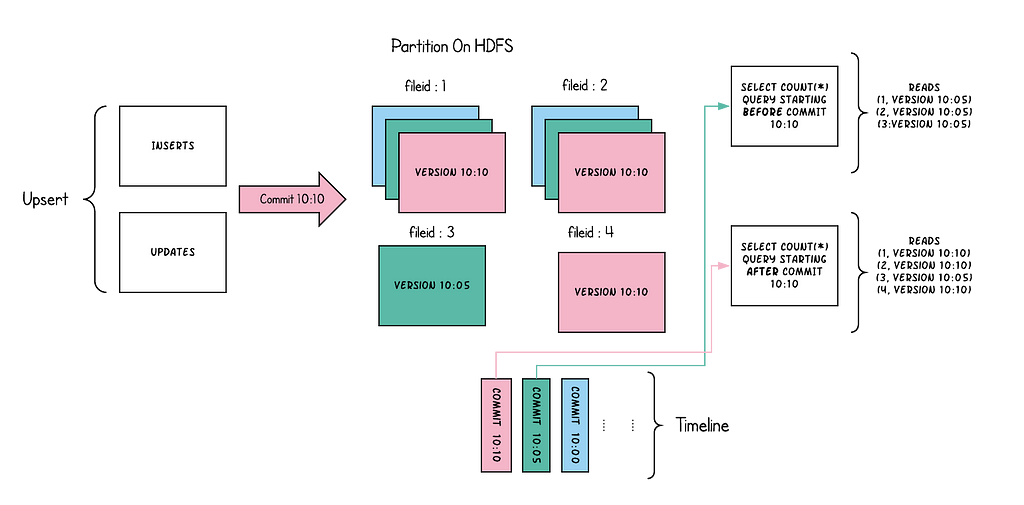
 Image Source: https://hudi.apache.org/docs/concepts/
Image Source: https://hudi.apache.org/docs/concepts/
Apache Hudi is an open-source data management framework that is designed to simplify incremental data processing and data pipeline management.
Hudi provides features for data quality management, data lineage tracking, and data versioning, which makes it easier to manage and track changes to data over time.
This Blog Post offers readers a comprehensive and insightful understanding of the Copy-on-Write approach in Apache Hudi, with a specific focus on both read and write operations. This blog post is designed to cater to readers who are interested in data management, optimization using Apache Hudi’s techniques.
Need for Apache Hudi
 Use cases of Hudi
Use cases of HudiIndustry Trends:
Apache Hudi is a rapidly growing open source project that is gaining adoption in a variety of industries. Some of the current industry trends of Apache Hudi include:
- Increased adoption for streaming analytics: Apache Hudi’s ability to handle both batch and real-time data processing makes it an ideal choice for streaming analytics applications.
- Growing use cases in IoT: Apache Hudi’s support for incremental updates and deletes makes it a good fit for IoT use cases where data is constantly being generated and updated.
- Demand for ACID compliance: As businesses increasingly adopt cloud-based data lakes, there is a growing demand for ACID-compliant storage solutions. Apache Hudi is one of the few data lake solutions that offers ACID compliance, making it a good choice for businesses that need to ensure the integrity of their data.
Overall, Apache Hudi is a promising open source project that is well-positioned to meet the needs of the modern data lake. The project is gaining traction in a variety of industries.
Storage Models:
- Copy on Write (COW) — Data is stored in a columnar format (Parquet), and each update creates a new version of files during a write. COW is the default storage type.
- Merge on Read (MOR) — Data is stored using a combination of columnar (Parquet) and row-based (Avro) formats. Updates are logged to row-based delta files and are compacted as needed to create new versions of the columnar files.
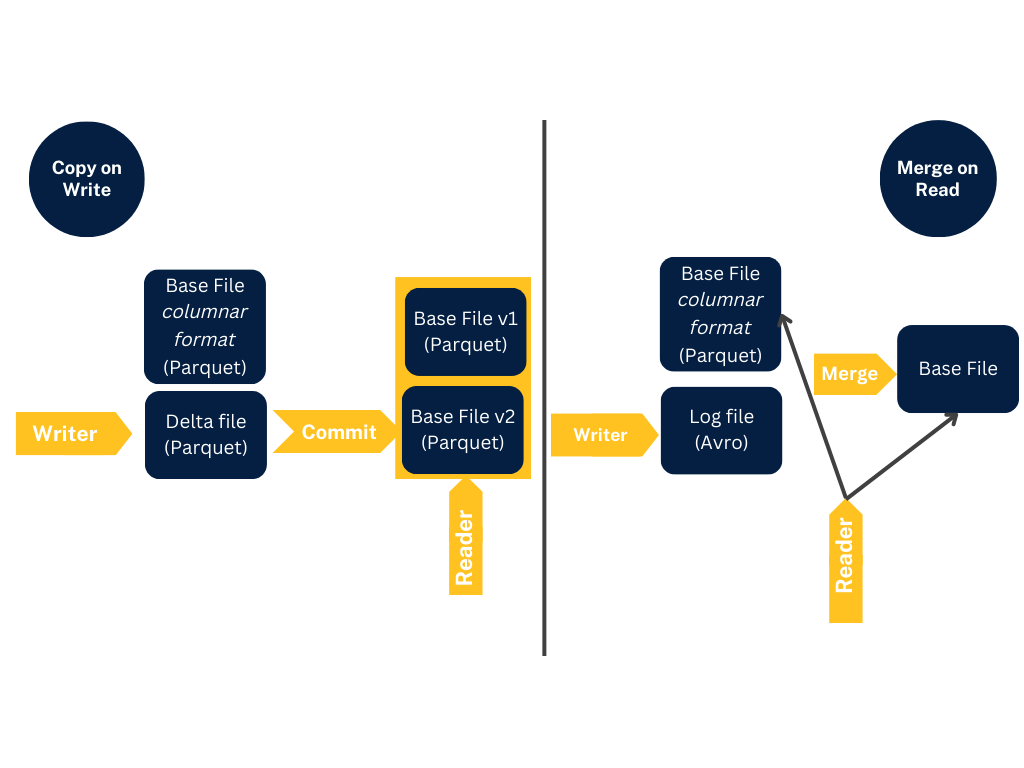 COW and MOR
COW and MOROverall, the choice of storage mode depends on the specific use case and requirements of the data application.
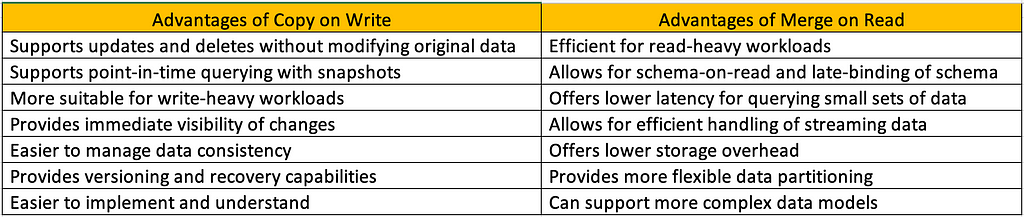 Advantages of Copy on Write and Merge on Read
Advantages of Copy on Write and Merge on ReadUsage of Copy on Write:
In the COW model, when a record is updated, instead of overwriting the existing record, a new version of the record is created, and the old version is marked as obsolete. The new version is written to a new file, and the old version remains unchanged in the original file. This approach ensures that the original data is preserved, and new data is added without affecting the old data.
Hudi’s COW model also provides support for efficient query processing, as it enables data compaction and incremental processing. The obsolete records are periodically cleaned up through a compaction process, which merges the latest versions of the data and removes the obsolete versions. This reduces the storage footprint and speeds up query processing.
COW Hudi Directory Structure:
The Hudi directory structure is an important aspect of the Hudi file layout. It is used to organize the data files stored in Hudi tables.
The data files are organized into partitions based on the partition key. Each partition contains one or more Parquet files containing the data records. The directory structure a table is as follows:
table_name/
└── .hoodie/
└── partition_key=<partition_value>/
└── <file_id>.parquet
The .hoodie/ directory in a table contains metadata files used by Hudi to manage the table. Overall, the directory structure of a Hudi table provides a way to organize the data files and track changes made to the data over time.
 Directory Structure of Hudi Table
Directory Structure of Hudi Table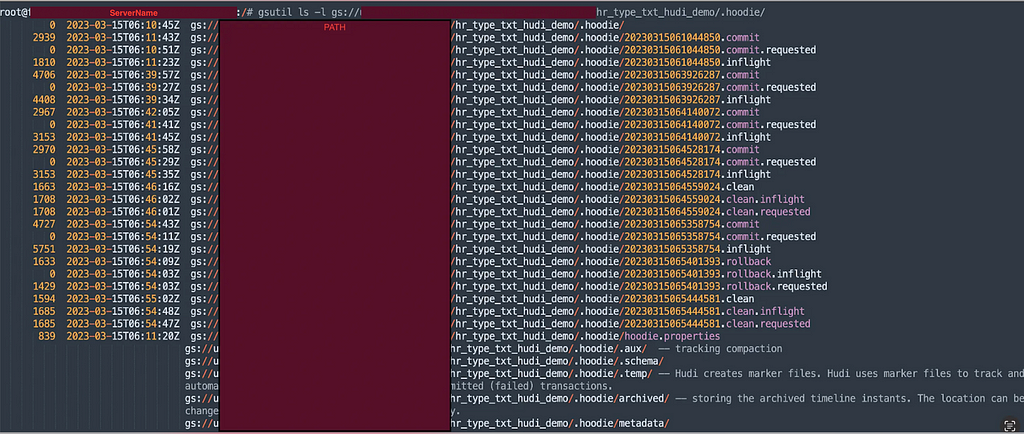 Directory structure of .hoodie
Directory structure of .hoodieLet us consider a table with transaction details for this illustration.
Connect to Spark Shell:
spark-shell <br /> - packages org.apache.hudi:hudi-spark2.4-bundle_2.12:0.12.0,xerces:xercesImpl:2.8.0 <br /> - conf “spark.serializer=org.apache.spark.serializer.KryoSerializer” <br /> - conf ‘spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension’
COW Hudi Table Creation using Spark:
scala> val targetPath = “gs://<Bucket_Path>/<db_name>.db/trans_fdl_kt”
scala> spark.sql(s"““CREATE TABLE if not exists <schema_name>.trans_fdl_blog(
| trans_nbr varchar(50),
| id int,
| seq_nbr smallint,
| item_nbr int,
| item_type tinyint,
| src_rcv_ts timestamp,
| load_ts timestamp,
| trans_dt date)
| USING hudi
| PARTITIONED BY (trans_dt)
| location “$targetPath”
| options(type = ‘cow’,
| primaryKey=‘id,trans_nbr,seq_nbr’,
| preCombineField = ‘src_rcv_ts’)””“)
Write to Hudi Table:
#view source records
spark.sql(“select trans_nbr,id,seq_nbr,item_nbr,item_type,src_rcv_ts,load_ts,
trans_dt from <Schema_name>.trans_hudi_cow_blog
where trans_dt=‘2023-05-16’”).show(20,false)
±--------±–±------±-------±--------±------------------±----------------------±---------+
|trans_nbr|id |seq_nbr|item_nbr|item_type|src_rcv_ts |load_ts |trans_dt |
±--------±–±------±-------±--------±------------------±----------------------±---------+
|ABC1234 |23 |1 |434545 |0 |2023-05-16 08:00:59|2023-05-16 14:59:52.607|2023-05-16|
|ABC1234 |23 |1 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:00:16.438|2023-05-16|
|ABC1234 |23 |1 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:00:38.64 |2023-05-16|
|ABC1234 |23 |2 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:00:54.102|2023-05-16|
|ABC1234 |23 |2 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:13.485|2023-05-16|
|ABC1234 |23 |3 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:35.462|2023-05-16|
|ABC1234 |23 |4 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:02:57.529|2023-05-16|
|ABC2567 |23 |1 |434545 |0 |2023-05-16 11:00:00|2023-05-16 15:03:24.612|2023-05-16|
±--------±–±------±-------±--------±------------------±----------------------±---------+
We have primary key combination of columns “trans_nbr,id,seq_nbr” in Target and source has duplicates on below records.
#view Duplicate records
spark.sql(“select trans_nbr,id,seq_nbr,count(1) from <schema_name>.trans_hudi_cow_blog
where trans_dt=‘2023-05-16’ group by trans_nbr,id,seq_nbr
having count(1)>1”).show(20,false)
±--------±–±------±-------+
|trans_nbr|id |seq_nbr|count(1)|
±--------±–±------±-------+
|ABC1234 |23 |2 |2 |
|ABC1234 |23 |1 |3 |
±--------±–±------±-------+
Upsert Operation:
We will do Copy on Write to Target table using UPSERT Opertion and see how the duplicates are being avoided based on Timestamp column “src_rcv_ts” and partition column “trans_dt”
Record key: The record key is a unique identifier for each record within a partition. It is used to ensure that records are not duplicated and to support efficient queries and updates. The record key can be a single column or a combination of columns.
Partition path: The partition path is a string that identifies the partition where a record belongs. It is typically made up of one or more columns that are used to group similar data together. The partition path can be used to optimize queries by limiting the data that needs to be scanned.
Precombine field: The precombine field is used to group records together before they are written to Hudi. This can improve performance by reducing the amount of data that needs to be processed. The precombine field can be any column, but it is typically a timestamp column.
#Create source DF
val src_df = spark.sql(“select trans_nbr,id,seq_nbr,item_nbr,item_type,
src_rcv_ts,load_ts , trans_dt from <schema_name>.trans_hudi_cow_blog
where trans_dt=‘2023-05-16’”)
#Write to Hudi Table
src_df.write.format(“org.apache.hudi”).
option(“hoodie.datasource.write.recordkey.field”, “id,trans_nbr,seq_nbr”).
option(“hoodie.datasource.write.partitionpath.field”, “trans_dt”).
option(“hoodie.datasource.write.precombine.field”, “src_rcv_ts”).
option(“hoodie.datasource.write.operation”, “upsert”).
option(“hoodie.datasource.write.table.type”, “COPY_ON_WRITE”).
option(“hoodie.table.name”, “trans_fdl_blog”).
option(“hoodie.datasource.write.keygenerator.class”, “org.apache.hudi.keygen.ComplexKeyGenerator”).
option(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”).
option(“hoodie.datasource.write.hive_style_partitioning”, “true”).
option(“hoodie.datasource.write.reconcile.schema”, “true”).
mode(“Append”).
save(targetPath)
Lets view the Hudi Target Table.
#View Hudi records
spark.sql(“select * from <schema_name>.trans_fdl_blog”).show(20,false)
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path|_hoodie_file_name |trans_nbr|id |seq_nbr|item_nbr|item_type|src_rcv_ts |load_ts |trans_dt |
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|20230516153138932 |20230516153138932_0_0|id:23,trans_nbr:ABC1234,seq_nbr:4|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |4 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:02:57.529|2023-05-16|
|20230516153138932 |20230516153138932_0_1|id:23,trans_nbr:ABC1234,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |1 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:00:38.64 |2023-05-16|
|20230516153138932 |20230516153138932_0_2|id:23,trans_nbr:ABC1234,seq_nbr:2|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |2 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:13.485|2023-05-16|
|20230516153138932 |20230516153138932_0_3|id:23,trans_nbr:ABC1234,seq_nbr:3|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |3 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:35.462|2023-05-16|
|20230516153138932 |20230516153138932_0_4|id:23,trans_nbr:ABC2567,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC2567 |23 |1 |434545 |0 |2023-05-16 11:00:00|2023-05-16 15:03:24.612|2023-05-16|
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
#Upserted records
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path|_hoodie_file_name |trans_nbr|id |seq_nbr|item_nbr|item_type|src_rcv_ts |load_ts |trans_dt |
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|20230516153138932 |20230516153138932_0_1|id:23,trans_nbr:ABC1234,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |1 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:00:38.64 |2023-05-16|
|20230516153138932 |20230516153138932_0_2|id:23,trans_nbr:ABC1234,seq_nbr:2|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |2 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:13.485|2023-05-16|
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
#Inserted records
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path|_hoodie_file_name |trans_nbr|id |seq_nbr|item_nbr|item_type|src_rcv_ts |load_ts |trans_dt |
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|20230516153138932 |20230516153138932_0_0|id:23,trans_nbr:ABC1234,seq_nbr:4|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |4 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:02:57.529|2023-05-16|
|20230516153138932 |20230516153138932_0_3|id:23,trans_nbr:ABC1234,seq_nbr:3|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |3 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:35.462|2023-05-16|
|20230516153138932 |20230516153138932_0_4|id:23,trans_nbr:ABC2567,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC2567 |23 |1 |434545 |0 |2023-05-16 11:00:00|2023-05-16 15:03:24.612|2023-05-16|
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
We could see latest “src_rcv_ts” timestamp records are considered in case of Duplicates. Even if there is any duplicates with same “src_rcv_ts” timestamp, still one of the record will be available out of Hudi Table.
Hoodie.Properties
hoodie.properties is a configuration file used by Apache Hudi to specify various runtime properties for Hudi jobs. It contains key-value pairs that define properties such as the Hudi dataset path, data source format, and storage type.
Some of the common properties that can be configured in hoodie.properties file or in the Spark Dataframe while writing to Hudi table are:
-
hoodie.datasource.write.recordkey.field: Specifies the name of the field in the input data that contains the record key. This property is used to determine the primary key for the Hudi table. -
hoodie.datasource.write.partitionpath.field: Specifies the name of the field in the input data that contains the partition path. This property is used to determine the directory structure for storing data in Hudi tables. -
hoodie.datasource.write.precombine.field: Specifies the name of the field in the input data that is used for pre-aggregation before writing data to Hudi tables. -
hoodie.upsert.shuffle.parallelism: Specifies the number of partitions to be used for shuffling data during upsert operations. -
hoodie.cleaner.policy: Specifies the cleanup policy to be used for deleting old data from Hudi tables. -
hoodie.datasource.write.keygenerator.class: Specifies the class that should be used to generate record keys. -
hoodie.datasource.write.table.type: specifies the table type for a Hudi table. The value for this property can be eitherCOPY_ON_WRITEorMERGE_ON_READ. -
hoodie.datasource.write.operation: Specify the type of write operation to be performed on a Hudi table during a write operation. It supports the following write operations:
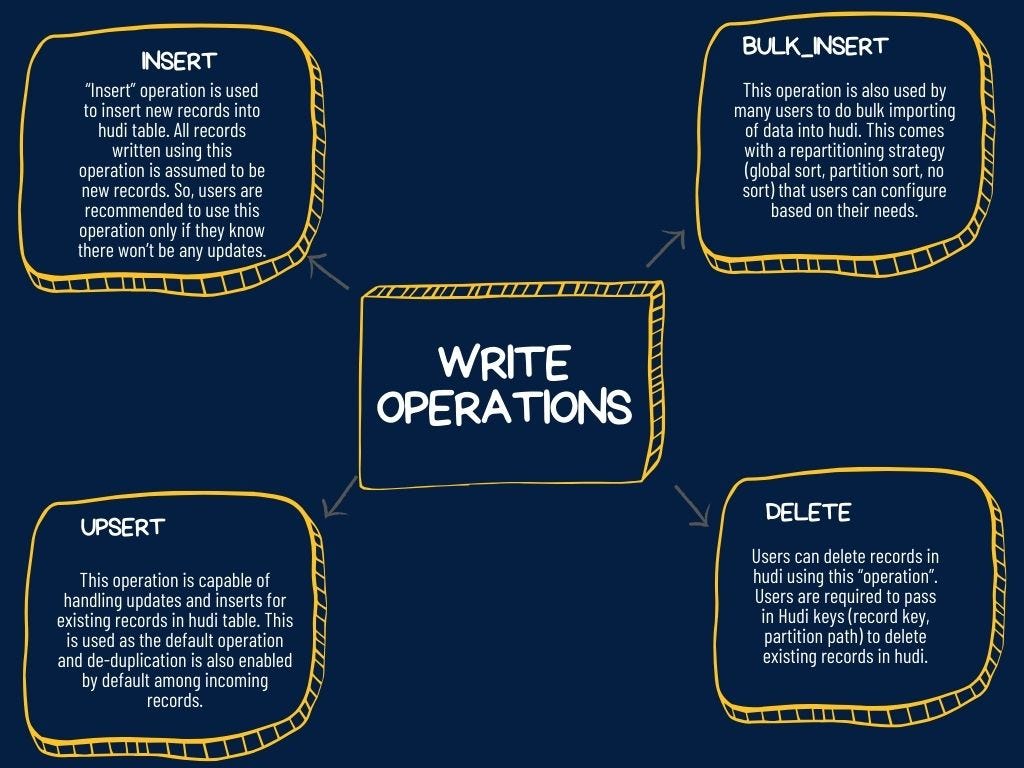 Write Operations of Hudi
Write Operations of HudiThe hoodie.datasource.write.operation property is usually set at the application level, but it can also be set at the dataset level by including it as an option in the write configuration.
-
hoodie.table.name: Specifies the name of the Hudi table that will be created or written to. It is a mandatory property that must be set before creating a new Hudi table or writing to an existing one.
hoodie.properties file can be passed as a configuration file while running the Hudi job using the — hoodie-conf parameter or can be added to the classpath of the Hudi application.
# Hoodie Properties
root@<servername>:/# gsutil cat gs://<Bucket>/<Schema>/store_visit_scan_fdl_kt_blog/.hoodie/hoodie.properties
#Updated at 2023-05-16T15:32:08.165Z
#Tue May 16 15:32:08 UTC 2023
hoodie.table.precombine.field=src_rcv_ts
hoodie.datasource.write.drop.partition.columns=false
hoodie.table.partition.fields=trans_dt
hoodie.table.type=COPY_ON_WRITE
hoodie.archivelog.folder=archived
hoodie.timeline.layout.version=1
hoodie.table.version=5
hoodie.table.metadata.partitions=files
hoodie.table.recordkey.fields=id,trans_nbr,seq_nbr
hoodie.database.name=<DB name>
hoodie.datasource.write.partitionpath.urlencode=false
hoodie.table.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator
hoodie.table.name=trans_fdl_blog
hoodie.datasource.write.hive_style_partitioning=true
hoodie.table.checksum=3686519666
hoodie.table.create.schema={“type”:“record”,“name”:“trans_fdl_blog_record”,“namespace”:“hoodie.trans_fdl_blog”,“fields”:[{“name”:”_hoodie_commit_time",“type”:[“string”,“null”]},{“name”:“_hoodie_commit_seqno”,“type”:[“string”,“null”]},{“name”:“hoodie_record_key",“type”:[“string”,“null”]},{“name”:"hoodie_partition_path",“type”:[“string”,“null”]},{“name”:"hoodie_file_name",“type”:[“string”,“null”]},{“name”:“trans_nbr”,“type”:[“string”,“null”]},{“name”:“id”,“type”:[“int”,“null”]},{“name”:“seq_nbr”,“type”:[“int”,“null”]},{“name”:“item_nbr”,“type”:[“int”,“null”]},{“name”:“item_type”,“type”:[“int”,“null”]},{“name”:“src_rcv_ts”,“type”:[{“type”:“long”,“logicalType”:“timestamp-micros”},“null”]},{“name”:“load_ts”,“type”:[{“type”:“long”,“logicalType”:“timestamp-micros”},“null”]},{“name”:“trans_dt”,“type”:[{“type”:“int”,“logicalType”:“date”},“null”]}]}
Read from Hudi Table with Hudi API:
Hudi uses the record key to uniquely identify each record within a partition. The record key is used to ensure that records are not duplicated and to support efficient queries and updates.
Retrieval Process:
The Hudi client reads the timeline of the Hudi table. The timeline is a record of all the changes that have been made to the table, such as inserts, updates, and deletes. The Hudi client uses the timeline to determine the latest committed state of the table. The latest committed state is the set of all records that have been written to the table and are not yet deleted.
The Hudi client reads the data files that correspond to the latest committed state of the table. The data files are stored in a directory structure on the filesystem. The Hudi client merges the data files to create a single logical view of the data. This is done to improve performance and simplify queries. The Hudi client returns the data to the user.
import org.apache.spark.sql.SaveMode.
import org.apache.hudi.DataSourceWriteOptions.
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.DataSourceReadOptions.
import org.apache.hudi.DataSourceReadOptions
import org.apache.spark.sql.DataFrame
val hudiIncQueryDF = spark.read.format(“hudi”).load(targetPath)
hudiIncQueryDF.createOrReplaceTempView(“trans_fdl_hudi_v”)
spark.sql(s”““select * from trans_fdl_hudi_v””“).show(50,false)
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path|_hoodie_file_name |trans_nbr|id |seq_nbr|item_nbr|item_type|src_rcv_ts |load_ts |trans_dt |
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|20230516153138932 |20230516153138932_0_0|id:23,trans_nbr:ABC1234,seq_nbr:4|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |4 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:02:57.529|2023-05-16|
|20230516153138932 |20230516153138932_0_1|id:23,trans_nbr:ABC1234,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |1 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:00:38.64 |2023-05-16|
|20230516153138932 |20230516153138932_0_2|id:23,trans_nbr:ABC1234,seq_nbr:2|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |2 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:13.485|2023-05-16|
|20230516153138932 |20230516153138932_0_3|id:23,trans_nbr:ABC1234,seq_nbr:3|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC1234 |23 |3 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:35.462|2023-05-16|
|20230516153138932 |20230516153138932_0_4|id:23,trans_nbr:ABC2567,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC2567 |23 |1 |434545 |0 |2023-05-16 11:00:00|2023-05-16 15:03:24.612|2023-05-16|
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
Query Types
- Snapshot Queries : Queries see the latest snapshot of the table as of a given commit or compaction action. In case of merge on read table, it exposes near-real time data(few mins) by merging the base and delta files of the latest file slice on-the-fly. For copy on write table, it provides a drop-in replacement for existing parquet tables, while providing upsert/delete and other write side features.
- Incremental Queries : Queries only see new data written to the table, since a given commit/compaction. This effectively provides change streams to enable incremental data pipelines.
- Read Optimized Queries : Queries see the latest snapshot of table as of a given commit/compaction action. Exposes only the base/columnar files in latest file slices and guarantees the same columnar query performance compared to a non-hudi columnar table.
 Supported Query types of COW and MOR
Supported Query types of COW and MORSnapshot Queries
val hudiIncQueryDF = spark.read.format(“hudi”).option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL).load(targetPath)
hudiIncQueryDF.createOrReplaceTempView(“trans_hudi_inc_v”)
spark.sql(”““select * from trans_hudi_inc_v where trans_dt=‘2023-05-16’ and trans_nbr=‘ABC2567’ order by seq_nbr””“).show(50,false)
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path|_hoodie_file_name |trans_nbr|id |seq_nbr|item_nbr|item_type|src_rcv_ts |load_ts |trans_dt |
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|20230516153138932 |20230516153138932_0_4|id:23,trans_nbr:ABC2567,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-40-1438_20230516153138932.parquet|ABC2567 |23 |1 |434545 |0 |2023-05-16 11:00:00|2023-05-16 15:03:24.612|2023-05-16|
±------------------±--------------------±--------------------------------±---------------------±-------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
Incremental Query:
Lets insert new trans Nbr “ABC9876 and ABC9878” records into the Hudi table and select only the incremental records using Incremental Query.
#Inserted Trans Nbr ABC9876 and ABC9878 into Hudi Table
spark.sql(“select * from <schema_name>.trans_fdl_blog”).show(20,false)
±------------------±--------------------±--------------------------------±---------------------±--------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path|_hoodie_file_name |trans_nbr|id |seq_nbr|item_nbr|item_type|src_rcv_ts |load_ts |trans_dt |
±------------------±--------------------±--------------------------------±---------------------±--------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
|20230516163909156 |20230516163909156_0_4|id:23,trans_nbr:ABC2567,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC2567 |23 |1 |434545 |0 |2023-05-16 11:00:00|2023-05-16 15:03:24.612|2023-05-16|
|20230516171040329 |20230516171040329_0_6|id:23,trans_nbr:ABC9876,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC9876 |23 |1 |434545 |0 |2023-05-16 06:00:00|2023-05-16 17:05:17.196|2023-05-16|
|20230516171829482 |20230516171829482_0_7|id:23,trans_nbr:ABC9878,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC9878 |23 |1 |434545 |0 |2023-05-16 19:00:00|2023-05-16 17:14:44.365|2023-05-16|
|20230516163909156 |20230516163909156_0_1|id:23,trans_nbr:ABC1234,seq_nbr:1|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC1234 |23 |1 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:00:38.64 |2023-05-16|
|20230516171040329 |20230516171040329_0_5|id:23,trans_nbr:ABC9876,seq_nbr:2|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC9876 |23 |2 |434545 |0 |2023-05-16 06:00:00|2023-05-16 17:05:30.444|2023-05-16|
|20230516163909156 |20230516163909156_0_2|id:23,trans_nbr:ABC1234,seq_nbr:2|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC1234 |23 |2 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:13.485|2023-05-16|
|20230516171829482 |20230516171829482_0_8|id:23,trans_nbr:ABC9878,seq_nbr:2|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC9878 |23 |2 |434545 |0 |2023-05-16 19:00:00|2023-05-16 17:14:55.865|2023-05-16|
|20230516163909156 |20230516163909156_0_3|id:23,trans_nbr:ABC1234,seq_nbr:3|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC1234 |23 |3 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:01:35.462|2023-05-16|
|20230516163909156 |20230516163909156_0_0|id:23,trans_nbr:ABC1234,seq_nbr:4|trans_dt=2023-05-16 |540122b8-fbc5-4319-85a8-915b570bd4b0-0_0-259-8283_20230516171829482.parquet|ABC1234 |23 |4 |434545 |0 |2023-05-16 09:00:59|2023-05-16 15:02:57.529|2023-05-16|
±------------------±--------------------±--------------------------------±---------------------±--------------------------------------------------------------------------±--------±–±------±-------±--------±------------------±----------------------±---------+
# Incremental query to fetch only last two commits
val commits = spark.sql(“select distinct(_hoodie_commit_time) as commitTime from trans_hudi_inc_v order by commitTime”).map(k => k.getString(0)).take(50)
# commits: Array[String] = Array(20230516163909156, 20230516171040329, 20230516171829482)
#commit time we are interested in
val beginTime = commits(commits.length-3)
#Incremental query with Begin Timestamp to select the records
val IncrementalDF = spark.read.format(“hudi”).option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, beginTime).load(targetPath)
IncrementalDF.createOrReplaceTempView(“hudi_incremental”)
spark.sql(”““select * from hudi_incremental order by trans_nbr,seq_nbr””").show(100)
±------------------±-------------------±-------------------±---------------------±-------------------±--------±–±------±-------±--------±------------------±-------------------±---------+
|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|trans_nbr| id|seq_nbr|item_nbr|item_type| src_rcv_ts| load_ts| trans_dt|
±------------------±-------------------±-------------------±---------------------±-------------------±--------±–±------±-------±--------±------------------±-------------------±---------+
| 20230516171040329|20230516171040329…|id:23,trans_nbr:A…| trans_dt=2023-05-16|540122b8-fbc5-431…| ABC9876| 23| 1| 434545| 0|2023-05-16 06:00:00|2023-05-16 17:05:…|2023-05-16|
| 20230516171040329|20230516171040329…|id:23,trans_nbr:A…| trans_dt=2023-05-16|540122b8-fbc5-431…| ABC9876| 23| 2| 434545| 0|2023-05-16 06:00:00|2023-05-16 17:05:…|2023-05-16|
| 20230516171829482|20230516171829482…|id:23,trans_nbr:A…| trans_dt=2023-05-16|540122b8-fbc5-431…| ABC9878| 23| 1| 434545| 0|2023-05-16 19:00:00|2023-05-16 17:14:…|2023-05-16|
| 20230516171829482|20230516171829482…|id:23,trans_nbr:A…| trans_dt=2023-05-16|540122b8-fbc5-431…| ABC9878| 23| 2| 434545| 0|2023-05-16 19:00:00|2023-05-16 17:14:…|2023-05-16|
±------------------±-------------------±-------------------±---------------------±-------------------±--------±–±------±-------±--------±------------------±-------------------±---------+
Summary:
The Hudi COW table’s performance benefits come from its ability to write data in batches and to efficiently merge small files into larger ones using compaction. This reduces the number of files and improves the query performance, making it possible to process large datasets quickly and efficiently.
In summary, Hudi COW tables are a powerful and flexible way to ingest, store, and query large datasets. It provides ACID guarantees, supports schema evolution and time travel queries, and offers high performance and scalability.
Author:
Eswaramoorthy P — Data Engineer III
References:
- Hudi Documentation — https://hudi.apache.org/docs/concepts/
Demystifying Copy-on-Write in Apache Hudi: Understanding Read and Write Operations was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.