 Photo Credit: Pixabay
Photo Credit: Pixabay
Introduction
Any time a user searches and autocomplete matches their query, the system is comparing an input query against a set of keywords. For example, we could match the input query “flights” against the set {“flights from SFO to LAX”, “flights to XNA”, “flights guide”, “guide”}.
 An example of string searching
An example of string searchingSuppose that the search history is large. How can this operation be optimized to autocomplete as quickly as possible? How do we optimize the engineering resources dedicated to building this operation?
Methodologies
There are several different approaches which can be used to implement this type of matching. This article compares naive brute force comparison, a trie-based approach, and the Aho-Corasick string matching approach [1]. These were selected because Aho-Corasick builds off the trie-based approach; other string-matching techniques such as Knuth-Morris-Pratt, Boyer-Moore, etc. are relevant with respect to this topic, but are out of scope for this article as they represent more niche use cases.
Reference Key
The below table provides explanations for variables which will be referenced subsequently in the article.

- n: length of the input query
- m: trie height (max keyword length)
- k: cardinality of the keyword set
- z: expected number of matches discovered for a given search operation (match density)
Methodology 1: Naive Brute Force Comparison
In the browser example, the naive approach is similar to manually comparing each item in the search history against the user’s query. This is equivalent to using query.contains(keyword) in Java for every keyword in the set. Asymptotically speaking, this would be O(nk) where n is the
length of the input query, and k is the cardinality of the keyword set. This assumes an O(n) implementation of the substring comparison operation.
One benefit of this approach is that regardless of whether the keyword set is stored offline or provided at search time, it has the same asymptotic complexity.
This reduces implementation time significantly, which may be applicable for a small search space if there’s a limited number of patterns (for example, checking for question words like “who” or “what” within queries).
One significant drawback of this implementation is that runtime increases linearly with k. If k is large, it will perform poorly.
Methodology 2: Build a prefix trie with the keyword set
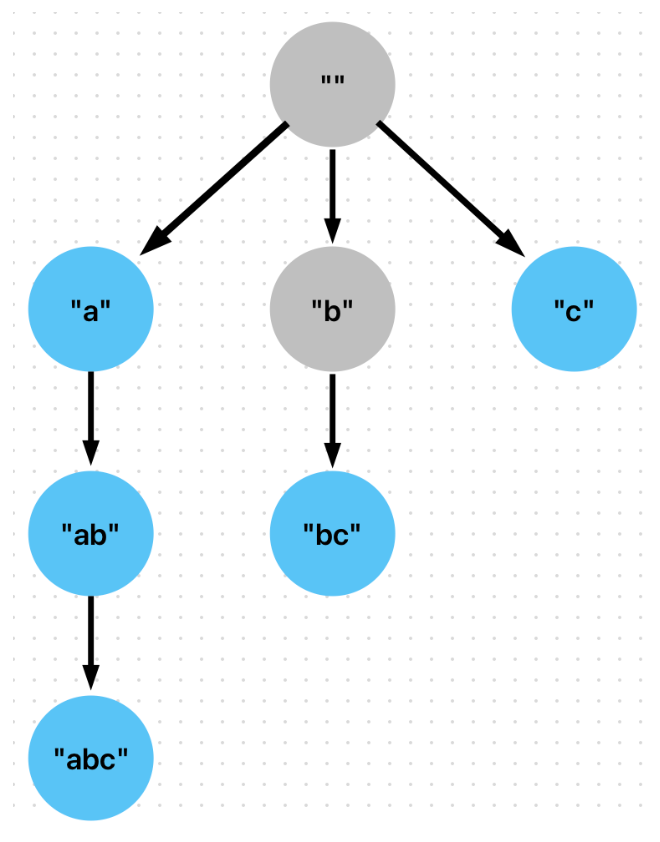
If we know the keyword set in advance, we can preprocess it into a trie which allows us to match against the search query in less time, asymptotically speaking. This is like having the search history known in advance in the browser example.
The following approach will build a prefix trie on the set of keywords. For background, a trie is a tree-based data structure which represents sequences of an alphabet of characters. Shown above is a prefix trie. Note that each edge appends an additional character to the parent node
(the prefix). Also, for each parent node, there is at most one edge for each character in the alphabet. Paths to leaf nodes form strings consisting of letters of the alphabet.
This allows us to reduce the number of comparisons. For example, in one pass over the trie, we can determine that the input query contains “abc”, “ab”, “a”. In the prior implementation, we would need to call .contains for each of these, so it would be three passes.
Asymptotically speaking, this would be O(nmin(n,m)+z) where n is the length of the input query, m is the height of the trie (i.e., the length of the longest keyword), and z is the number of matches collected (which is no larger than k).
One noticeable improvement the trie makes over the naive approach is replacing k with z. This means that search time is no longer bound by the size of the keyword set, but by the number of matches. In the case when matches are sparse (in other words, z << k) and k is sufficiently large,
the trie will outperform the naive approach. If matches are extremely sparse (z = log k), then the trie greatly outperforms the naive approach.
Below is shown a diagram of complexities for methodologies 1 and 2. Since the naive approach’s runtime does not change with respect to match density, only variation of the trie’s match density is shown.
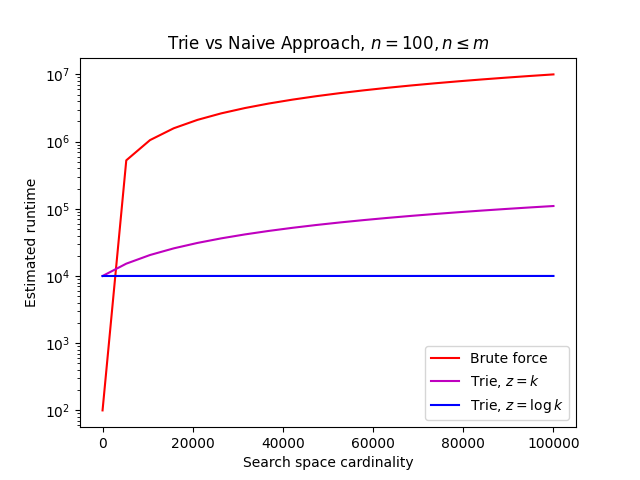
Even with maximum match density, the trie appears to perform better than the naive approach because the k factor in the equation for the naive approach is multiplied by n (whereas in the trie, z is not multiplied by any other variables, excluding implicit constant factors which are not
shown).
However, the trie approach still leaves room for improvement. To understand why, consider the example provided above. A trie will give us matches of “abc”, “ab”, and “a” in a single pass. Note that these form prefixes of the input query “abc”. However, in order to detect matches of
“bc” and “c”, we would need to iterate over the proper suffixes of the input query (which are also “bc” and “c”) and search the trie with each of them.
We know that a match of “abc” also implies matches of “bc” and “c”, so additional improvement is possible.
Side Note: Tokenization
The trie examples provided in this article tokenize strings on characters, but a larger unit could be used (such as words delimited by spaces). Decreasing the size of tokens can reduce the net number of character comparisons performed. If tokens are too granular and the trie edges are
implemented as pointers, this could perform poorly due to excessive pointer jumping. This article assumes character-level tokenization for simplicity.
Methodology 3: Build an Aho-Corasick automaton with the keywords
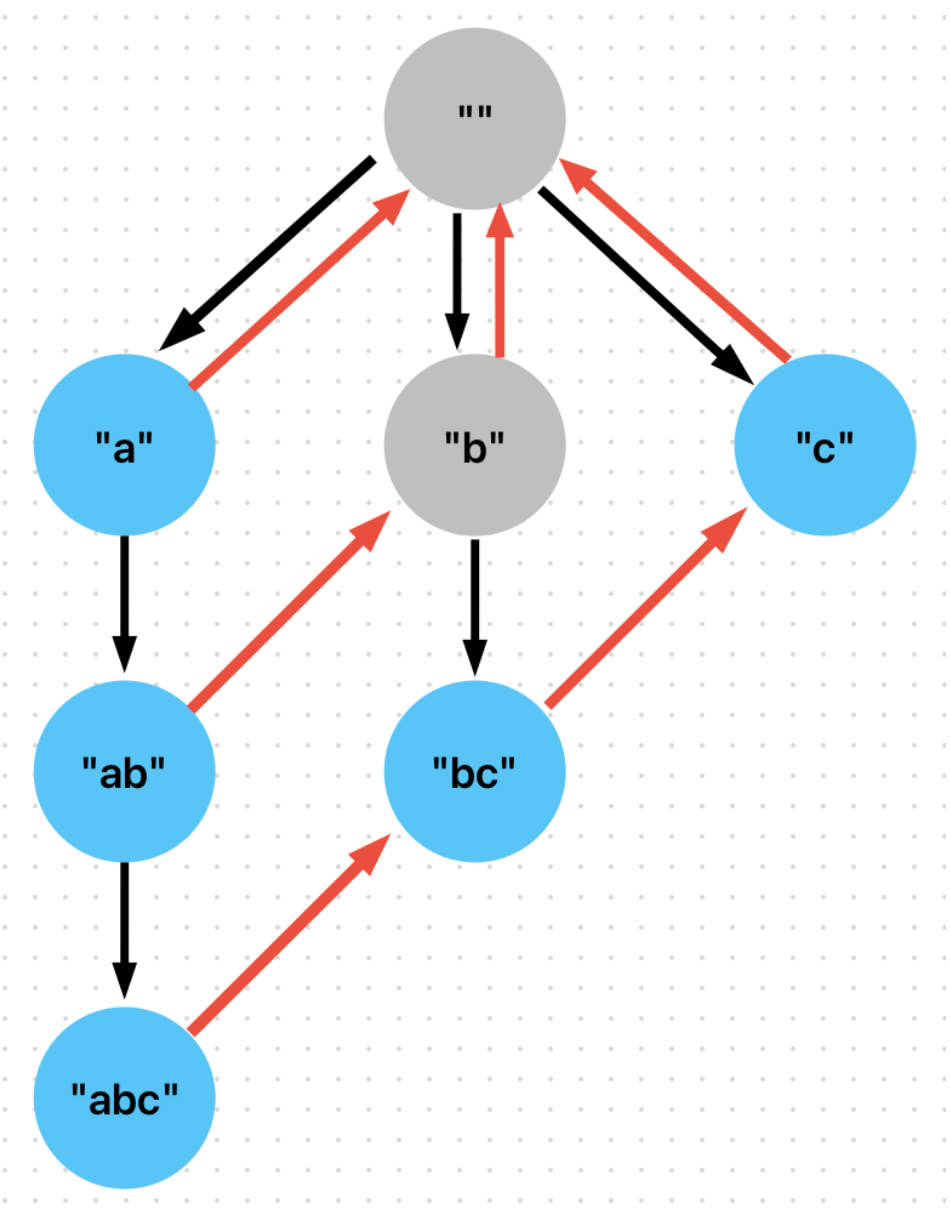
At a high level, an Aho-Corasick automaton is similar to a trie with back edges. Here is an example of how searching would work, utilizing the above diagram:
- We receive an input query “abd”.
- We first start with the character “a” and follow the edge from node “” (root) to node “a”.
- We then follow the edge from node “a” to node “ab” (this current position in the trie is associated with the position of “b” in the input query).
- After this, we will not find a child corresponding with the character “d” (the next character in the query) at node “ab”. So, we will follow the red failure edge (corresponding with the longest proper suffix of “ab” that is present in the trie, namely
node “b”). - We then see that node “b” does not have a child associated with the character “d”, so we follow the failure edge again to the root.
- Again, there is no child for the character “d” at the root node, so we continue to the next character in the input query.
- Since “d” is the last character, the search is done and we have visited the nodes “”, “a”, “ab”, “b”, and “” in that order, collecting matches for both “a” and “ab” (“b” and “” are not in the keyword set).
Another aspect of the Aho-Corasick approach: it will collect the implied matches at a given node. For example, the node corresponding with “abc” will contain references to the implied matches of “bc” and “c” (and the explicit match of “abc”).
These implied matches can be precomputed offline by iteratively following the failure (red) edges until we get to the root, collecting the matches from every step. This is done for each node in the automaton. The benefit of doing this offline is that we do not need to repeatedly follow failure edges when searching.
This approach has a complexity of O(n+z) where n is the length of the input query and z is the number of matches. This assumes that the automaton is built offline; this upper bound corresponds with search time only and does not consider offline build time.
This means that if n is in Ω(z), search time is in O(n).
Below is a diagram comparing Aho-Corasick against the trie approach.
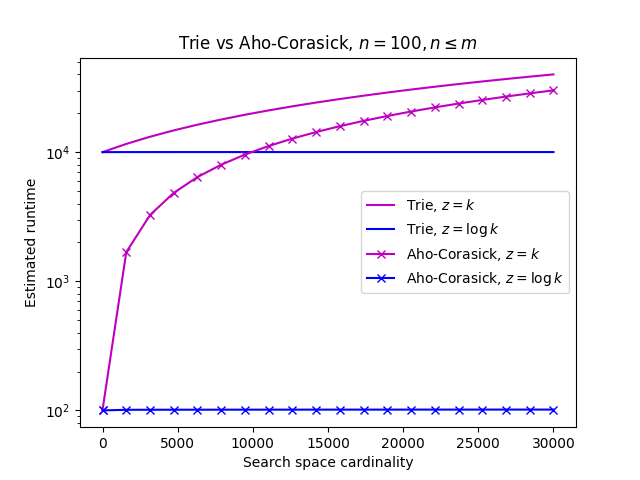
Given a sufficiently large z and a fixed query size, we see that Aho-Corasick’s improvement over the trie becomes less significant.
We see that given the assumptions n = 100 and n<=m, Aho-Corasick outperforms the trie in speed of searching the same data set (the same data set implies the same match density). The improvement achieved over the trie approach is only a factor of n when the z term does not dominate the n term. In other words, Aho-Corasick’s improvement over the trie is only substantial when n is in Ω(z).
Suppose n = z, so the trie’s runtime would be in O(zmin(m,z)). Given the same assumptions, Aho-Corasick would have a runtime of O(z) and the naive approach would run in O(kz) time. The speedup achieved by Aho-Corasick over the trie approach depends on the distribution of keyword lengths which is reflected in the m term.
Which approach to choose?
We have covered three different string subset matching techniques. Below is shown a recap of the above complexity analysis. The characteristics of the use case determine which approach is appropriate.
If k is small, then the naive approach is likely sufficient. In other words, in the case when we’re only looking for a small number of substrings in the customer’s input query. A good example of this is a feature with a small number of cases, such as searching all incoming queries for question words such as “who”, “what”, etc. At Walmart, we might use this approach to do query classification to perform different request logic.
If the keyword set is large, the prefix trie approach will prevent runtime from increasing linearly with its size. For example, if we have a large set of grocery items and want to figure out which product names are contained in an input query, the trie approach would be a simple improvement over the naive approach. The trie approach can also be implemented in a relatively short time, which is valuable if engineering bandwidth is limited. If queries are short, then the trie performs well enough.
The final approach is more complicated to implement with respect to the trie, approximately 5-10x the implementation effort. It’s reserved for the niche case where not only is the keyword set large, but the query is also large. In this niche case, Aho-Corasick could be useful for the business case where a chatbot is processing long text prompts, or a web crawler is processing large pages. Because this algorithm finds results more quickly, it will use less computing resources, resulting in lower latency and faster results for customers.
Conclusion
This article has described three different techniques for detecting a set of keyword substrings in an input query. Each technique has its own tradeoffs, the choice of which depends on the use case. Given a sufficiently large keyword set and match sparsity, a trie or Aho-Corasick automaton could provide better performance than the brute force approach.

[1] Communications of the ACM, vol. 18, no. 6, June 1975, pp. 333–340,
https://doi.org/10.1145/360825.360855.
Which String Searching Technique is Best? A Comparison was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Which String Searching Technique is Best? A Comparison | by Nick Emerson | Walmart Global Tech Blog | May, 2024 | Medium