Thejasvini K S, Indranath Bardhan, Priyanka Sahoo and Communication Service Team
Introduction
Placing the customer at the forefront is of utmost importance at Walmart. This involves timely communication with customers like timely grocery deliveries. This led us to develop a communication service architecture that is resilient, fault-tolerant, fail-safe, rapid and time-sensitive.
The vital component
One of the key features that contribute to Kafka’s success is its ability to partition data across multiple brokers. This partitioning mechanism ensures efficient data distribution and processing, but what if your use case demands a more nuanced approach? Enter custom partitioning in Kafka — a powerful technique that empowers you to tailor data distribution according to your specific requirements.
In this article, we will embark on a journey to explore the world of custom partitioning in Kafka. We’ll delve into the reasons behind opting for custom partitioning, the mechanics behind it, and practical scenarios where it can add tremendous value to us.
Why Custom Partitioning?
Kafka employs a partitioning strategy based on hashing by default, distributing messages evenly across available partitions. While this approach works well for many use cases, custom partitioning helps us with solving Data Skewing, Cost Optimisation, Optimal Resource Usage with Increased Performance. Below there are scenarios where custom partitioning offers distinct advantages:
- Multi-Tenancy: In the case of supporting multi-tenants as a platform one of the options is by creating multiple topics but in this case Kafka custom partitioning can also be leveraged which enables to isolate data for different tenants into blocks of partitions and allocate partitions based on their requirements and usage. Increased topics creates challenges like onboarding new tenants dynamically, monitoring, configure, and maintain it, also introduces complexity at the consumer level dealing with subscriptions to multiple topics and increased latency at broker level. While increasing partitions has issues of resource fragmentation at brokers, slower processing, and increased latency. Thus, leveraging custom partitioning and optimizations based on performance test results will balance out and gives the best out of both approaches.
- Prioritization: While introducing various message types of messages with distinct levels of time sensitivity we leveraged custom partitioning rather than creating different topics as this helped us optimize the resource usage, cost, and performance with a room tune and control the business needs of meeting the SLA (Service Level Agreements) turnaround times for different message types, we assigned a bigger chunk of partition to the priority message, less to the transactional messages and lesser to the reminder messages.
- Prioritisation: When managing various message types with distinct levels of time sensitivity with the same resource allocation at Kafka is to increase the number of partitions assigned for priority messages and reduce the partitions for the message type which is not time sensitive.
- Throttling: In some cases, the downstream system has restriction on the incoming TPS (Transactions Per Seconds), and in case of multi-tenant systems depending on the agreements we can assign less partitions to one tenant and more to another and throttle the requests based on the service agreements between downstream and different tenants.
- Geographical Data: In case of surge of traffic is expected from a particular city or geography, we design a custom partitioning to ensure optimal number partitions are allocated to that region based on business needs. This minimizes latency and enhances prioritization for that geographic location at that time as well if needed according to business use cases.
Mechanics of Custom Partitioning
Implementing custom partitioning in Kafka involves understanding and extending the org.apache.kafka.clients.producer.Partitioner interface. This interface defines two essential methods:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)
The above method takes the topic, key, value, and the current cluster state as parameters, and returns the index of the selected partition.
To create a custom partitioner, you can extend the Partitioner interface and implement the partitioning logic within the partition method. This could involve anything from simple business rules to complex algorithms that consider several factors for partition assignment.
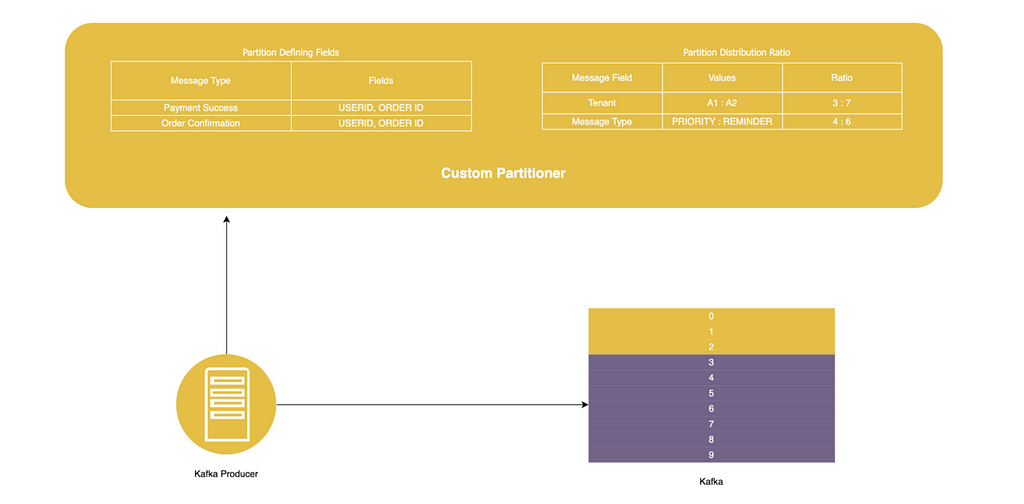 Custom Partitioner
Custom PartitionerImplementation
public class CustomPartitionerTest implements Partitioner {
static final Map<String, Map<String, PartitionValue>> partitionRangeCache = Maps.newHashMap();
static Map<String, PartitionConfig> partitionConfig = Maps.newHashMap();
@Override
public int partition(
String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
int numOfPartition = cluster.partitionsForTopic(topic).size();
try {
partitionConfig = getPartitionConfig(partitionConfig, numOfPartition, topic);
if (partitionConfig.containsKey(topic)) {
String partitionParam =
getPartitionParam(
value.toString(), partitionConfig.get(topic).getPaths());
if (!partitionRangeCache.containsKey(topic)
|| !partitionRangeCache.get(topic).containsKey(partitionParam)) {
partitionRangeCache.put(
topic,
populateRangesForPartition(
partitionConfig.get(topic).getPartitionFactor(), numOfPartition));
}
PartitionValue partitionRangeParamWise = partitionRangeCache.get(topic).get(partitionParam);
return partitionRangeParamWise.getStart()
+ Utils.toPositive(Utils.murmur2(keyBytes)) % partitionRangeParamWise.getSize();
} else return Utils.toPositive(Utils.murmur2(keyBytes)) % numOfPartition;
} catch (Exception e) {
throw new CustomPartitionerException(ErrorCode.CONFIG_PARSE_EXCEPTION.getErrorCode(), e);
}
}
public static String getPartitionParam(String inputPayload, List<String> paths)
throws CustomPartitionerException {
if (paths.size() == 0) {
throw new CustomPartitionerException(
ErrorCode.JSON_DATA_NOT_FOUND.getErrorCode(), "JsonPaths is empty in Config");
}
StringJoiner stringJoiner = new StringJoiner("-");
for (String path : paths) {
try {
String value = JsonUtility.getDataPoint(inputPayload, path);
if (!ObjectUtils.isEmpty(value)) stringJoiner.add(value);
} catch (Exception exception) {
throw new CustomPartitionerException(
ErrorCode.JSON_PROCESSING_EXCEPTION.getErrorCode(), exception);
}
}
return stringJoiner.toString();
}
public static Map<String, PartitionValue> populateRangesForPartition(
LinkedHashMap<String, Double> partitionFactor, int numPartition)
throws CustomPartitionerException {
Map<String, PartitionValue> partitionRanges = Maps.newHashMap();
int previous = 0;
int partitionFactorSize = partitionFactor.size();
int index = 0;
for (Map.Entry<String, Double> entry : partitionFactor.entrySet()) {
index++;
int range =
index == partitionFactorSize
? numPartition - previous
: (int) Math.floor(numPartition * entry.getValue());
partitionRanges.put(entry.getKey(), new PartitionValue(previous, range));
previous = previous + range;
}
return partitionRanges;
}
public static Map<String, PartitionConfig> getPartitionConfig(
Map<String, PartitionConfig> partitionConfigCache, int noOfPartitions, String topic)
throws CustomPartitionerException {
if (!partitionConfigCache.isEmpty()) return partitionConfigCache;
if (Strings.isNullOrEmpty(getPartitionConfigString()))
throw new CustomPartitionerException(MISSING_CONFIG_EXCEPTION.getErrorCode());
Map<String, PartitionConfig> partitionConfig;
try {
partitionConfig =
new ObjectMapper()
.readValue(
getPartitionConfigString(),
new TypeReference<Map<String, PartitionConfig>>() {});
} catch (IOException e) {
throw new CustomPartitionerException(JSON_PROCESSING_EXCEPTION.getErrorCode());
}
return partitionConfig;
}
private static String getPartitionConfigString() {
return "{\"topic-name\":{\"paths\":[\"$.tenant\"],\"partitionFactor\":{\"tenant1\":0.8,\"tenant2\":0.1,\"tenant3\":0.1}}}";
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}Conclusion
Apache Kafka’s default partitioning strategy works well in many scenarios, but there are times when custom partitioning can provide a significant performance boost and enable more tailored data distribution. By understanding the mechanics of custom partitioning and exploring practical use cases, we have harnessed this feature to cater to our specific needs, resource utilisation, and overall system efficiency.
Building Walmart’s Seamless Communication: Leveraging Kafka’s Custom Partitioning was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.