Authors: Vilas Athavale, Ravinder Matte, Sid Anand, Shrity Verma, Naresh Gopalani, Bhaven Avalani
Summary
Walmart deploys Apache Kafka, with 25K+ Kafka consumers, across multiple clouds (public and private). Supporting business critical use cases including data movement, event driven microservices and streaming analytics. These use-cases demand 4 nines (i.e., 99.99) of availability and require us to quickly drain any backlogs arising from sudden traffic spikes. At Walmart scale, we have a diverse set of Kafka consumer applications written in multiple languages. This diversity combined with our reliability requirements require consumer applications to adopt best practices to ensure high availability SLOs. High consumer lag due to Kafka consumer rebalancing is the most common challenge in operationalizing Kafka consumers at scale. In this article we highlight how Apache Kafka messages are reliably processed at a scale of trillions of messages per day with low cost and elasticity.
Challenges
Consumer rebalancing
A frequent problem encountered in production deployments of Kafka had to do with consumer rebalancing. Kafka rebalancing is the process by which Kafka redistributes partitions across consumers to ensure that each consumer is processing a roughly equal number of partitions. This ensures that data processing is distributed evenly across consumers and that each consumer is processing data as efficiently as possible. Kafka applications run either on containers or on VMs (a.k.a. Virtual Machines). For this article’s purposes, we focus on containers as that is prevalent in industry today. Kafka consumer applications built as container images run on WCNP (Walmart Cloud Native Platform) — an enterprise-grade, multi-cloud, container orchestration framework built on top of Kubernetes. Consumer rebalancing can thus be triggered by multiple causes, including:
- A consumer pod leaving a consumer group: This can be caused by K8s deployments or rolling-restarts or automatic/manual scale-ins
- A consumer pod entering a consumer group: This can be caused by K8s deployments or rolling-restarts or automatic/manual scale-outs
- The Kafka broker believing that a consumer has failed (e.g., if the broker has not received a heartbeat from a consumer within session.timeout.ms ): This will be triggered if the JVM exits or has a long stop-the-world garbage collection pause
- The Kafka broker believing a consumer is stuck (e.g., if the consumer takes longer than max.poll.interval.ms to poll for the next batch of records to consume): This will be triggered if processing of the previously polled records exceeds this interval
While consumer rebalancing achieves resiliency in the face of both planned maintenance (e.g., code releases), standard operational practices (e.g., manually changing min pods / max pods settings), and automatic self-healing (e.g., pod crashes, autoscaling), it negatively impacts latency. Given the near real-time nature of commerce today, many Kafka use-cases have tight delivery SLAs — these applications suffered from constant lag alarms due to frequent and unpredictable rebalances in production.
There is no clean way to configure consumers to avoid rebalancing in Kafka today. Although the community provides static consumer membership and co-operative incremental rebalancing, these approaches come with their own challenges.
Poison pill
Head-of-line (HOL) blocking is a performance-limiting phenomenon that can occur in networking and messaging systems. It happens if a Kafka consumer encounters a message that will never successfully be processed. If message processing results in an uncaught exception thrown to the Kafka consumer thread, the consumer will re-consume the same message batch on the next poll of the broker — predictably, the same batch containing the “poison pill” message will result in the same exception. This loop will continue indefinitely until a code fix is deployed to the Kafka consumer application skipping the problematic message or correctly processing it or the problematic message is skipped by changing consumer offset. This poison-pill problem is yet another problem associated with in-order processing of partitioned data streams. Apache Kafka does not handle poison pill messages automatically.
Cost
There is strong coupling between the partitions in a topic and the consumer threads that read from them. The maximum number of consumers of a topic cannot exceed the number of partitions in that topic. If consumers are unable to keep up (i.e., maintain consistently low consumer lag) with topic flow, adding more consumers will only help until all partitions are assigned to a dedicated consumer thread. At this point, the number of partitions will need to be increased to increase the max number of consumers. While this might sound like a fine idea, there are general rules on the numbers of partitions you can add to a broker before needing to vertically scale the broker nodes up to the next biggest size (4000 partitions / broker)). As you can see, a problem with increasing consumer lag results in increasing partitions and potentially also scaling to larger brokers, even though the broker itself may have ample physical resources (e.g., memory, CPU, and storage). This strong coupling between partitions and consumers has long been the bane of many engineers who seek to maintain low latency in the face of increasing traffic in Kafka.
Kafka partition scalability
When there are thousands of pipelines, increasing the number of partitions becomes operationally onerous as it requires coordination among producers, consumers, and platform teams and imposes a small window of downtime. Sudden traffic spikes and large backlog draining both require increases in partitions and consumer pods.
Solution
To remedy some of the challenges above (e.g., the Kafka Consumer Rebalancing), the Kafka community has proposed the following Kafka Improvement Proposal: KIP-932: Queues for Kafka.
The Messaging Proxy Service (MPS) is a different path that is available. MPS decouples Kafka consumption from the constraint of partitions by proxying messages over HTTP to REST endpoints behind which consumers now wait. Via the MPS approach, Kafka consumption no longer suffers from rebalancing, while also allowing for greater throughput with a lower number of partitions.
An added benefit of the MPS approach is that application teams no longer must use Kafka consumer clients. This frees any Kafka team from having to chase application teams to upgrade Kafka client libraries.
Design
The MPS Kafka consumer consists of two independent thread groups: the Kafka message_reader thread (i.e., a group of 1 thread) and message_processing_writer threads. These thread groups are separated by a standard buffering pattern (pendingQueue). The reader thread writes to a bounded buffer (during the poll) and writer threads read from this buffer.
A bounded buffer also provides control on the speed of reader and writer threads. The message_reader thread will pause the consumer when the pendingQueue reaches a max buffer size.
This separation of reader and writer threads makes the reader thread incredibly lightweight and does not trigger a rebalance operation by exceeding max.poll.interval.ms. Now, the writer threads can take the time needed to process messages. The following diagram provides a pictorial view of the components and design.
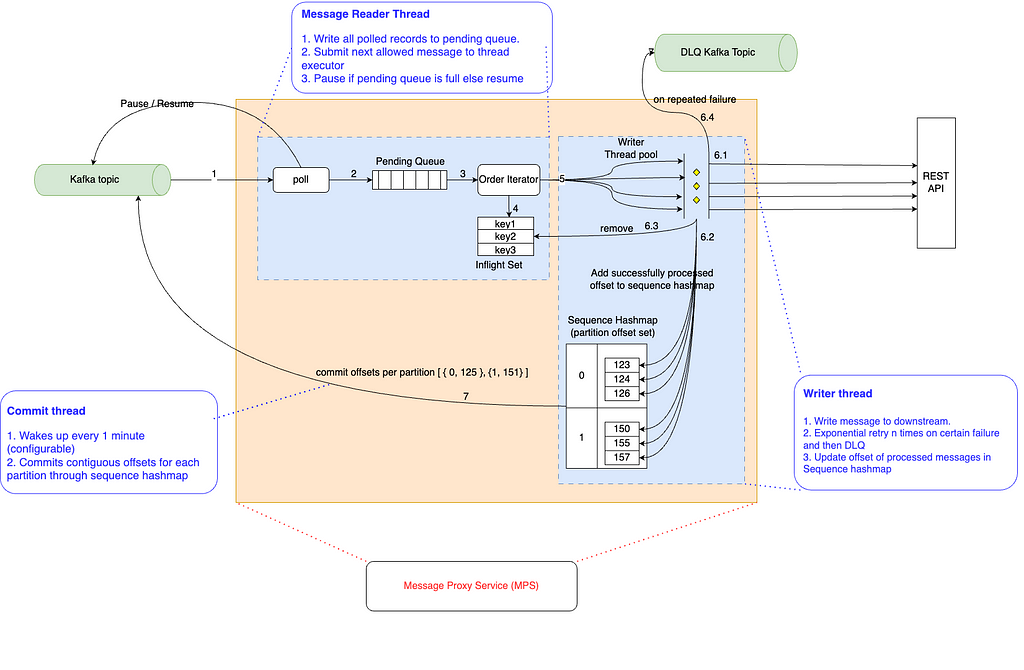 Pictorial view of the components and design.
Pictorial view of the components and design.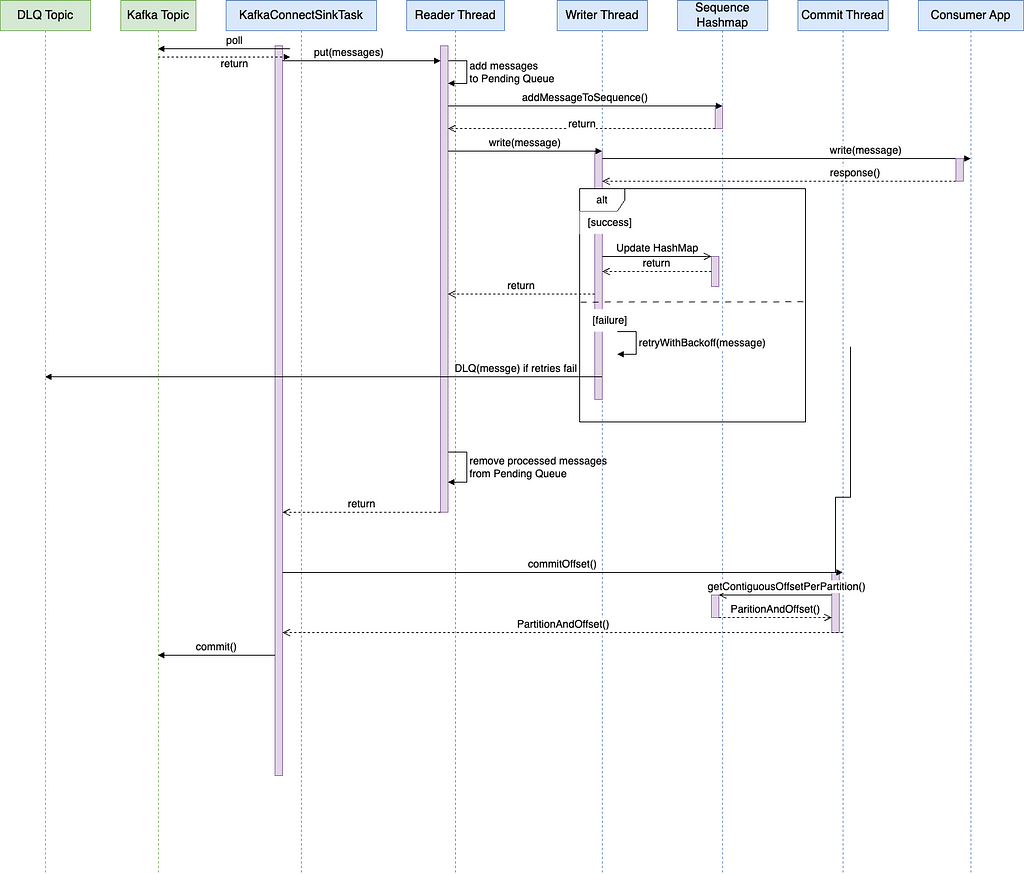 Sequence diagram models the interaction between the components as a sequence of calls.
Sequence diagram models the interaction between the components as a sequence of calls.The architecture above is composed of the following key components:
Reader Thread
The reader thread’s job is to make progress through the inbound topics, applying back-pressure when the PendingQueue is full.
Order Iterator
The order-iterator guarantees that keyed messages are processed in order. It iterates through all messages in pendingQueue and leaves the messages (i.e., temporarily skips) if there is already a message with the same key in flight. Skipped messages will be processed in subsequent poll calls once earlier messages with the same key are processed. By ensuring that no more than 1 message per key is in flight, MPS guarantees in-order delivery by key.
Writer Thread
The writer thread is part of a pool that provides greater throughput via parallelism. It’s job is to reliably write data to REST endpoints and DLQ’ing messages if either retries are exhausted or non retry-able HTTP response codes are received.
Dead Letter Queue (DLQ)
A DLQ topic can be created in every Kafka cluster. The message_processing_writer thread initially retries messages a fixed number of times with exponential back off. If this fails, the message is put in the DLQ topic. Applications can handle these messages later or discard them. Messages can be placed in this queue when the consumer service has an outage (e.g., timeouts) or if the consumer service encounters a poison pill (e.g., 500 HTTP Response).
Consumer Service
Consumer Service is stateless REST service for applications to process messages. This service contains business logic that was part of the processing originally available in the Kafka consumer application. With this new model, Kafka consumption (MPS) can be separated from message processing (Consumer Service). Below, you will find the REST API spec that must be implemented by any Consumer Service:
Kafka Offset Commit Thread
Kafka offset committing is implemented as a separate thread (i.e., the offset_commit thread). This thread wakes up at regular intervals (e.g., 1 minute) and commits the latest contiguous offsets which are successfully processed by writer threads.
In the picture above, the offset_commit thread commits offsets 124 and 150 for partitions 0 and 1, respectively
API

Implementation Details
MPS was implemented as a sink connector on Kafka connect. The Kafka Connect framework is well suited for the multiple reasons:
- Multi-tenancy: Multiple connectors can be deployed on a single Kafka Connect cluster
- DLQ handling: Kafka Connect already provides a basic framework for DLQ processing
- Commit flow: Kafka Connect provides convenience methods for commits
- In-built NFRs (Non-Functional Requirements): Kafka Connect provides many non-functional features (e.g., scalability, reliability)
Conclusion
MPS has eliminated rebalances due to slowness in downstream systems as it guarantees reader thread will put all messages in poll list in pendingQueue within allocated time of max.poll.interval.ms 5 minutes. The only rebalances we see are due to Kubernetes POD restarts and exceedingly rare network slowness between Kafka cluster and MPS. But with small consumer groups, the duration of these cycles is negligible and do not exceed processing SLAs (Service Level Agreements). MPS service and Kafka cluster should be hosted in the same cloud and region to reduce network related issues between them.
Cooperative handling of poison pills with applications detecting them and notifying MPS through the return codes 600 & 700 works as planned.
The cost benefits of this solution are realized in two areas. First, stateless consumer services can scale quickly in the Kubernetes environment and do not have to be scaled upfront for the holidays or any campaign events. Secondly, Kafka cluster sizes are no longer dependent on the partition sizes, they can be truly scaled for the throughput with about 5–10 MB per partition.
Huge improvements have been seen in rebalance related site issues and operational requests in Kafka pipelines due to yearly scaling of Kafka clusters for the holidays.
Sudden spikes in the traffic do not need to scale Kafka partitions anymore as stateless consumer services are easily auto scaled in the Kubernetes environment to handle message bursts.
Acknowledgements
This work would not be successful without the tireless aid of many people, some of whom are listed here:
(Aditya Athalye, Anuj Garg, Chandraprabha Rajput, Dilip Jaiswar, Gurpinder Singh, Hemant Tamhankar, Kamlesh Sangani, Malavika Gaddam, Mayakumar Vembunarayanan, Peter Newcomb, Raghu Baddam, Rohit Chatter, Sandip Mohod, Srikanth Bhattiprolu, Sriram Uppuluri, Thiruvalluvan M. G.)
Reliably Processing Trillions of Kafka Messages Per Day was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Reliably Processing Trillions of Kafka Messages Per Day | by Ravinder Matte | Walmart Global Tech Blog | Jun, 2024 | Medium