant documents for response[ON1] generation. Additionally, they offer more contextually relevant responses and manage unseen data more effectively. The RAG models demand fewer training resources, produce improved responses regardless of the quality of the input prompt, and enhance transparency by making the source of their responses traceable.
In this article, we’ll explore deploying RAG in a production environment. We’ll sidestep an in-depth exploration of the internal workings of RAG models, instead, we’ll concentrate on their practical application and performance evaluation. We will be using Trulens, a tool for model understanding and validation, to assess the effectiveness of our deployed models. This comprehensive guide is designed to offer valuable insights for both AI experts and novices, focusing on the real-world applications of these advanced AI models.
What are RAGs
Imagine a search engine that not only finds information but also understands and uses it to generate responses. That’s essentially what RAGs does. It scours through a database to find relevant information and then uses this information to enhance the responses given by the AI model.
Retrieval Augmented Generation (RAG) is an innovative approach that enhances AI models in natural language processing. It combines the strengths of Language Models and search engine information retrieval methods. RAG enables AI models to retrieve relevant information from databases and use it to generate more accurate and informative responses, even with data not included in their original training. This makes AI systems more flexible, adaptable, and powerful by making them more contextually aware
How the RAG Architecture Works
 The above schematic illustrates a workflow specifically tailored for custom datasets. Each step in the RAG architecture is meticulously described below, explaining how it operates on custom data.
The above schematic illustrates a workflow specifically tailored for custom datasets. Each step in the RAG architecture is meticulously described below, explaining how it operates on custom data.Documents (Custom Data)
Document refers to your custom dataset, a collection of external knowledge sources the model can use external knowledge sources the model can use. These documents can comprise texts, articles, databases, or any other forms of data. The RAG model uses these documents to retrieve the necessary information to generate responses or complete tasks. These documents serve as a basis for the model to pull relevant information, aiding in its ability to provide more accurate and contextually appropriate outputs.
Embeddings Model
Once the necessary documents are gathered, they are processed through an embeddings model, which mathematically represents data. In the case of the RAG (Retrieval-Augmented Generation) system, the embeddings depict both queries and documents to facilitate efficient document retrieval.
An encoder, often a transformer-based model, generates these embeddings. The embeddings capture the semantic value of the queries and documents and enable the model to fetch relevant information even without an exact wording match.
They are fundamental to the RAG architecture’s operation, merging the advantages of retriever and generator models for advanced question answering and language comprehension tasks.
Vector Store/Database
The generated vectors are then stored in a vector database, a storage system designed to efficiently store and retrieve high-dimensional vectors. This helps in finding the most similar document embeddings to the query embedding.
This efficient retrieval process is vital in the RAG architecture, as it links the retriever and generator models. It allows the model to extract relevant information from a large dataset, aiding in advanced question answering and language understanding tasks.
User Query
When you input a search query into the system, it converts your query into a more advanced, vectorized version using the same embeddings model that processes documents. This conversion encapsulates the core of your inquiry, considering the nuanced implications of your request.
Retrieval
Following this, our vector store springs into action. It’s like a librarian that knows exactly where every document is located. The vector store matches the transformed query against all the embedded documents
It uses a similarity metrics to find and retrieve the documents that are most similar to our query. These are the documents most likely to have the information you need.
Context Query Prompt
The system blends the discovered documents with your initial request, forming a query prompt that’s densely layered with context. This practice enriches your original query with precise information drawn from the unearthed documents. Consequently, this infuses the system with a more comprehensive comprehension of your search requirements.
Large Language Models (LLMs)
At this point, the system hands over the query prompt to a Large Language Model, or LLM. LLMs, like the ones in the GPT family, are trained on a massive amount of text. This allows them to understand and generate responses that are relevant and make sense in the current context. The model uses the information from the query prompt to create a well-informed and relevant response.
Delivering the Output
In the concluding phase, the response is generated and delivered to you by the system. This response is a blend of the Large Language Model’s overall comprehension and the specific insights gained from pertinent documents. The outcome is a response that not only exhibits accuracy and context appropriateness but also possesses the eloquence and smoothness akin to that of a response penned by a human expert.
RAG based QnA bot
Now that we understand the structure and components of a RAG framework, let’s design our first application, a simple QnA bot[AA1] . This bot should be able to answer all queries in relation to the given documents.
We will build this application using Llama Index, a data framework that helps create LLM based applications with seamless data connection and indexing capabilities.
The llama_index modules and their functionalities are mentioned below
- ‘ServiceContext’ manages shared resources.
- ‘LLMPredictor’ and ‘OpenAIEmbedding’ handle language model predictions.
- ‘PromptHelper’ assists in creating suitable model prompts.
- Interaction with the OpenAI language model is done through ‘OpenAI’ from ‘llama_index.llms’
- TokenTextSplitter’ and ‘SimpleNodeParser’ are used for text processing.
- ‘Vector storeIndex’ and ‘SimpleDirectoryReader’ manage data.
- ‘set_global_service_context’ sets a global service context to ensure unified operation of all services.
import os
from llama_index import ServiceContext, LLMPredictor, OpenAIEmbedding, PromptHelper
from llama_index.llms import OpenAI
from llama_index.text_splitter import TokenTextSplitter
from llama_index.node_parser import SimpleNodeParser
from llama_index import Vector storeIndex, SimpleDirectoryReader
from llama_index import set_global_service_context
import tiktoken
os.environ[‘OPENAI_API_KEY’] = “YOUR API KEY”
Load Documents
Llama Index includes a class SimpleDirectoryReader, which can read saved documents from a specified directory. It automatically selects a parser based on file extension.You can also have your custom implementation of a PDF reader using packages like PyMuPDF or PyPDF2.
documents = SimpleDirectoryReader(input_dir=’data’).load_data()
Creating Text Chunks
Data from various sources often exceeds the capacity of Language Learning Models (LLMs), causing potential omission of key details when processed by the ChatGPT API. Text chunking, which breaks down longer texts into manageable segments, is a solution to this, improving the accuracy of embedding and data retrieval, and promoting precision in context. The Llama index provides built-in tools for text chunking.
text_splitter = TokenTextSplitter(
separator=” “,
chunk_size=1024,
chunk_overlap=20,
backup_separators=[“\n”],
tokenizer=tiktoken.encoding_for_model(“gpt-3.5-turbo”).encode
)
node_parser = SimpleNodeParser.from_defaults(
text_splitter = TokenTextSplitter )
)
SimpleNodeParser creates nodes out of text chunks, and the text chunks are created using Llama Index’s TokenTextSplitter. We can use a SentenceSplitter as well.
text_splitter = SentenceSplitter(
separator=” “,
chunk_size=1024,
chunk_overlap=20,
paragraph_separator=”\n\n\n”,
secondary_chunking_regex=”[^,.;。]+[,.;。]?”,
tokenizer=tiktoken.encoding_for_model(“gpt-3.5-turbo”).encode )
Creating Embeddings
There is no need for any specific alterations when it comes to embedding models. The Llama Index comes with a custom implementation of multiple popular embedding models, including OpenAI’s Ada, Cohere, Sentence transformers, and others. If one wishes to customize the embedding model, they can do so using ServiceContext and PromptHelper.
llm = OpenAI(model=’gpt-3.5-turbo’, temperature=0, max_tokens=256)
embed_model = OpenAIEmbedding()
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None)
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
prompt_helper=prompt_helper)
)
Vector Store
We will use the Llama Index’s default vector store. It is an in-memory vector database. You may go with other vector stores such as Chroma, Weaviate, Qdrant, Milvus etc.
index = Vector storeIndex.from_documents(
documents,
service_context = service_context
)
An index is created using the documents from our directory and the defaults from the service context we defined earlier.
Query Index
The final step is to query from the index and get a response from the LLM. Llama Index provides a query engine for querying and a chat engine for a chat-like conversation. The difference between the two is the chat engine preserves the history of the conversation, and the query engine does not.
query_engine = index.as_query_engine(service_context=service_context)
response = query_engine.query(“What is HNSW?”)
print(response)
Congratulations!! You have successfully implemented a Basic RAG using Llama Index.
Advanced RAGs
Naive RAGs are limited by their understanding of context and struggle with long texts due to a fixed-length context vector. They lack an iterative refinement process, limiting the precision of their responses. They are not highly adaptable, have high computational costs, and might not generalize well to out-of-sample data. Additionally, they may struggle to generate detailed answers to complex questions.
1. Sentence Window Retrieval
Sentence window retrieval is a method that retrieves specific sentences, rather than entire documents, from a large volume of data based on the context of the question. This process involves dividing documents into smaller chunks or “windows” of sentences, which are then indexed and used as the retrieval corpus. The model uses a dense vector to find sentence windows that closely match the question semantically. Surrounding content is also included to add context to the retrieved information.
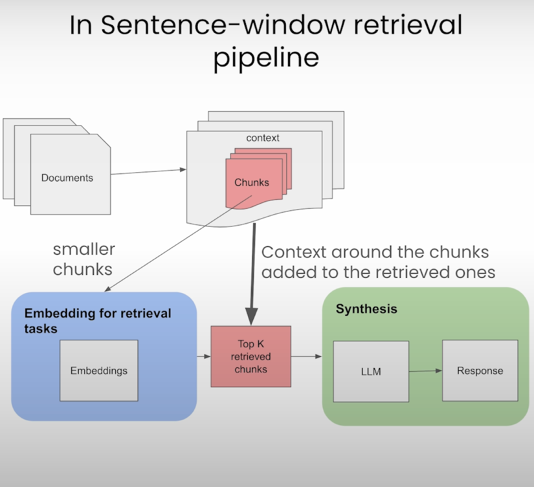
Algorithm:
1. Each document is divided into smaller chunks or “windows” of sentences.
2. These windows are indexed and used as the retrieval corpus.
3. When a question is posed, the model uses a dense vector to find the sentence windows that are semantically similar to the question.
4. The content around the chunks is also added to the retrieved ones to provide a better understanding of the topic.
Advantages:
1. Fine-Grained Retrieval: Sentence window retrieval provides more targeted and precise answers as it focuses on specific sentences rather than entire documents, reducing the chance of irrelevant information being included.
2. Improved Efficiency: This method improves efficiency as it reduces the amount of data that needs to be processed by the LLM model, as only the most relevant sentence windows are used.
3. Contextual Understanding: Including a window of sentences around the chunk allows the model to generate a more accurate and contextually appropriate response, particularly when the chunks of information are part of a larger narrative, or their meaning changes based on the surrounding content.
2. Auto Merging Retrieval
The Auto Merging retrieval in RAG operates in a hierarchical tree structure. The process begins with an initial query which is passed to the retrieval model. The model then searches the database for relevant documents and assigns each a relevance score. The auto-merging process integrates these documents into a single, information-rich document based on their relevance scores. This merged document is then fed to the LLM model to generate the final response.
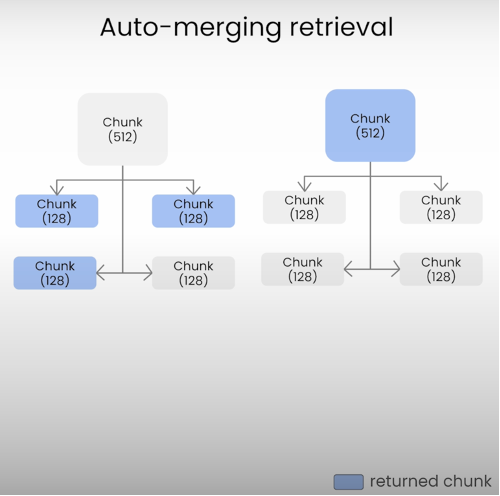
Algorithm:
1. The process starts with an initial query or input that needs a response.
2. The query is passed to the retrieval model, which searches the database for relevant documents.
3. Each retrieved document is analyzed and given a relevance score.
4. The auto-merging process integrates the retrieved documents into a single coherent document based on their relevance scores.
5. The merged document is then fed to the LLM model to generate the final response.
Advantages:
1. Enhanced Response Quality: The auto-merging retrieval process enhances the quality of the generated responses by minimizing the inclusion of irrelevant information.
2. Computational Efficiency: This process reduces computational limitations by decreasing the number of documents that need to be processed by the LLM model.
3. Optimized Performance: Auto-merging retrieval in RAG optimizes the model’s performance by streamlining the document retrieval and response generation procedures.
4. Increased Effectiveness: The process improves the overall effectiveness of the document retrieval and response generation.
Conclusion
Our journey commenced by grasping the complexities and challenges encountered by Large Language Models (LLMs), and how the introduction of Retrieval-Augmented Generation (RAG) models can address these issues through improved context retrieval. We gained an understanding of the fundamental architecture and algorithm of a typical RAG framework, which we successfully implemented using the Llama Index. Moving forward, we delved into some advanced RAG algorithms, appreciating the edges they offer over their naïve counterparts.
In the next part, we will explore the production aspects of each RAG component, accompanied by a deep dive into the diverse tools and libraries at our disposal. This will equip us with the necessary skills to deploy these RAGs within a real-world production application.
Deploying RAGs in production — Part 1 was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Deploying RAGs in production — Part 1 | by osheen nayak | Walmart Global Tech Blog | Jul, 2024 | Medium