 Source : Google images
Source : Google images
Overview
Hello all! Elasticsearch is indeed a powerful and popular open-source search and analytics engine that has gained significant popularity in recent years. It is widely used for various use cases, including full-text search, log and event data analysis, monitoring, and more, thanks to its impressive capabilities and efficiency.
Elasticsearch has proven to be an invaluable tool, primarily due to its exceptional response times when handling full-text searches. While the concept of “Inverted Indexes” underlies this efficiency, it can be a complex idea to grasp. Therefore, I have tried to provide a clear and accessible explanation in this article, accompanied by a real-life use case.
This article is a part of an elastic search capabilities series and will cover the concepts of Inverted indexes along with synonyms handling using pre-processor pipeline.
How does the search happen internally?
Before we jump into the explanation for inverted indexes and synonyms handling let us first understand what a Forward Index is.
A Forward Index is primarily used to map documents to the terms or words they contain. It focuses on storing the content of documents along with the terms within them. For instance: A website wants to ensure each page can be easily searched via keywords located on every page. Following are the steps of forward indexing:
- Collect all the keywords by going to the first page.
- Add the keywords in the index entry for that respective web page.
- Repeat step 1 until all pages are indexed by going to the next page.
After all the pages are indexed, a list of all pages will be there, having their associated keywords attached to it as displayed below.

Indexing is fast in this case since adding texts/words can be appended only. But querying for the keyword is slower because each document is mapped to multiple keywords and the search engine needs to iterate over multiple documents here.
Now let us talk about the Inverted Indexes, imagine you have an e-commerce website with a wide range of products, and customers want to search for products based on various attributes:
- Brand: Customers may want to find products from a specific brand, like “ABC” or “XYZ.”
- Category: They might be interested in products in a particular category, such as “Electronics” or “Shoes.”
- Price: Some customers may want to filter products by price range, like products under $200.
- Rating: Customers might want to see products with a certain rating, like products with a rating of 4 stars or higher.
When products are added to the e-commerce platform, Elasticsearch indexes specific attributes such as brand, category, price, and rating for each product (Assuming these attributes are indexed attributes). Each attribute is treated as a field, and an inverted index is created for each of these fields.
For example, for the “brand” field, Elasticsearch maintains an inverted index that maps brands to the products that belong to those brands. Similarly, it creates inverted indexes for all the other indexed fields.Let us focus on the “brand” field as an example. The inverted index for “brand” looks something like this:
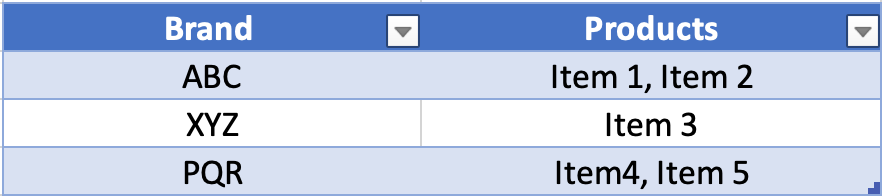 Brand inverted index stored in elastic search
Brand inverted index stored in elastic search Category inverted index stored in elastic search
Category inverted index stored in elastic searchEach brand in the inverted index points to the products associated with that brand.
Elastic search does not need to examine every product in the collection, it looks at the inverted indexes to find the relevant products. For the query mentioned above, Elasticsearch efficiently looks up the “ABC” entry in the “brand” inverted index, filters products in the “Shoes” category, narrows down products based on the price range, and finally considers only those with a rating of 4 stars or higher, hence improving the response time.
The icing on the cake? It also avoids storing replicated keywords as it records some information by checking first if the keyword is already present. Each keyword must process the previous indexes, making the indexing a bit slower. But on the other hand, this makes querying VERY fast. Since the search engine only needs to look up a single record.
Handling Synonyms in Elastic Search
Now that we are aware of how the inverted indexing works, let us explore one use-case where we will be indexing for the synonyms. Managing synonyms for product search can be challenging. Elasticsearch allows you to define synonym dictionaries, making it easier to account for variations in user queries. Here is how we can leverage elastic search to manage synonyms:
- Create a Synonym Token File: Start by creating a synonym token file that contains the synonym pairs. Each line of the file should contain a list of synonyms separated by commas. For example, a file called “synonyms.txt” with content like this:
smartphone, mobile, cell phone, cellular
tv, television
apparel, tshirt, trousers
- Upload the Token File to Elasticsearch: _ingest API can be used to upload the synonym token file to Elasticsearch and create a pipeline that includes a synonym processor. In Elasticsearch, a Pipeline is a sequence of configurable tasks applied to documents during indexing called processor. A pre-processor is a specific processor responsible for tasks like text analysis, synonym handling, or data normalization, enhancing document quality before it’s stored in the index. In this case, the processor can read the synonyms from the file and apply them during the indexing process. Here’s an example:
PUT /_ingest/pipeline/synonym-pipeline
{
“description” : “Add synonym token filter”,
“processors” : [
{
“attachment” : {
“field” : “productDescription”,
“target_field” : “productDescription”,
“indexed_chars” : -1
}
},
{
“synonym” : {
“field” : “productDescription”,
“synonyms_path” : “synonyms.txt”
}
}
]
}
This pipeline will apply synonyms from “synonyms.txt” to the “productDescription” field.
- Apply the Pipeline to Your Mapping: Specify the pipeline created above for text fields in the mapping. This way, the synonym processing will be automatically applied when indexing data. Here is an example:
PUT /my_index
{
“settings”: {
“analysis”: {
“filter”: {
“synonym_filter”: {
“type”: “synonym”,
“synonyms_path”: “synonyms.txt”
}
},
“analyzer”: {
“synonym_analyzer”: {
“tokenizer”: “standard”,
“filter”: [“lowercase”, “synonym_filter”]
}
}
}
},
“mappings”: {
“properties”: {
“productDescription”: {
“type”: “text”,
“analyzer”: “synonym_analyzer”
}
}
}
}
Elastic search expands the terms both during indexing and querying using the synonyms stored for a particular word, thereby showing results for all the related words.
Elasticsearch also allows expanding queries with synonyms using a special query type called multi_match and its “type”: “cross_fields” option. This can be useful for handling synonyms at the query level:
{
“query”: {
“multi_match”: {
“query”: “mobile phone”,
“fields”: [“product_name”],
“type”: “cross_fields”
}
}
}Internally, Elasticsearch applies the synonym filter to the query terms and then searches for the expanded terms in the inverted index. It essentially creates a Boolean OR query to include all synonyms in the search results. For instance, when searching for “mobile phone,” it searches for documents containing “mobile” or “phone” or their synonyms.
This combination of token filters and query expansion ensures that Elasticsearch can effectively handle synonyms and return relevant results, all while leveraging its inverted index structure for efficiency.
Conclusion
Now that we have delved into the inner workings of Elasticsearch indexes and pipelines, searching for products on an e-commerce site, sifting through articles on a news portal, or exploring data in a business application, we know elastic-search’s inverted indexes are there, diligently working their magic.
I am exhilarated to extend this discussion into a series of articles with our next topic focusing on geospatial analysis.
Tags: #elasticsearch #invertedindexes #synonymsearching #pre-processors
Demystifying the Elastic search indexing and synonym search was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Demystifying the Elastic search indexing and synonym search | by divya sharma | Walmart Global Tech Blog | Nov, 2023 | Medium