
Coauthor: Ekta Gujral
Assortment planning requires strategically selecting and organizing a range of products to meet customer demands and maximize sales. This process involves analyzing market trends, customer preferences, and competitor strategies to identify potential gaps and opportunities — a process often performed using future trend forecasts. These reports cover textiles and materials innovations, product development, and lifestyle and interiors trends. This information can be used to extract attributes about related products.
Correctly predicted attributes improve catalog mapping, which generates search tags on better quality content for products. Customers are able to filter for products based on their exact needs and compare product variants readily, resulting in a more seamless shopping experience. The Product Attribute Extraction (PAE) engine can help the retail industry to onboard new items or extract attributes from an existing catalog. We conducted extensive experiments described in this longer paper to show that PAE is an effective, flexible framework on par or superior (avg. 92.5% F1-Score) compared to existing state-of-the-art attribute extraction frameworks.
Problem Definition
 Figure 1: Example of Text and Images for Attribute Extraction
Figure 1: Example of Text and Images for Attribute ExtractionFigure 1 is a sample of the type of content provided in PDF format for assortment planning. This information is presented with unstructured text and image data, with detailed attributes (knitted sweater vests, roll neck, slouchy fit with button detailing). Based on these attribute insights, assortment planners would work closely with suppliers and designers to curate a collection of such clothing items to complete the look. This content can also serve as a rich source of data to enrich product attributes if the information can be accurately extracted. The challenge for our team was to use these PDF files alongside a LLM prompt to find the values for these target attributes, at a higher success rate than existing frameworks.
Product Attribute Extraction Method
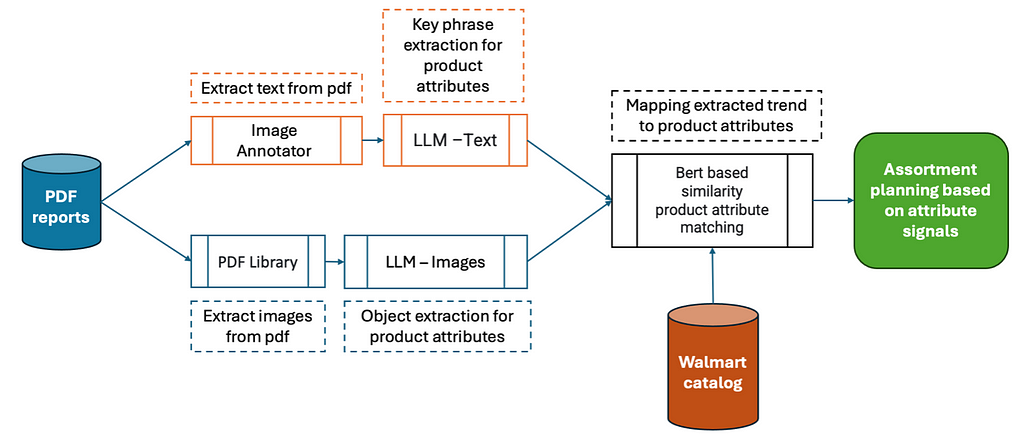 Figure 2: Overview of the proposed Product Attribute Extraction Engine
Figure 2: Overview of the proposed Product Attribute Extraction EngineWe tackled the attribute value extraction as paired tasks running in parallel, i.e., extracting the attribute values from image and text together. The input of the task is a “textual information T, set of images I per PDF page, and the output is the product attributes values. As shown in figure 2, our approach relies on four successive steps:
1. Text and Image Extraction — extracts all the text (paragraphs) and relevant images from the given PDF files.
2. Attribute Extraction — uses LLM models to extract relevant attributes from the images and text.
3. Merging — consolidates attributes into each category and keeps unique values for each attribute.
4. Catalog Matching — helps retailers to find a product that matches with existing inventory and plan for future assortment.
Step 1: Text Extraction from PDF
Text extraction converts the data contained in PDF files into an editable and searchable format. The layout complexity of a PDF document can make the extraction process difficult. For instance, the presence of multiple columns, images, tables, and footnotes can complicate the extraction of pure text. Another challenge is the use of non-standard or custom fonts in PDFs, which can lead to inaccurate extraction results. Moreover, the presence of ‘noise’ such as headers, footers, HTML tags and page numbers can also interfere with the extraction process.
 Figure 3: Text Extraction via Image Annotator
Figure 3: Text Extraction via Image AnnotatorThere are numerous tools available for text extraction, such as pdfMiner or pdfquery. Figure 3 represents the process we used to extract the text from pdf files. First, we split the PDF files into PIL (Python Imaging Library) images using “convert from path” function from the pdf2image. Internally, the function uses the pdfinfo command-line tool to extract metadata from the PDF file, such as the number of pages. It then uses the pdftocairo command-line tool to convert each page of the PDF into an image. Second, we convert the images to grayscale and perform morphological transformations on each page by applying a morphological gradient operator to enhance and isolate text regions. Finally, we use an image annotator with Optical Character Recognition (OCR) capabilities for text extraction. Once the text is extracted, we use a spell corrector like LanguageTool to fix any misinterpreted text from OCR.
Step 2: Image Extraction from PDF
PDF files can contain images in various formats such as JPEG, PNG, or TIFF. Extracting images from different formats may require multiple techniques. Extracting images from large PDF files efficiently and in a timely manner can be a challenge, especially when dealing with limited system resources. To tackle the above-mentioned challenges, we exploit pure-python PDF library [4], as a standalone library for directly extracting image objects from PDF files. With pure-python PDF library, we identify the pages with images and extract them as raw byte strings. Then, using Pillow, the extracted images are processed and saved in jpg formats. Figure 4 shows extracted images from files.
 Figure 4: Example of extracted images from PDF files
Figure 4: Example of extracted images from PDF filesStep 3: Attribute Extraction from Text
PDF reports consist of specific products or product categories, providing details on their design, features, materials, colors, and styles. We extracted 8 product attributes, namely Color, Sleeve Style, Product Type, Material, Features, Categories, Age, and Neck. We also extract hashtags to discover and explore content related to a specific topic or theme in catalog. We utilized a LLM model for extracting the attributes. Below is a sample prompt:
Generate me color, sleeve style, product type, material, features, categories, age, and neck attributes of below text:

The output is then processed in dictionary type as follows:

Step 4: Attribute Extraction from Images
The recognition of visual image attributes is vital for understanding fashion, improving catalogs, enhancing visual searches, and providing recommendations. In fashion images, the dimensionality can be higher due to the complexity and diversity of items. For instance, a single piece of clothing can have multiple attributes for color, fabric type, style, design details, size, brand, and others. Hence, image attribute extraction has become more complex than text. However, these attributes can be extracted using various computer vision techniques, such as image segmentation, object detection, pattern recognition and deep learning algorithms. In this work, we explore a vision-based LLM model. Each extracted image as shown in figure 5 is converted to base64 encoding. Base64 encoding is a method of converting binary data, such as an image, into ASCII text format. This is required as current LLM models take text format as input.
 Figure 5: Image Example
Figure 5: Image ExampleThe ASCII text format example:

Next, we use this encoded string along with LLM prompt to generate the product attributes as follow:
“Generate a list format color, sleeve style, product type, material attributes from the below image. Also give me features, categories, age and neck attributes from below image.”
The output is then processed in dictionary type as follow:

Another common issue that arises is the presence of noisy and missing labels. It is a challenging task to accurately label and annotate all the relevant information for every page in the PDF. Despite employing various automated and manual annotation processes, it is nearly impossible to obtain perfectly labeled, structured data. To address this, we employ image pre-processing or data cleaning techniques to eliminate duplicate, noisy, and invalid images before proceeding with attribute extraction. Once we extract attributes from text and images on each page, we aggregate them per page for our further analysis.
Step 5: Product Attribute Matching
One of the challenges of product attribute matching is having multiple variants for the same value of one attribute. For example, “vneck” and “V-Neck” is consolidated into “V-Neck” as neck product attribute. Figure 6 shows our framework to match the predicted attributes to the existing catalog attributes. We exploit pre-trained BERT uncased model. BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. We create representations or embeddings for predicted attributes and existing product attributes. Finally, we use cosine similarity to match the similar product attributes from the catalog.
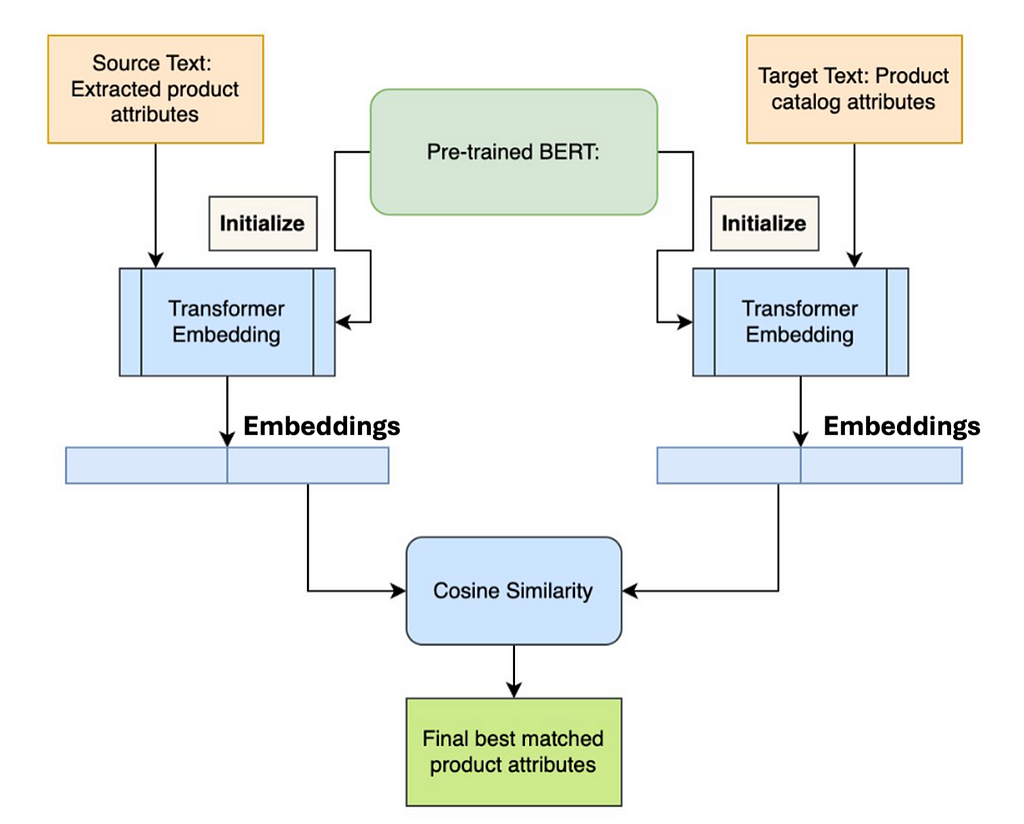 Figure 6: Product Attribute Matching Framework
Figure 6: Product Attribute Matching FrameworkConclusion
Our Product Attribution Extraction framework correctly extracts the defined attributes in order to plan the future assortment and associate these predicted attributes to the current product in a catalog for better planning. We used Accuracy, True Positive Rate (Recall) and F1 score as the evaluation metrics, to compare against text attribute value extractors TopicRank and sOpenTag as well as visual attribute value extractors Vilt and BLIP. Our methods proved both faster and more accurate, with a perfect F1 score for image attribute extraction and a 92.5% F1 score for text. For more details on these experiments, refer to our full research paper.
There is still room for improving our methods. One direction is to explore LLM models which can take sets of images & text and provide consolidate attributes. Another direction is to further improve the product matching system that consists of product images so that our method can be more suitable for customers during the search for different products on E-commerce websites.
Acknowledgement
PAE is being used within Walmart Global Tech. This engine is co-developed with Ekta Gujral. Special thanks to Jonathan Sidhu & Magdaline Frank for this initiative and support.
Please drop a comment if you have any suggestions. Please do cite our work using:
@article{PAE2024,title={ PAE: LLM-based Product Attribute Extraction for E-Commerce Fashion Trends },author={Apurva Sinha and Ekta Gujral},journal={arXiv preprint arXiv:2405.17533}, url = “https://doi.org/10.48550/arXiv.2405.17533”, year={2024}}
Extracting Product Attributes from PDFs using PAE Framework was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Extracting Product Attributes from PDFs using PAE Framework | by Apurva Sinha | Walmart Global Tech Blog | Jun, 2024 | Medium