Cross DC(data center) replication is process by which data in one or more Solr clusters running independently in different DC are in sync. This essentially means if an update comes in one Solr cluster it is propagated or made available in other Solr clusters so that search results are consistent between Solr clusters.
Need for Cross DC replication in Solr
Below are some reasons why Cross DC replication in Solr are required:
Disaster recovery: In case a particular datacenter is down/unavailable for any reason it would be good to have a different datacenter available and in sync so that application can be failed over to new datacenter without huge downtime.
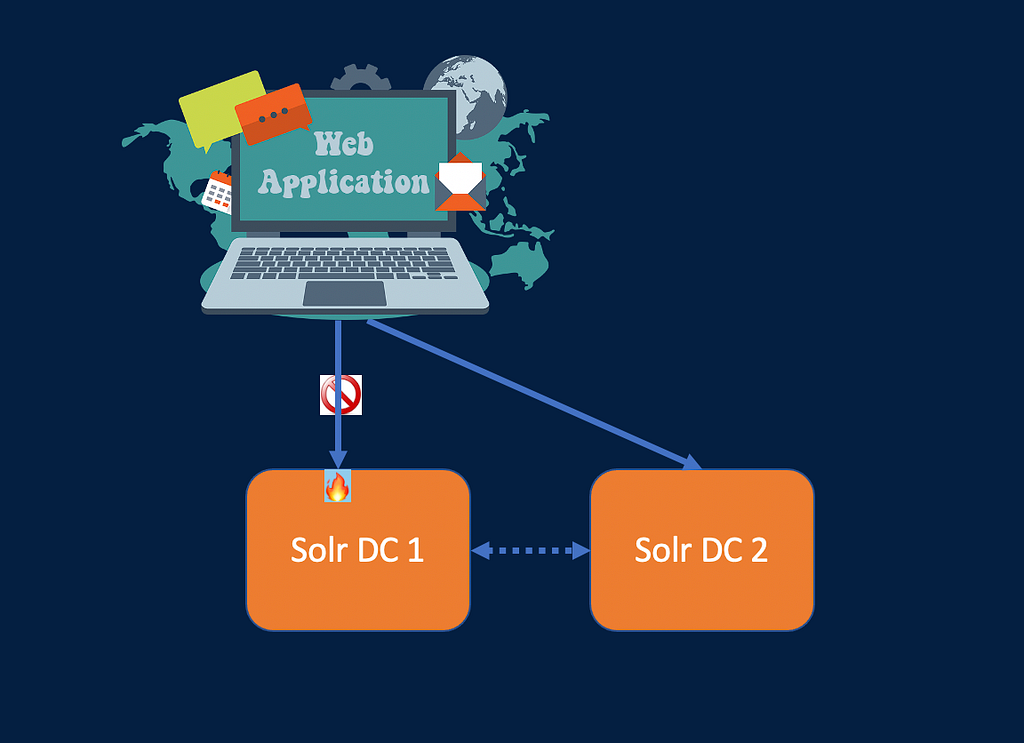
Reduce latency: In a distributed service you would want client applications to connect to Solr clusters which are closer geographically there by improving search latency.
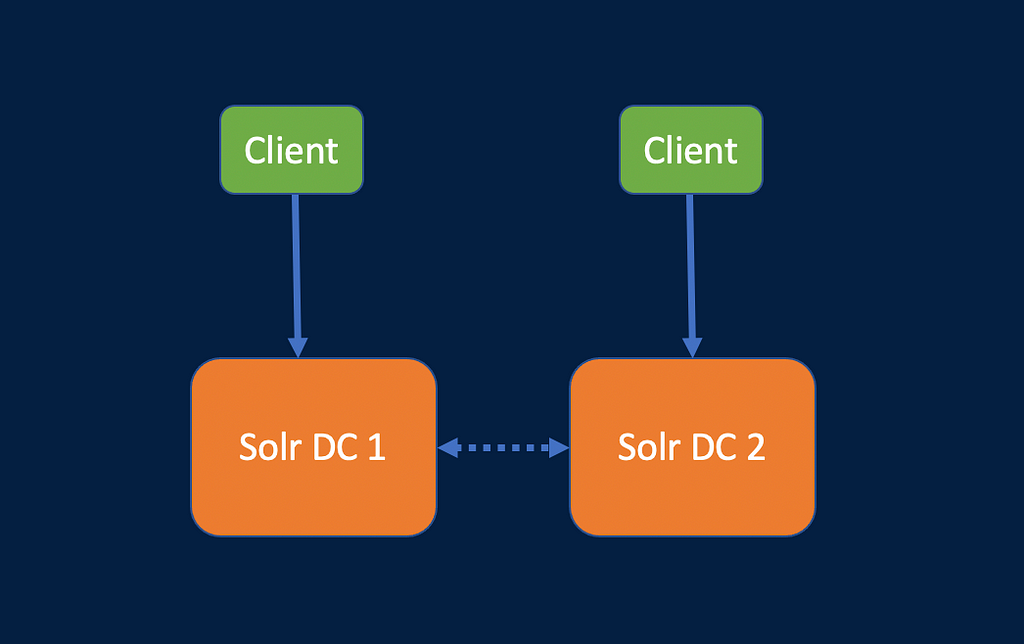
Approaches to achieve cross DC replication in Solr
- Cross DC replication by Solr: Cross DC replication by Solr has number of bugs and quite unstable because of how it is designed. This feature is already deprecated and will be removed in Solr 9.0. For architecture of CDCR by Solr refer. For issue details refer
- Cross DC replications using queues:
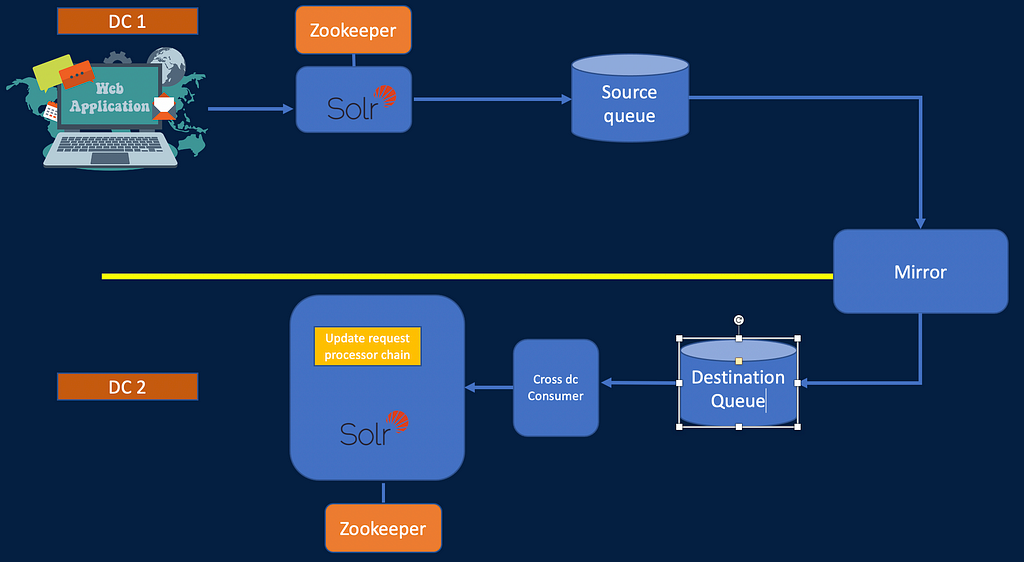 This diagram shows 1 way replication assuming 1 active DC
This diagram shows 1 way replication assuming 1 active DC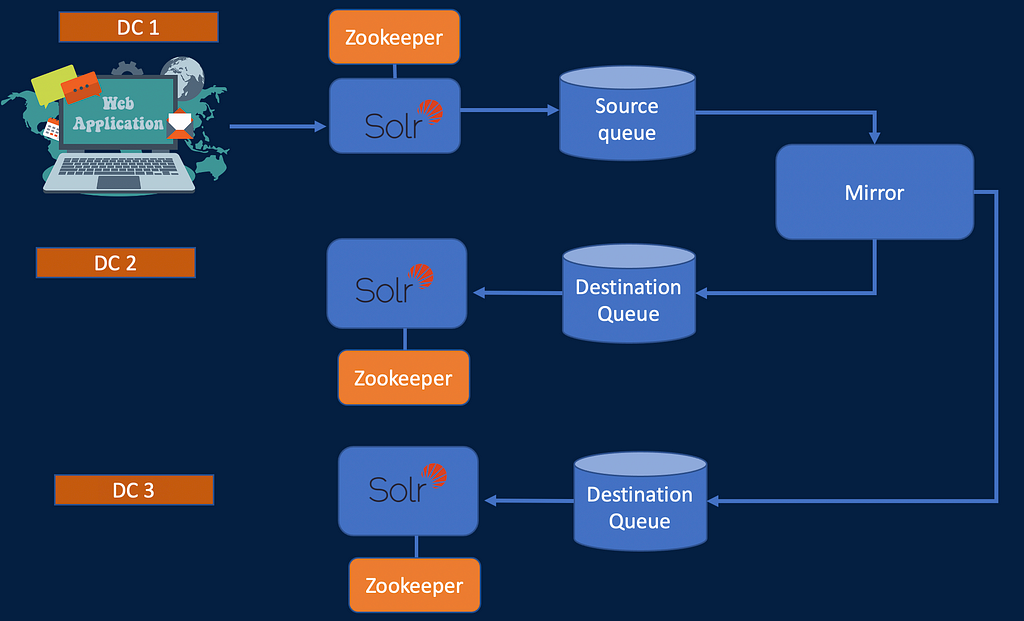 The above diagram shows N way replication assuming 1 active DC
The above diagram shows N way replication assuming 1 active DCThis approach helps in setting by N-way replication. Some important components are below:
- Update request processor chain: All update requests originating from the client application goes through the update request processing chain and it only accepts/inserts the document if it is a new record or the version of the document is greater than the existing version in the cluster. It also sends the request in the queue which then gets replicated to N data centres based on the configuration.
- Cross DC consumer application: This application reads the data from the destination queue and submits to the destination Solr cluster. It also handles resubmission to the destination queue in case of failure.
- Handling deletes: Deleting data is bit tricky in case of CDCR set up as you would not want accidental data deletes to get replicated and also deleted from other datacenter. So in this set up delete by query requests are disabled and delete by id requests are converted to an update requests which marks the associated documents as deleted so that it does not appear in any search results. Separate job is set up to clean up these documents that are marked as deleted.
- Inconsistency detection: It is important to detect data inconsistency between the DC to ensure search results are consistent between the Solr clusters. Along with checking the document count it is important to check the combination of document id and version is consistent between the Solr clusters. For fixing the inconsistency detected there can be a separate job to do it. More details on inconsistency detection and healing will be covered in a separate blog.
- Failure condition: In case source queue which is responsible to sync the writes to the other DC queue is not available for any reason it would not affect the writes happening to the source Solr DC as the only the async event listener would receive failure and also failed requests by event listener would be written to a separate queue.
3. Client based multi write: Another way to keep 2 Solr DC in sync is by client application doing multi write to both the DC. Here client application holds the responsibility to write the data in both the DC. Client application manages request failures and retry. This approach has many challenges some of them are duplication of efforts by the client, there needs to be a way to check consistency and alert in case of inconsistency identified, handling when 1 DC is not available. Also when providing a managed service, client/customers will always would want data replications to be handled by the platform.
Summary
Cross DC replication set up using queues helps in setting up N way replication between multiple Solr clusters in scalable manner.
Cross data center replication in Solr was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Cross data center replication in Solr | by george chakkalakkal | Walmart Global Tech Blog | Medium