
Data lakes have become an essential part of data management in today’s organisations. They provide a centralised repository that can store structured and unstructured data at any scale. However, managing data lakes can be a challenging task, especially for beginners. Apache Hudi is an open-source data lake management tool that can help simplify this process.
Apache Hudi is like a big box where you can put all your toys, but instead of toys, it’s data. And it helps you keep your data organised so you can find the toy you want easily. It also helps you to keep adding new toys to the box without making a mess, and if you don’t like how your box looks, you can undo the changes and make it look the way it did before.
For example, let’s say the toy robot is exploring a park and it sends information to the computer every time it finds a new flower. Hudi will take all the information the toy robot sends and organize it by the type of flower, the color, and the location it was found. So, when you want to know about all the yellow flowers the robot found in the park, you can easily find that information in the toy box because of the way Hudi organized it.
In this beginner’s guide, we will go over the basics of Apache Hudi and how it can be used to manage data lakes.
What is Apache Hudi?
Apache Hudi (short for Hadoop Upserts and Incrementals) is a tool that allows for easy management of data lakes. It provides a unified approach to storing, managing, and querying data in data lakes. Hudi supports both batch and streaming data and enables incremental updates, rollbacks, and point-in-time queries.
Why use Apache Hudi?
Apache Hudi simplifies data lake management by providing a consistent way to store and query data. It also allows for incremental updates, which means that you can add new data to your data lake without having to completely rewrite the entire dataset. This can save a significant amount of time and resources.
Additionally, Hudi supports rollbacks, which means that you can undo changes made to your data lake if necessary. This can be useful in case of data errors or if you need to restore a previous version of your data lake.
How to use Apache Hudi?
Using Apache Hudi is relatively straightforward. The first step is to install Hudi on your Hadoop cluster. This can be done using the Hadoop package manager, or by downloading the source code and building it yourself.
Once you have Hudi installed, you can start creating tables in your data lake. Hudi supports several different table types, including:
- Hive-managed tables
Hive-managed tables are tables in Apache Hudi that are managed by the Hive data warehousing system. These tables are stored in the same format as traditional Hive tables and can be queried using HiveQL (Hive’s query language). This means that if you are already familiar with Hive, you can easily start using Hive-managed tables in Apache Hudi without having to learn a new query language. Additionally, Hive-managed tables are also compatible with other tools and systems that use Hive, making it easy to integrate Hudi with your existing data infrastructure.
- External tables
External tables in Apache Hudi are tables that are not managed by Hudi itself. Instead, the data for these tables are stored in an external location, such as an object store or a data lake. The metadata for the table is stored in Hudi, and Hudi provides an API to query the data. This allows you to continue using your existing data storage systems and tools while still taking advantage of Hudi’s features, such as incremental updates and rollbacks.
One of the main advantages of using external tables is that it allows you to keep the original data files in their native format, without having to convert them to a specific format. This can be useful if you have a large amount of data that is already stored in a particular format, and you don’t want to have to convert it. Additionally, external tables can also help to reduce storage costs by avoiding the need to duplicate data.
- Dataset-based tables
Dataset-based tables in Apache Hudi are a type of table that is based on the concept of datasets. A dataset is a collection of data that is stored in a specific format, such as Avro or Parquet. Datasets can be queried using the Hudi read API and can be updated using the Hudi write API.
Dataset-based tables provide a more flexible way of storing and querying data in Apache Hudi as they can support different storage formats, indexing, and partitioning options. It also allows you to store your data in a format that is optimized for your specific use case.
You can then load data into your tables using the Hudi write API. The write API supports several different data formats, including Avro, Parquet, and JSON.
Once your data is loaded, you can start querying it using the Hudi read API. The read API supports several different query types, including:
- Full table scans
- Incremental queries
- Point-in-time queries
Hudi also provides a command-line interface that can be used to manage and query your data lake.
Sample Design of Data Pipeline using Hudi, Kafka, and GCP:
A data pipeline using Apache Kafka, Apache Hudi, and Google Cloud Platform (GCP) can be designed as follows:
- Data is generated by various sources and sent to a Kafka topic as a stream of records.
- A Kafka Consumer reads the stream of records from the topic and sends it to a GCP Cloud Dataflow job.
- The Cloud Dataflow job processes the data and performs any necessary transformations and writes the data to a GCS bucket or BigQuery dataset.
- Apache Hudi is configured to use the GCS bucket or BigQuery dataset as the storage location for the data lake.
- Hudi provides data management features such as data versioning, data compaction, and data querying on top of the data stored in the GCS bucket or BigQuery dataset.
- Data processing can be done using GCP services such as Cloud Dataproc, Apache Spark, or Apache Hive on Dataproc. Hudi can integrate with these services and provide features such as Incremental data reads, Snapshot-based data reads, and Upserts.
- The processed data can be stored in a GCS bucket or BigQuery dataset or any other storage system like Cloud Storage, or Bigtable.
- Data can be visualized using GCP services like BigQuery, Data Studio, or Data Studio.
Overall, this pipeline allows you to stream data in real time, process it using Cloud Dataflow, and manage it using Hudi on GCP storage. Additionally, Hudi’s data management features can improve the performance of data processing and query, making it easy to work with large data lakes on GCP.
Apache Hudi (Hoodie) provides support for querying data stored in the data lake using a few different query languages. The most commonly used query languages are:
- SQL: Hudi provides support for querying data stored in the data lake using SQL queries. This allows users to query the data using a familiar SQL syntax, and it also allows for easy integration with other SQL-based tools and frameworks.
- HiveQL: Hudi supports querying data stored in the data lake using HiveQL (Hive Query Language). This allows users to query the data using a familiar Hive syntax, and it also allows for easy integration with Hive and other Hive-based tools and frameworks.
- Java API: Hudi provides a Java API for querying data stored in the data lake. This allows developers to write Java code to query the data, and it also allows for easy integration with other Java-based tools and frameworks.
- Spark SQL: Hudi provides support for querying data stored in the data lake using Spark SQL. This allows users to query the data using a familiar SQL syntax, and it also allows for easy integration with Spark and other Spark-based tools and frameworks.
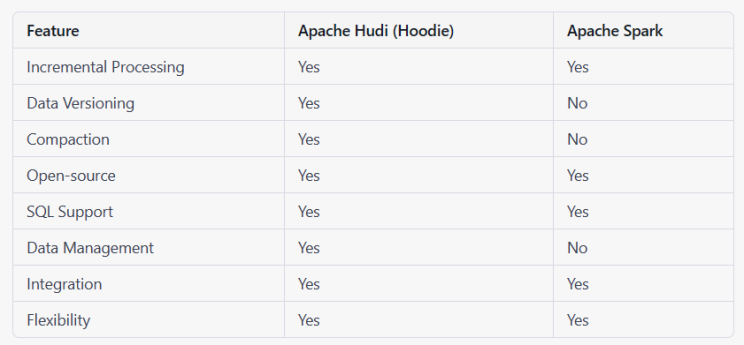
A comparison of Apache Hudi and Apache Spark:
Conclusion
Apache Hudi is a powerful tool that can simplify the process of managing data lakes. It provides a consistent way to store and query data and allows for incremental updates and rollbacks. By following this beginner’s guide, you can start using Hudi to manage your data lake with ease.
More References: Apache Hudi vs Delta Lake vs Apache Iceberg — Lakehouse Feature Comparison (onehouse.ai)
Thank you for reading the blog on Hudi. I hope that this information was helpful and will help you keep your data streams running smoothly. If you found this blog useful, please share it with your colleagues and friends. Until next time, keep streaming!
A beginner’s guide to using Apache Hudi for data lake management. was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: A beginner’s guide to using Apache Hudi for data lake management. | by Kuldeep Pal | Walmart Global Tech Blog | Medium