Introduction
Tech Enterprises operates on a massive scale with thousands of internal APIs powering various systems and services. These APIs serve as the backbone of their operations, enabling seamless integration between different applications and driving efficiency across the organization.
One major hurdle faced by organizations with vast API ecosystems is the discoverability problem. With numerous APIs spread across different departments and teams, it becomes increasingly challenging for developers and stakeholders to identify the right APIs for their specific needs. This lack of discoverability often leads to redundant or inefficient development efforts, resulting in wasted time and resources.
To address this issue, we can leverage the power of language models, specifically Large Language Models (LLMs), to enable users to interact with API documentation using natural language. By incorporating LLMs into our solution, we can bridge the gap between users and API documentation, providing an intuitive and user-friendly conversational experience.
In addition to LLMs, we can utilize tools built around LLMs such as LangChain. LangChain is a framework for developing applications powered by language models. It is designed to simplify the creation of applications using large language models (LLMs) and its use-cases largely overlap with those of language models in general, including document analysis and summarization, chatbots, and code analysis. The core idea of the library is that we can “chain” together different components to create more advanced use cases around LLMs. There are alternatives to LangChain such as LLamaIndex, AutoGPT and SimpleAIChat which can also be explored for building applications on LLMs.
Furthermore, we can leverage Vector DBs, which are highly optimised databases for storing and retrieving vector embeddings. By indexing API documentation using vector embeddings, we can efficiently search and match user queries with relevant information. This enables us to deliver accurate and contextual results, empowering users to discover and extract the information they need from API documentation with low latency.
In this blog, we will delve into the intricacies of the solution, exploring the integration of LLMs, LangChain, and Vector DBs to create a powerful platform for discovering and extracting information from APIs using natural language.
APIs metadata generally contains certain fields such as API Endpoint, method (POST, GET), description, Example input / output etc. We will be using this metadata as our API documentation.
Tech
In order to create a Conversational bot on our API documents, we will essentially require 3 major modules:
- Document Preprocessing
- Document Retrieval
- Response Generation
Document Preprocessing
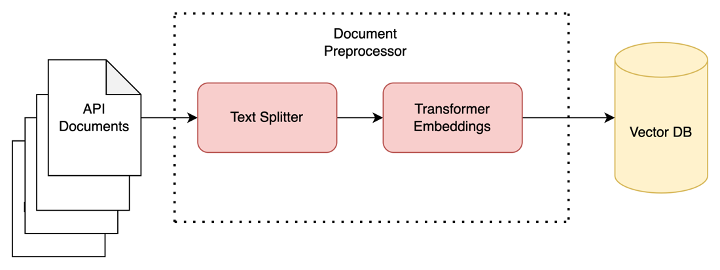
The goal of this module is to read the text files containing documentation of APIs to generate semantic embeddings and store them in a vector database using the LangChain. It starts by reading and decoding a list of uploaded files followed by the CharacterTextSplitter to split the text into chunks of given size. The resulting list of texts is then passed to the SentenceTransformerEmbedding class, which generates embeddings using the all-MiniLM-L6-v2 model. These embeddings are then loaded into a Chroma / Milvus vector database.
Note: Document Preprocessing is a onetime process which should be only triggered if any new document is added.
Let’s discuss more about these components:
1. CharterTextSplitter:
CharterTextSplitter takes in a list of texts and splits each text into chunks based on the specified chunk size. The size of each chunk is determined by the chunksize property. It’s important to split longer documents since generating embeddings and responses from most of the modern LLMs have input size limitations.
2. SentenceTransformerEmbeddings:
SentenceTransformerEmbeddings is a LangChain class that provides an interface for generating text embeddings using the SentenceTransformers package. SentenceTransformers can generate text and image embeddings, originating from Sentence-BERT.
The SentenceTransformerEmbeddings class takes in a model_name parameter when initialising an instance, which specifies the pre-trained model to use for generating embeddings.
We can use all-MiniLM-L6-v2 model here. The all-MiniLM-L6-v2 model is a sentence- transformers model that maps sentences and paragraphs to a 384-dimensional dense vector space.
3. Chroma DB:
Chroma is an open-source, AI-native embedding database that allows you to store embeddings and their metadata and search through the database of embeddings. It is designed to provide faster similarity searches which are essential to building low latency QA / Conversation bots.
 Document Preprocessing
Document PreprocessingNow once we have transformed our Data to Embeddings and stored it in Vector DB, let’s look at how Response Generation can be achieved.
Document Retrieval + Response Generation
One of the biggest limitations of modern LLMs is context (input) size. Recent models can only handle context sizes in the range of 4k –8k. Though models are being developed with context sizes as large as 100K, directly providing the whole set of documents to LLMs is not scalable.
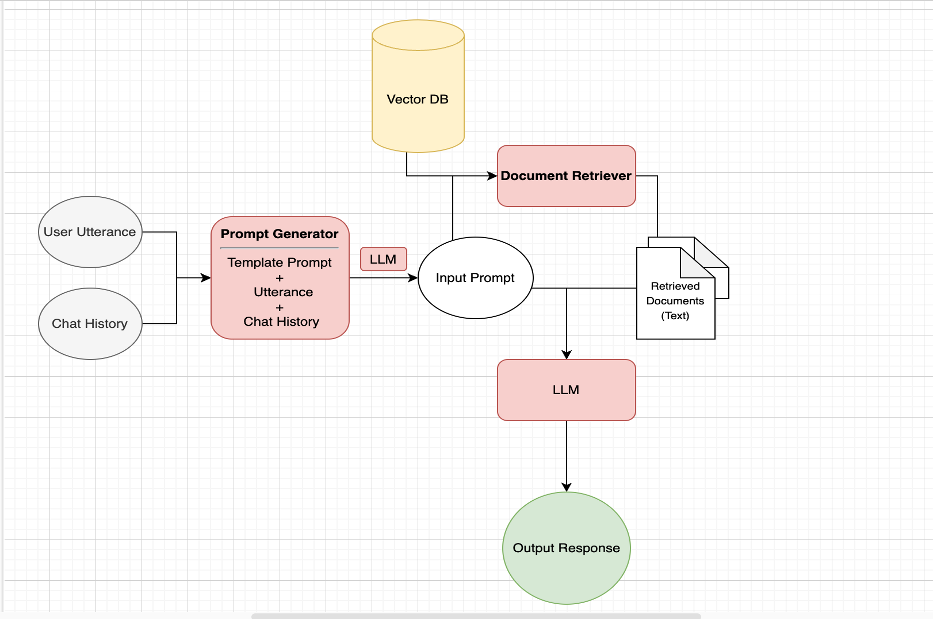
The approach that can be taken instead is a 2-step process of retrieving the most relevant documents from the corpus and then passing them to LLM along with user query for Response generation.
Frameworks like LangChain combine this 2-step process into a single API as discussed below.
Let’s discuss in detail how this works.
1. Prompt Generator
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template("""Given the following
conversation and follow up question, rephrase follow up question to be a
standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:""")The very first step is to create a prompt combining Task instruction, Current user utterance and Chat History as shown above. Once we have this prompt, we will move to the next steps.
2. Document Retriever + Response Generator
LangChain abstracts Document retrieval and Response Generation by ConversationalRetrievalChain API.
llm -> Any relevant LLM supported by Langchain
qa = ConversationalRetrievalChain.from_llm(llm=llm,
retriever=db.as_retriever(),
condense_question_prompt = CONDENSE_QUESTION_PROMPT,
return_source_documents=True)
RetrievalQAChain is a component of LangChain to answer questions over documents in a natural and interactive way. It is a combination of a document retriever and a question answering chain. It works by finding relevant documents that contain the information needed to answer the question, and then generating a response based on the question and the retrieved documents.
The ConversationalRetrievalChain is a component of LangChain that builds on the RetrievalQAChain to provide a chat history component.
ConversationalRetrievalChain is performing Following steps:
- Rephrasing input to standalone question
- It first combines the chat history (either explicitly passed in or retrieved from the provided memory) and the question into a standalone question using LLM - Retrieving documents
- Looks up relevant documents from the retriever based on this Standalone Question - Asking question with provided context
- Passes those documents and the question to a question answering chain to return a response using given LLM
The ConversationalRetrievalChain is very similar to the RetrievalQAChain, but it adds an additional parameter to pass in chat history which can be used for follow-up questions. This allows for more natural and context-aware conversations, as the chain can take into account previous interactions when generating responses.
result = qa ({"question": query, "chat_history": chat_history})
print ( result ["answer"] )Finally, we can obtain the generated output by passing input dictionary containing query and chat_history.
 Architecture
ArchitectureResults
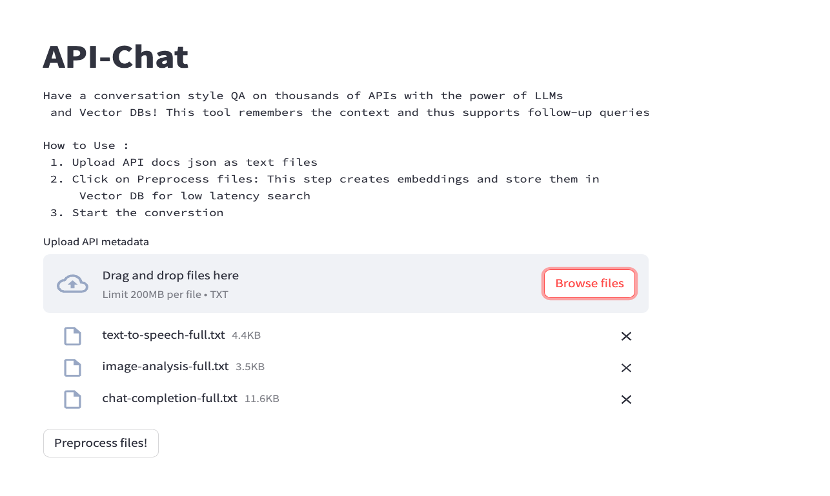
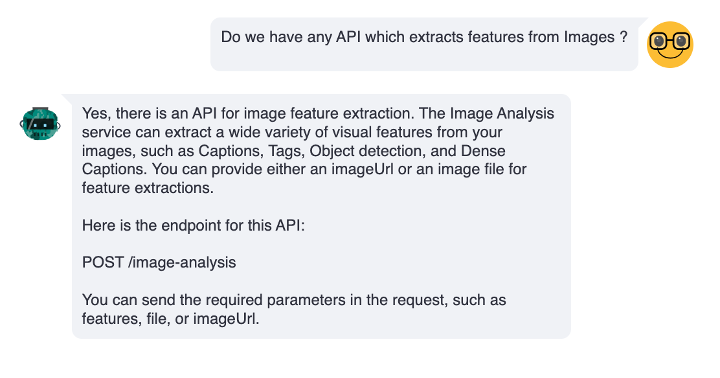
We added a few API docs and tried the conversation bot.
 Document Preprocessing
Document PreprocessingConversations
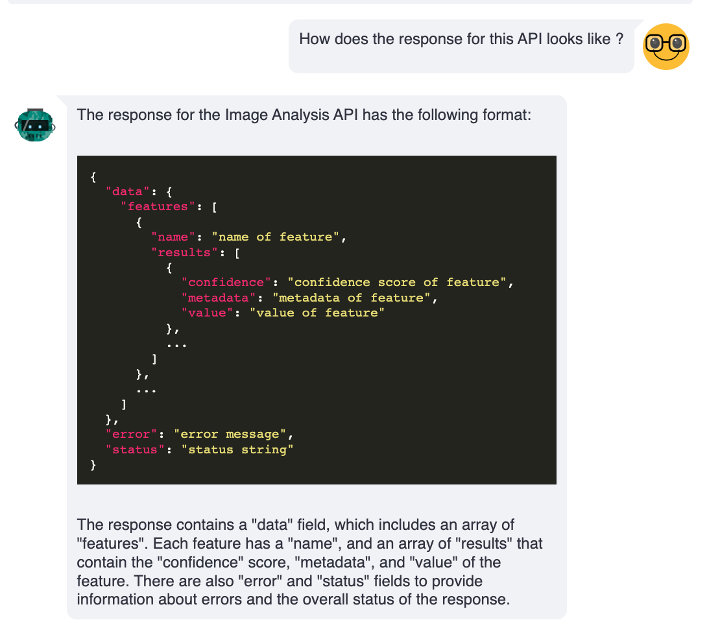
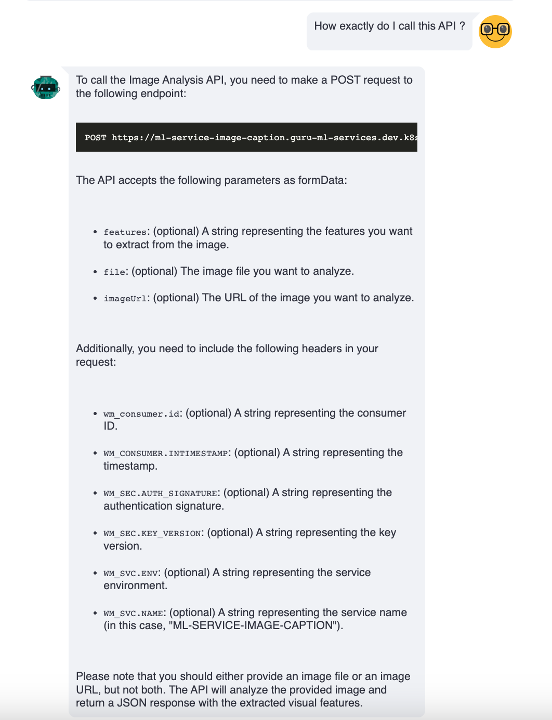 Conversation
ConversationConclusion
The combination of LLM Agents and modern LLMs offers a huge potential for improving internal knowledge accessibility across organisations by utilising an intuitive natural language conversation interface. This tech is not just limited to text files but can directly be applied to other Data types such as CSVs, SQL DBs, pdfs etc. using LLM connectors and Agents. While this looks exciting, one must be aware of potential limitations of LLMs like Hallucination, Data Privacy and inconsistency.
References
Conversational Bot for Enterprise APIs using LLM Agents, VectorDB and GPT4 was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.