 Image Source:
Image Source: In today’s fast-paced and data-driven world, businesses need to process and analyze vast amounts of data in real-time to gain insights and make informed decisions. This is where Kafka and streaming technologies come in. Apache Kafka is an open-source distributed event streaming platform that can handle high volumes of data from various sources in real-time. Kafka allows users to publish, subscribe, and process data streams in a fault-tolerant, scalable, and distributed manner.
Streaming technology, on the other hand, is the processing of continuous and unbounded data streams in real-time. This technology enables organizations to analyze and gain insights from data as it is generated, rather than processing data in batches after the fact.
Kafka and streaming technologies, such as Spark Streaming and Structured Streaming, can be combined to provide a powerful solution for processing and analyzing streaming data.
There can be confusion between Spark Streaming and Spark Structured Streaming when choosing which one to use with Kafka because both can be used to process data from Kafka. Spark Streaming is a mature and well-established framework that has been used with Kafka for many years. However, Spark Structured Streaming provides a more modern and declarative API that allows developers to express their processing logic in SQL-like queries. In this Blog, we will cover the below topics in Detail.
- Spark vs Structured Streaming
- Advantages of Structured Streaming
- Structured Streaming with Kafka
Spark Streaming vs Structured Streaming
Spark Streaming and Structured Streaming are both components of Apache Spark, but they differ in their approach to processing streaming data.
Spark Streaming is based on micro-batch processing, where data is processed in small batches at fixed time intervals. The data is ingested from a source such as Kafka or Flume, and then transformed using Spark’s RDD (Resilient Distributed Datasets) API. Spark Streaming uses batch processing techniques to provide low-latency processing of streaming data.
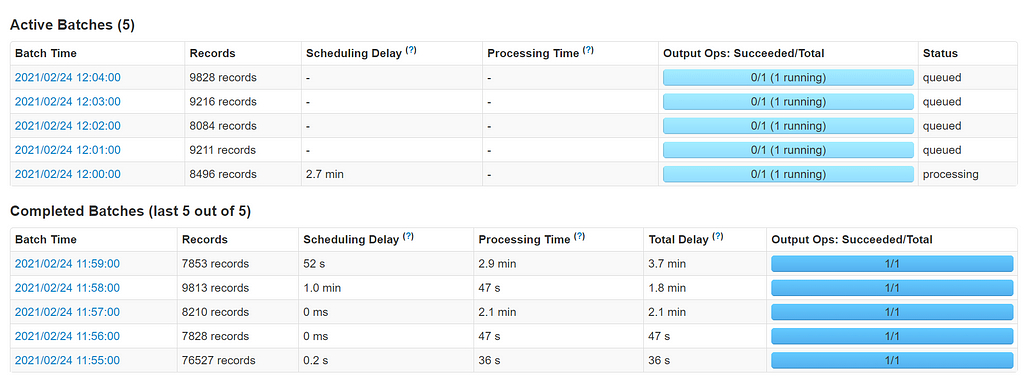 Micro Batch Processing in Spark Streaming
Micro Batch Processing in Spark StreamingStructured Streaming, on the other hand, is a higher-level API that uses the Spark SQL engine to process structured streaming data. It treats streaming data as a continuous table and uses SQL-like queries to analyze and transform the data. Structured Streaming supports a wide range of input sources, including Kafka, Flume, and file systems, and can handle both structured and semi-structured data.Structured Streaming also supports more advanced features such as event-time processing and watermarking, which are not available in Spark Streaming.
The choice between Spark Streaming and Structured Streaming depends on the specific use case and requirements of the application. If low latency processing is critical, Spark Streaming may be the better choice. If the focus is on ease of use and advanced features, then Structured Streaming may be a better fit.
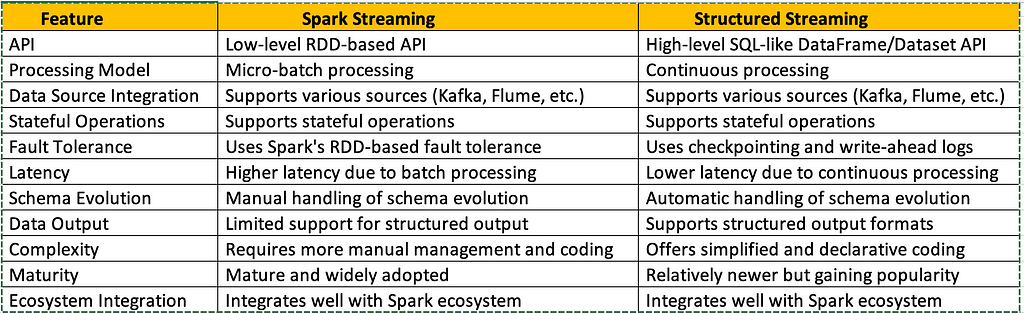 Features comparison between Spark vs Structured Streaming
Features comparison between Spark vs Structured StreamingAdvantages of Structured Streaming Over Spark Streaming:
1.RDD vs Dataframe vs Dataset
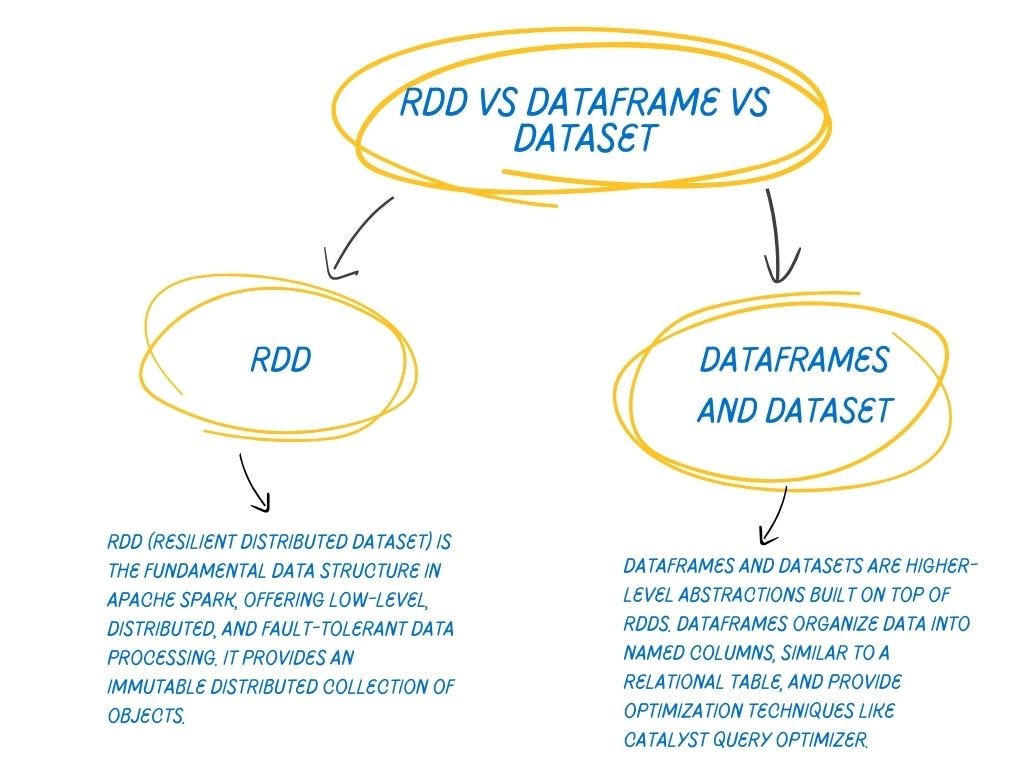 RDD vs Dataframe vs Dataset
RDD vs Dataframe vs DatasetWhile RDDs offer more flexibility and control, DataFrames and Datasets provide a more optimized and user-friendly API for structured data processing. They enable Spark to perform advanced optimizations and leverage external data sources effectively.
So it is a straight comparison between using RDDs or DataFrames. As far as performance and ease of use are concerned, DataFrames are more optimized in terms of processing and provides more options of aggregations and other operations with a variety of functions available
2. Processing with Event Time and Handling Late Data
One great issue in the streaming world is to process data according to the event-time. Event-time is the time when the event actually happened. It is not necessary that the source of the streaming engine is providing data in exactly real time. There may be latencies in data generation and handing over the data to the processing engine. There is no such option in Spark Streaming to work on the data using the event-time. It only works with the timestamp when the data is received by the Spark. Based on the ingestion timestamp the Spark streaming put the data in a batch even if the event is generated early and belonged to the earlier batch which may result in less accurate information as it is equal to the data loss. On the other hand, Structured streaming provides the functionality to process the data on the basis of event-time when the timestamp of the event is included in the data received.
3. End to End Semantics:
 Semantics of Spark and Structured Streaming
Semantics of Spark and Structured StreamingEvery application requires one thing with utmost priority which is: Fault tolerance and End to End guarantee of delivering the data. Whenever the application fails it must be able to restart from the same point when it failed to avoid data loss and duplication. To provide fault tolerance Structured streaming use the checkpointing to save the progress of a job.
 Spark vs Structured Streaming Advantages
Spark vs Structured Streaming AdvantagesStructured Streaming with Kafka:
To use Structured Streaming with Kafka, developers can leverage the Kafka source that is built into Spark, which provides a fault-tolerant and scalable way to read data from Kafka topics. The Kafka source is integrated with Spark’s Structured Streaming API, allowing developers to easily define streaming queries on Kafka data using the DataFrame API.
To read data from Kafka, developers can use the <strong>readStream</strong> method on a <strong>SparkSession</strong> object and specify the Kafka source along with the Kafka broker details and the topic to read data from. Once the data is read into a DataFrame, developers can apply transformations and aggregations on the data using Spark’s DataFrame API.
For example, the following code snippet shows how to read data from Kafka and perform a word count on the streaming data:
spark = SparkSession.builder <br /> .appName(“KafkaStructuredStreaming”) <br /> .getOrCreate()
kafka_df = spark <br /> .readStream <br /> .format(“kafka”) <br /> .option(“kafka.bootstrap.servers”, “localhost:9092”) <br /> .option(“subscribe”, “mytopic”) <br /> .load()
wordCounts = kafka_df <br /> .selectExpr(“CAST(value AS STRING)”) <br /> .groupBy(“value”) <br /> .count()
query = wordCounts <br /> .writeStream <br /> .outputMode(“complete”) <br /> .format(“console”) <br /> .start()
query.awaitTermination()
In this example, the code reads data from the Kafka topic “mytopic” and performs a word count on the streaming data. The resulting word counts are written to the console in the output mode “complete”. The awaitTermination method is called to start the streaming query and wait for it to terminate.
Spark Shell commands
Initiate the shell :
spark-shell — packages org.apache.spark:spark-sql-kafka-0–10_2.11:2.3.0
Read Topic :
var test=spark.readStream.format(“kafka”).option(“kafka.bootstrap.servers”,”<Kafka_Brokers>”).option(“subscribe”,”<topic>”).load.select($”value”.cast(“string”).alias(“value”))
To see output in console:
test.writeStream.format(“console”).outputMode(“append”).start().awaitTermination()
To write to HDFS:
val result=test.writeStream.format(“json”).outputMode(“append”).option(“checkpointLocation”,”<Checkpoint location>”).option(“path”,”<Target Path>”).start()
Fault Tolerance:
Structured Streaming is designed to be fault-tolerant, which means that it can recover from failures and continue processing data without losing any data.
In Structured Streaming, fault tolerance is achieved through checkpointing. Checkpointing is the process of periodically saving the state of the processing application to a fault-tolerant storage system, such as HDFS. If the application fails, it can recover its state from the checkpoint and continue processing from where it left off.
Checkpointing:
Checkpointing is a crucial feature in Spark Structured Streaming that enables fault tolerance and ensures exactly-once semantics. It involves periodically saving the state of a streaming query to a reliable storage system, such as HDFS.
During query execution, Spark Structured Streaming continuously stores the query’s metadata and the processed data’s schema and state. If a failure occurs, the system can use the checkpointed state to recover the query and resume processing from where it left off, without reprocessing the data that was already processed. This ensures that the application processes each record exactly once, even in the presence of failures.
Checkpointing is especially important in long-running queries or queries that use stateful operations. Without checkpointing, a failure could result in the loss of the query’s state, forcing the system to restart the query from the beginning, which would lead to processing duplicate data and potentially corrupt the query’s results.
Checkpoints directory contains 4 subdirectory.
- Metadata
- Sources
- offsets
- commits
Metadata:
Metadata holds the run id of spark application this id will not change , no matter how many times you restart your application this id will se same.
i.e. {“id”:”778eb7c2-c427–4395-bf99–15b1a43d1b70"}
Source :
Source folder contains the Initial Kafka offset values of each partition. like if your Kafka has 3 partitions 1,2,3 and starting values for each partition is 0 then it will contain value like {applicationname {1:0,2:0,3:0} }
Offsets:
Offsets contains the end offset value details for each partitions in a batch.
commits :
A log that records the batch ids that have completed. This is used to check if a batch was fully processed, and its output was committed to the sink, hence no need to process it again.
Checkpoint Location/
└── commits/
└── metadata/
└── offsets/
└── sources/
 Checkpoint Directory Structure
Checkpoint Directory StructureEach micro batch is similar as one transaction.
- When kafka source have new messages. The begin and end offsets for the micro-batch will be written to offsets folder.
- Start processing.
- If succeed, commit file will be writen into commits folder with same microbath id. If failed, will re-execute micro batch using the same offsets range.
Offset Management:
In Spark Structured Streaming, offset management is handled automatically by the underlying Kafka source.
When a structured streaming query is started, it reads data from Kafka starting from the latest offset by default. The query maintains an internal record of the current offset for each partition it reads from, and this information is used to continue reading from where it left off in the event of a failure or restart.
Spark Structured Streaming also provides the option to specify a starting offset for each partition explicitly. This can be useful when the application needs to process only a subset of the data in a Kafka topic or to rerun a query from a specific point in time.
During query execution, Spark Structured Streaming continuously stores the processed offset information to a checkpoint location. This checkpointed offset information is used to recover the query and resume processing from where it left off in the event of a failure or restart.
In Spark, you can read data from Kafka with a specific starting offset using the option() method. Here’s an example of how to do it:
spark = SparkSession.builder.appName(“KafkaOffsetReader”).getOrCreate()
df = spark <br /> .readStream <br /> .format(“kafka”) <br /> .option(“kafka.bootstrap.servers”, “localhost:9092”) <br /> .option(“subscribe”, “my-topic”) <br /> .option(“startingOffsets”, “earliest”) <br /> .load()
df.printSchema()
In this example, the startingOffsets option is set to earliest, which means the query will start reading data from the beginning of the Kafka topic. You can also set it to a specific offset value, such as latest or a specific offset number.
Note that once you have specified the starting offset, the Spark Structured Streaming query will continue reading from that offset until it is stopped or until the query is restarted with a different starting offset.
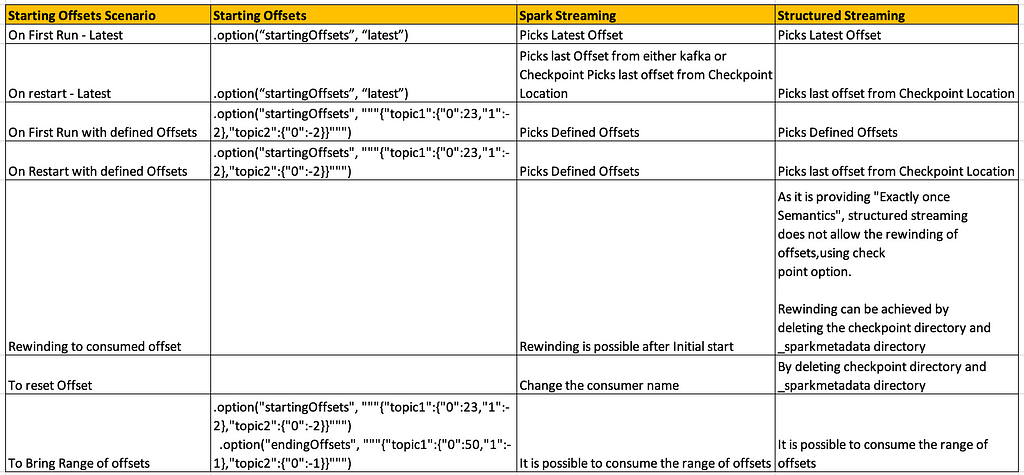 Offset Management — Spark vs Structured Streaming
Offset Management — Spark vs Structured StreamingRewinding Offsets in Structured Streaming:
In Spark Structured Streaming, it is not possible to rewind offsets while writing a streaming query to a sink.
The offset management for a streaming query is handled by the underlying source, such as Kafka, and the query reads data from the source starting from the last committed offset. The offset information is stored in a checkpoint location, which is used to recover the query in the event of a failure or restart.
If you need to process data from an earlier offset in Kafka, you can create a new streaming query with an earlier starting offset and write the output to a separate sink or we need to delete the checkpoint directory and _sparkmetadata directory. However, this would result in the duplication of data that was already processed by the earlier query.
We can use below method to drop the directories using Filesystem Package
import org.apache.hadoop.fs.{FileSystem, Path}
def clearSSCache(configurator: ConfigReader)(
implicit fileSystem: FileSystem): Unit = {
// Clearing the checkpoint locations
FileSystemUtil.dropDirRecursive(configurator.CHECKPOINT_LOCATION)
// Clearing the _spark_metadata path
FileSystemUtil.dropDirRecursive(
configurator.INGESTION_PATH + GlobalVar.SPARK_METADATA_DIR)
}It is important to note that Spark Structured Streaming is designed to provide exactly-once semantics, which means that each record is processed exactly once, even in the presence of failures. Rewinding offsets and reprocessing data that was already processed goes against this principle and can potentially lead to inconsistent results.
Conclusion
The combination of Spark Structured Streaming and Kafka also provides a range of features, such as automatic offset management, checkpointing, and windowing, that allow developers to build complex stream processing pipelines with high reliability and performance.
However, as with any technology, there are trade-offs to consider when using Spark Structured Streaming with Kafka. For example, the overhead of maintaining the structured streaming query and managing the checkpointing process can affect the performance of the application, and the SQL-like API may not be suitable for all use cases.
Overall, Spark Structured Streaming with Kafka is a powerful tool for building real-time data processing applications, and it is important for developers to carefully consider their requirements and use case when deciding whether to use this technology.
Author:
Eswaramoorthy P — Data Engineer III
References:
- Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher)
- Spark: RDD vs DataFrames
https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/
- Streaming with File Sink: Problems with recovery if you change checkpoint or output directories
- How to recover from a deleted _spark_metadata folder in Spark Structured Streaming
Building Scalable Data Pipelines with Kafka, Structured Streaming and Spark was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.