 Credit: Voice reorder your grocery shopping
Credit: Voice reorder your grocery shopping
E-commerce voice ordering systems need to recognize multiple product name entities from ordering utterances. Existing voice ordering systems such as Amazon Alexa can capture only a single product name entity. This restrains users from ordering multiple items with one utterance. In recent years, pre-trained language models, e.g., BERT and GPT-2, have shown promising results on NLP benchmarks like Super-GLUE. However, they can’t perfectly generalize to this Multiple Product Name Entity Recognition (MPNER) task due to the ambiguity in voice ordering utterances. To fill this research gap, we propose Entity Transformer (ET) neural network architectures which recognize up to 10 items in an utterance. In our evaluation, the best ET model (conveRT + ngram + ET) has a performance improvement of 12% on our test set compared to the non-neural model and outperforms BERT with ET as well. This helps customers finalize their shopping cart via voice dialog, which improves shopping efficiency and experience.
Problem Definition
 A Sample Utterance
A Sample UtteranceTake a sample utterance like “add seven apples one gallon of milk two bags of sunflower seeds fresh garlic disposable wipes” as an example. The task of product name entity recognition is to identify product entities such as “apples”, “milk”, “sunflower seeds”, “fresh garlic”, and “disposable wipes”. Both the amount and diversity of product names are challenges for segmenting and extracting them. Usually, the Automated Speech Recognition (ASR) systems don’t produce punctuations and symbols when translating voice into text, due to their limitation. This significantly increases the challenge to separate adjacent product names. Since these barriers (e.g., entity amount, missing punctuation, and product diversity) are unusual for traditional NER tasks, existing methods may not generalize to MPNER well.
Model Architecture
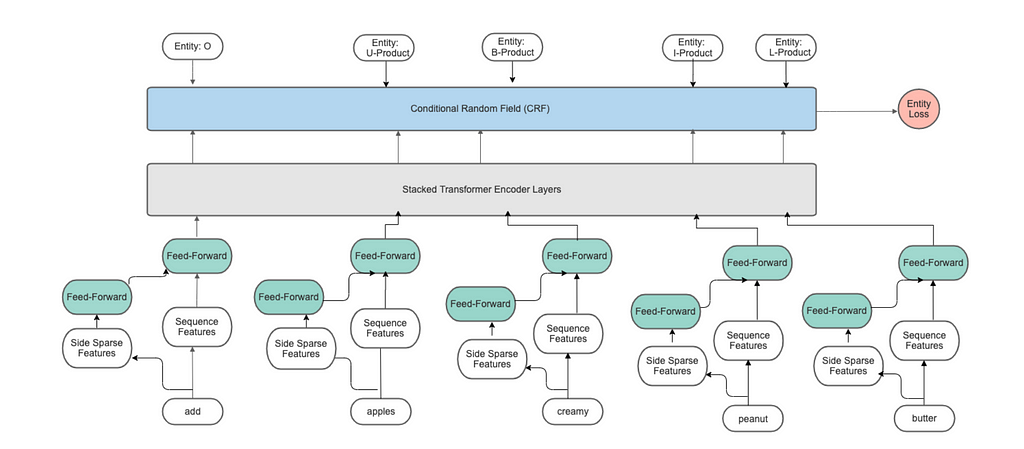 Entity Transformer architecture
Entity Transformer architectureAn Encoder-Decoder architecture, called Entity Transformer (ET), is developed for the proposed model inspired by (Bunk et al., 2020). In this design, the input sequence is encoded by the stack of transformer layers (Vaswani et al., 2017). The encoder maps the input sequence (x₁, …., xₙ) to a sequence of continuous representations E =(e₁, …, eₙ). From E, the Conditional Random Field (CRF) decoder produces the sequence of output entity-tag labels predictions (l₁, …, lₙ).
Features
For dense features, we extracted input sequence features from the various pre-trained language models (hugging face), such as conveRT (Henderson et al., 2020) from PolyAI, BERT(Devlin et al., 2019), and Roberta (Liu et al., 2019). Side Sparse features are one-hot token level encodings and multi-hot character n-gram (n≤4) features. The sparse features are passed to the feed-forward layer whose weights are shared through the input sequence. A Feedforward Neural Network (FNN) layer output and dense sequence features are concatenated before passing to Transformer encoder layers.
Transformers
For encoding the input sequences, we used stacked transformers layers (N ≤6) with relative position attention. Each transformer encoder layer is composed of multi-headed attention layers and point-wise feed-forward layers. These sub-layers produce an output of dimension dₘₒₑₗ = 256.The number of attention heads: Nₕₑₐₛ = 4.The number of units in the transformer: S = 256.
Conditional Random Field
The decoder for the named entity recognition task is Conditional Random Field (CRF) (Lample et al., 2016) which jointly models the sequence of tagging decisions of an input sequence. we used the BILOU tagging scheme.
Model Training and Inference
The model training and inference details are present in this paper which was published in WeCNLP (West Coast NLP)2021 Summit (Gubbala and
Zhang, 2021)
Evaluation
We created an MPNER data set consisting of about 1M product name entities from voice order shopping utterances. This dataset has a 500k training subset and a 65k test subset utterances. The utterance in each data example has a random number of (between 1 and 10) products. This data is generated from 70 seed voice order utterance variations, using synonym-based data augmentation of the most popular 40k products from various departments. The test data created with 5k unseen products also from the same categories. Table 1 shows the model evaluation results on the MPNER data set. Our best model configuration is with sparse features of word count vectors, char n-gram count vectors (n≤4), and conveRT pre-trained dense embeddings.
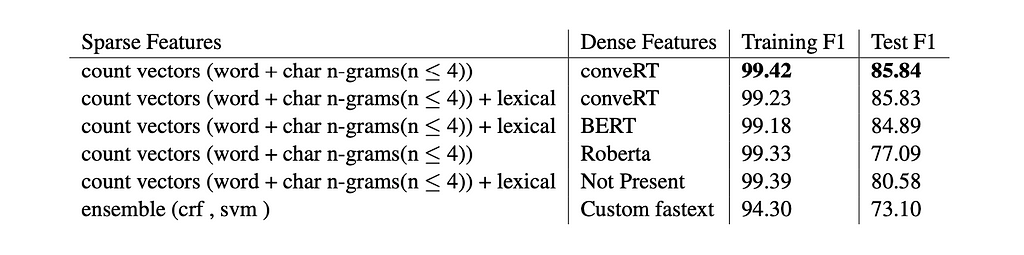 Table 1: Model Performance on MPNER task
Table 1: Model Performance on MPNER taskIn the future, we plan to investigate customized pre-trained models for MPNER task.
References:
[1] Praneeth Gubbala and Xuan Zhang. 2021. A sequence
to sequence model for extracting multiple product
name entities from dialog.
[2] Tanja Bunk, Daksh Varshneya, Vladimir Vlasov, and
Alan Nichol. 2020. Diet: Lightweight language un-
derstanding for dialogue systems.
[3] Matthew Henderson, I ̃nigo Casanueva, Nikola Mrkˇsi ́c,
Pei-Hao Su, Tsung-Hsien Wen, and Ivan Vuli ́c. 2020.
Convert: Efficient and accurate conversational repre-
sentations from transformers.
[4] Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
[5] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man-dar Joshi, Danqi Chen, Omer Levy, Mike Lewis,Luke Zettlemoyer, and Veselin Stoyanov. 2019.Roberta: A robustly optimized BERT pretraining
approach. CoRR, abs/1907.11692.
[6] Hugging Face. https://huggingface.co/
Voice Reorder Experience: add Multiple Product Items to your shopping cart was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.