
Machine Learning Engineering for Production — Chapter 1
“We’re here to make a dent in the universe, Otherwise, why else even be here?” ~ Steve Jobs
As humans, we have a tendency to achieve the seemingly impossible, to triumph in dire circumstances, to aim for the sun, to settle on Mars. We have continued to make world a better place by constantly taking on battles to improve using our knowledge and belief to change for a stronger tomorrow.
The world is evolving everyday and so is its ways of working. The amount of data we produce on day-to-day basis is humongous. Data Science is not a singular entity today, it is finding its application across various other fields. As the world is growing, data scientists need to build solutions for a huge population and vital to make their solution scalable.
Scientists and engineers are inspired to create an intelligent ecosystem of smart devices by reducing manual touch points and fueling evolution. Self-driving automobiles, manufacturing robots, intelligent assistants, disease mapping, automated financial investment, unmanned aerial vehicles (drones), and other similar endeavours are a few examples.
 (Source)
(Source)How did we unlock the pathway to this wonderland ? — Data is the key
When data is analysed, it transforms into knowledge. Knowledge when learned leads to predictions that enable machines to recognise patterns and function intelligently. This is called as Machine learning — in other terms we can say ML allows the user to feed a computer algorithm an immense amount of data and have the computer analyse and make data-driven recommendations and decisions based on only the input data. If any corrections are identified, the algorithm can incorporate that information to improve its future decision making.[1]
To reach users and fulfil its objective, ML must be linked with other processes(Figure II). This iterative process includes scoping, data collection, modelling, deployment, and monitoring. ML embedded in this iterative process is termed Machine learning operations(MLOps). MLOps is the entire process of building intelligent systems that can carry out tasks with little to no human intervention.
In layman’s terms, MLOps is completely cooked but ML is only halfway there.
Let’s look at an example of a machine learning algorithm deployment — the use case is to identify the watch with scratch in production before rolling it out to the client(Figure I).
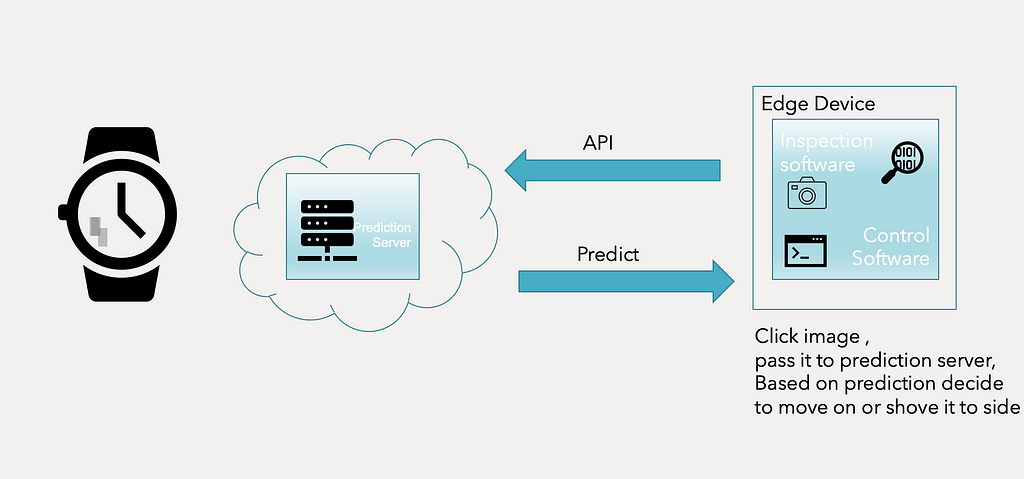 Figure I. Deployment Example
Figure I. Deployment ExampleAn inspection software is in charge of photographing watches and transmitting them to a prediction server, which implies a learning algorithm to detect whether or not the watch has scratches. The prediction server determines whether to proceed or to set the watch aside based on this assessment.
Key Challenges
After engineering peripheral points around the core ML model, what could possibly can go wrong?
Data drift/Concept drift : The statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways. This causes problems because the predictions become less accurate as time passes [2]. For instance, production deployment photographs show darker images because the lighting conditions in the factory have changed since the training set was gathered.
POC to Production Gap : When ML projects encounter significant bottlenecks and challenges on their route towards practical deployment [3]. We need to write necessary auxiliary code required to make the model production ready, beyond the initial ML model code. (Figure II)
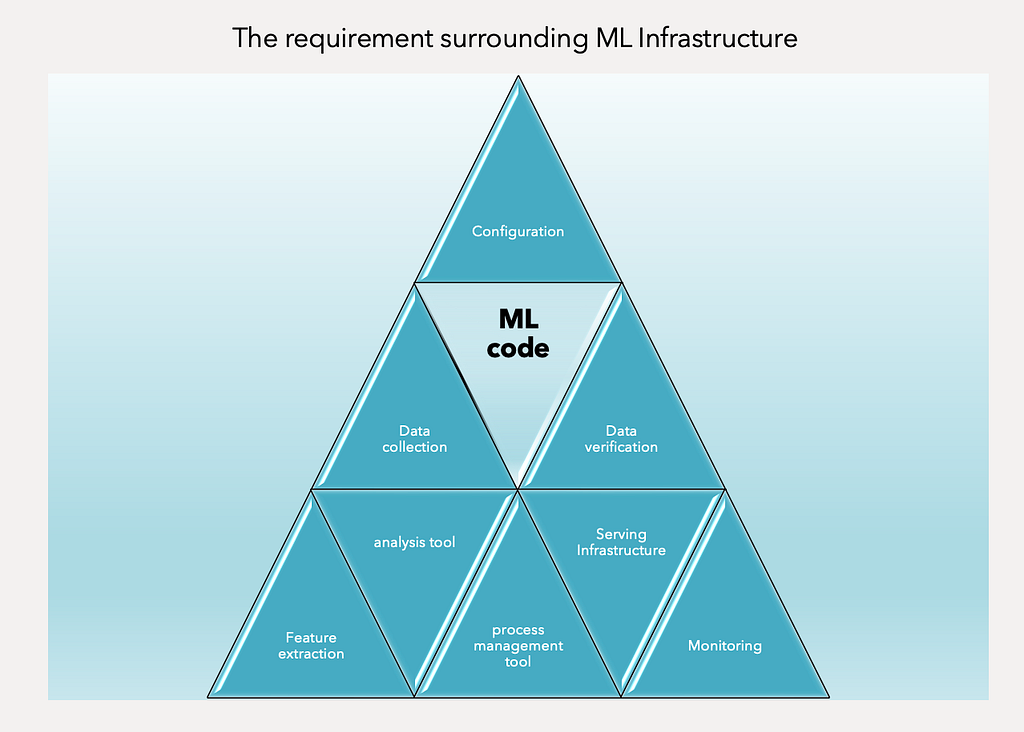 Figure II: the requirement surrounding ML Infrastructure
Figure II: the requirement surrounding ML InfrastructureMachine Learning System — The Journey
Building an ML system is a comprehensive and complex service but the process can be streamlined if the below flow is followed (Figure III)
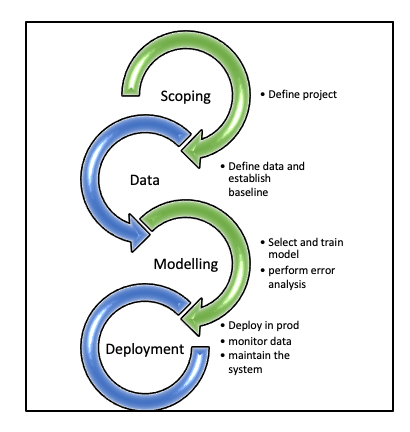 Figure III. ML Project lifecycle
Figure III. ML Project lifecycle- SCOPING PHASE- Determine what to work on
- DATA PHASE- Define data and create a baseline
- MODELLING PHASE- Choose and train a model on the provided data, then analyse the errors.
- DEPLOYMENT PHASE- Deploy in production, monitor the incoming data, and maintain the system (iterate the error analysis process, re-train the model, and update the dataset with the newly projected values).
Scoping Phase
What exactly do you want your ML system to accomplish? Is it a regression or a classification problem? What are your features, and what are your targets? Thus, in this phase, you define your goals and aspirations.
To achieve the above objectives, we perform the following steps as part of the scoping phase.
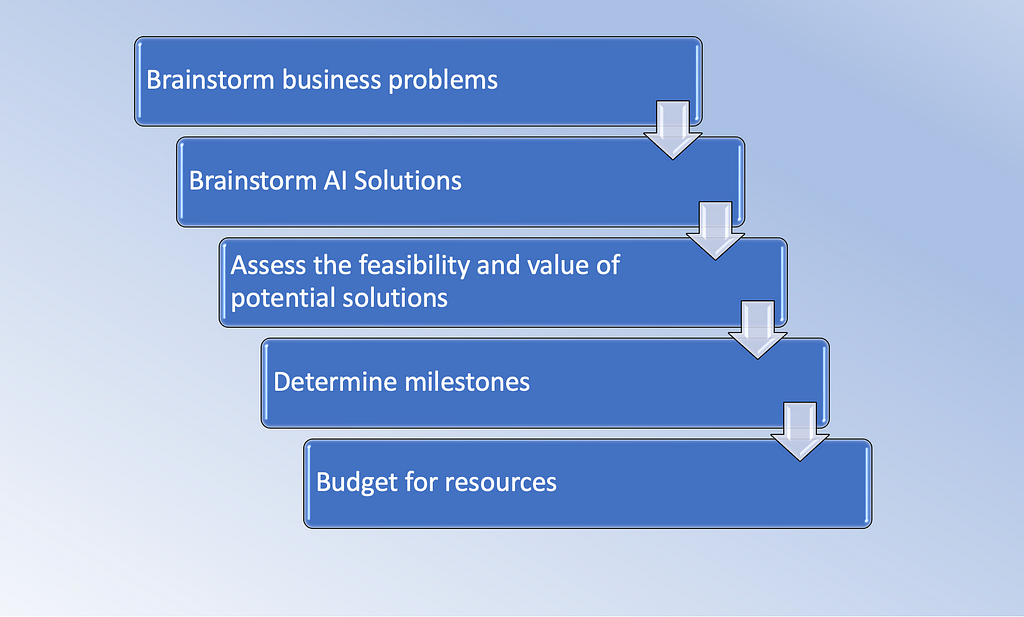 Figure IV. Steps in Scoping Phase
Figure IV. Steps in Scoping PhaseIn modern ML lifecycles and project development Ethical considerations find a pivotal position. It is important to ask questions like
- Is this project creating net positive societal value?
- Is this project reasonably fair and free from bias?
- Have any ethical concerns been openly aired and debated?
Data Phase
Define Data and establish the baseline
Baseline Establishment — helps in prioritising what to work on. Assuming for a speech recognition system the measured accuracy is something like —
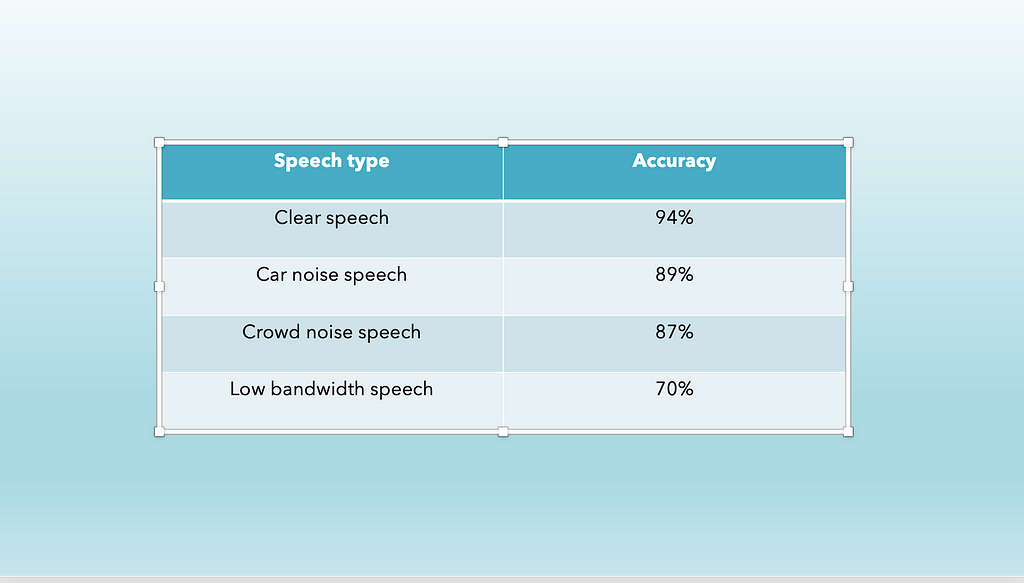 Figure V. Accuracy of speech recognition system
Figure V. Accuracy of speech recognition systemAlthough accuracy is lowest for low bandwidth speech, and one might jump to a conclusion to improve the same but, drawing comparison to the baseline would help in identifying the actual focus areas as in the above case HLP (Human level Performance) for a low bandwidth speech is almost similar to the system under consideration.
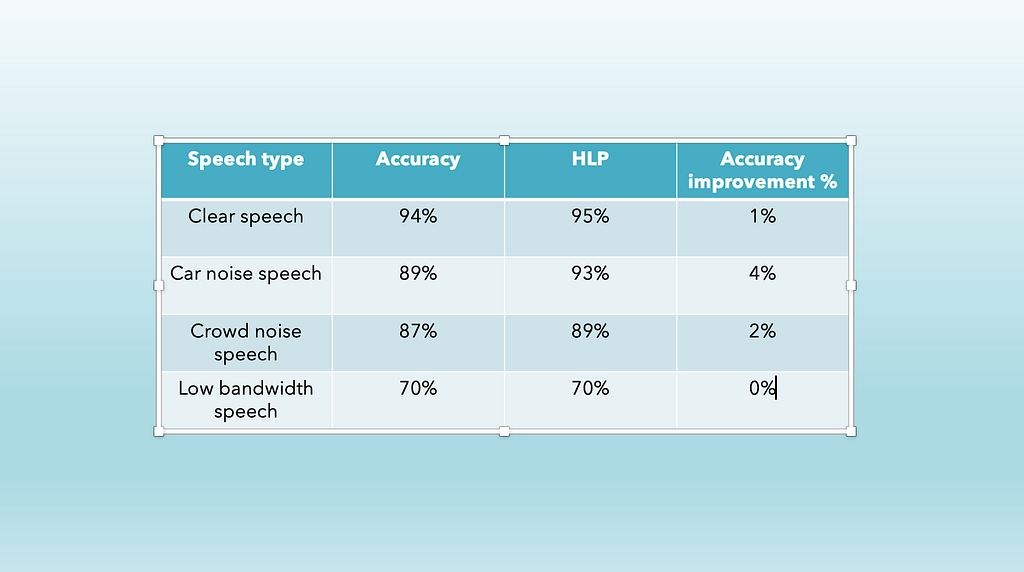 Figure VI speech recognition system
Figure VI speech recognition systemAs demonstrated in Figure VI, low bandwidth speech has a 0% improvement, and humans cannot recognise speech, so we can skip working on it and focus on improving automobile noise speech, which will increase the total accuracy of the model by 4%. As a result, HLP assisted in establishing a baseline for where to focus efforts.
Common techniques for establishing a baseline:
- Human level performance (HLP)- mostly for unstructured data
- Literature search to investigate possibilities (course, blog, open-source projects, previous research)
- Explore pre existing or half baked implementation to get a ballpark idea
- If an earlier system exists, evaluate its performance.
Label and Organise data
As ML lifecycle is an iterative procedure, we collect data periodically in order to improve the model. If there is a significant difference in model performance after supplying more data, we can choose to discard data. Hence we would know if the dataset obtained would work or not.
Points to remember while labelling data:
- We can label the data in 3 ways — In-house, Outsourced, Crowdsourced
- Appointing MLE’s to label data is expensive
- labels can be identified by eg. for speech recognition (any fluent speaker), for medical diagnosis/factory inspection (subject matter expert), for recommender systems (mostly difficult to label)
- Data shouldn’t be increased more than 10* times at a time
Data Pipeline
Data pipeline is a set of tools and processes used to automate the movement and transformation of data between a source system and a target repository. It is not only the core data which needs to be maintained but the other attributes associated which completes the data story. Maintaining these attributes play a vital role in error analysis, spotting unexpected effects and keeping track of data origin.
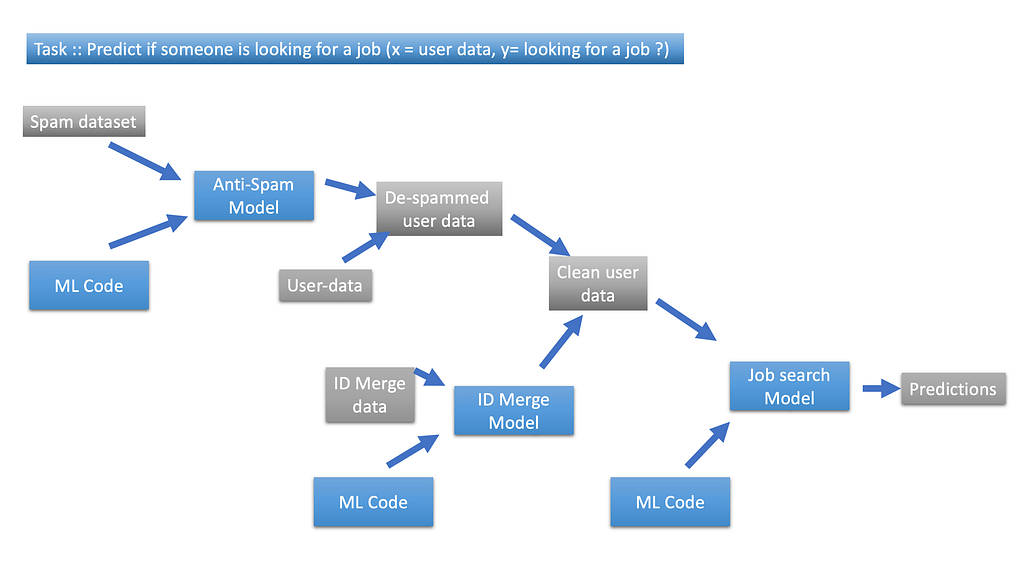 Figure VII. show Data pipeline example
Figure VII. show Data pipeline exampleData Provence and Lineage — Keep track of data Provence and lineage either by having extensive documentation or by using sophisticated tools to replicate the rest of data pipeline without too much unnecessary complexity
Metadata — Storing metadata in timely way helps to generate key insights, its like commenting the code at right time so that if something goes wrong and you need to revisit you have the code docs to understand what exactly does the code do.
It is a key step to make a transition from POC to the solution in production. While doing POC, main focus is on getting workable prototype, so data pre-processing can be manual, but in production phase the process needs to be automated and requires usage of tools like TensorFlow, Apache bean, Airflow etc. to make sure data pipeline is replicable.
Modelling phase
Model development is an iterative process (Figure IV). Model development is the core of the machine learning model lifecycle. The central roles in this stage are the data scientist and the ML engineer.
The process starts with selecting a baseline architecture. It should be a relatively simple model which is expected to have solid results with minimal effort. This model can later be compared to the more complex models that are trained later. In training step data scientists will experiment with different architectures along with feature engineering and feature selection. These models are then trained on the training set with the hope that they will learn the desired task and generalize to new examples as well. Finally, the arsenal of models developed need to be evaluated on the target model metric.
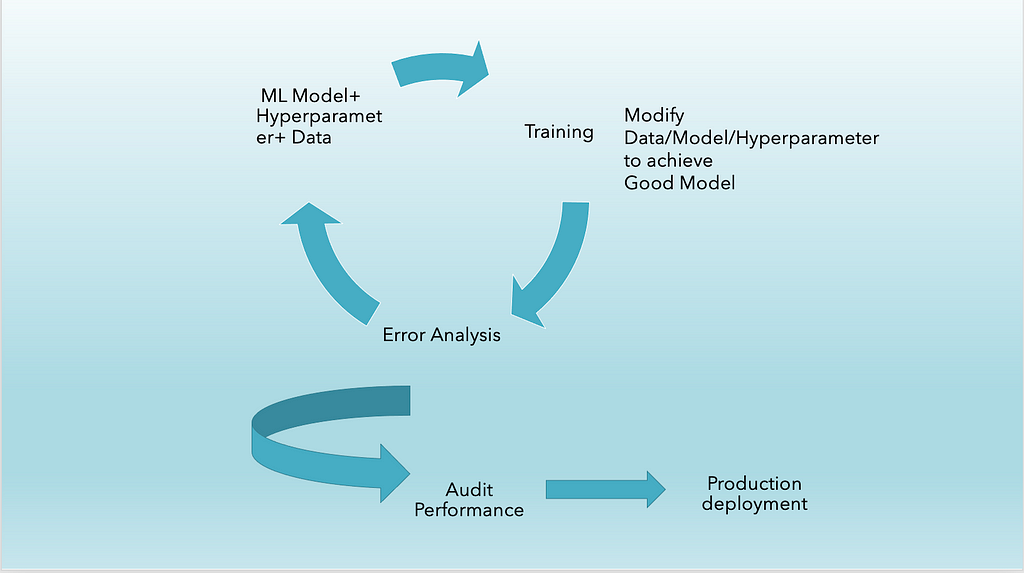 Figure IV. Show Modelling an iterative process
Figure IV. Show Modelling an iterative processDeployment and Monitoring Phase
The initial deployment is just halfway to completion, and the second half of the work begins only after the first deployment. There are various kind of deployment patterns :
Shadow mode deployment — No ML choices are taken in account.
In shadow mode deployment, the ML algorithm shadows the human in parallel, and no ML choices are taken into account at this phase; the goal is to collect data on how the learning algorithm performs and how it compares to human judgement. Identifying scratches on a mobile phone, for example, was formerly done by humans and is now done by automated machines with embedded learning algorithms.
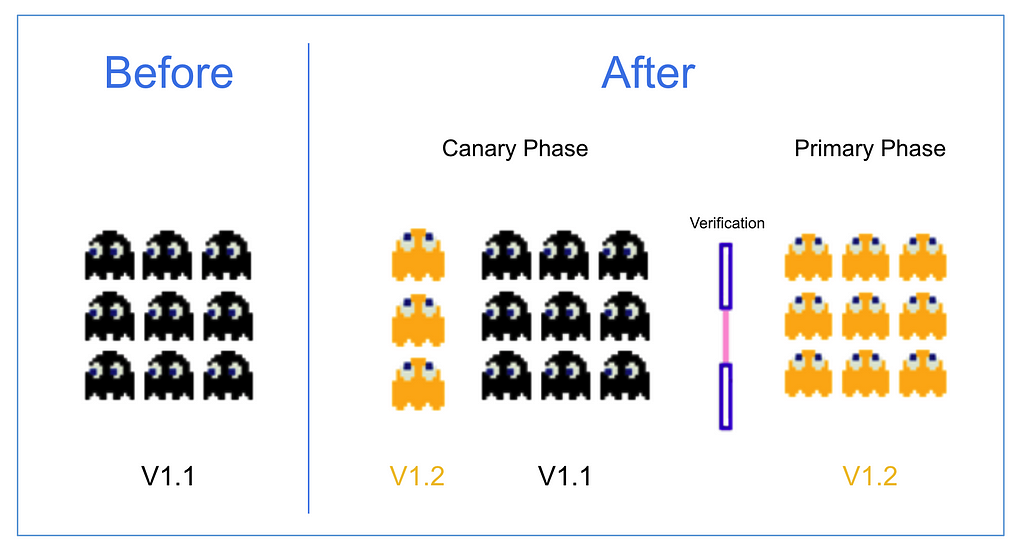 Canary Deployment(Source)
Canary Deployment(Source)Canary deployment — when ML algorithm has learnt enough and is ready to make real decisions.
In a Canary deployment, we first roll out the ML system to a tiny proportion of traffic (say 5%), system is monitored and traffic is incrementally ramped up.
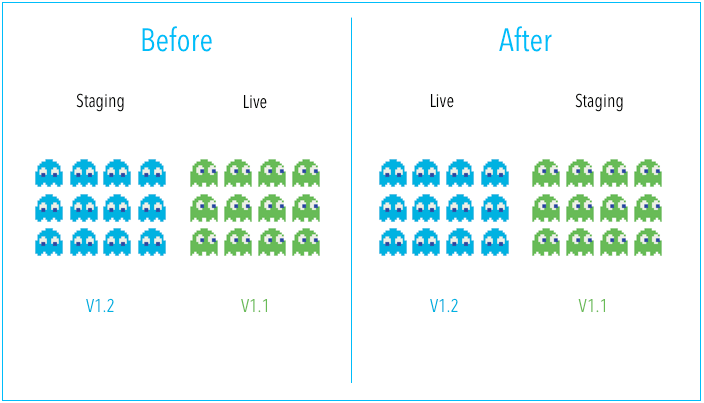 Blue Green Deployment(Source)
Blue Green Deployment(Source)Blue Green deployment —a technique that reduces downtime and risk by running two identical production environments called Blue and Green.
There is an option to switch between old and new algorithm or prediction server implementations. e.g. updating the phone software (New/Green version) and reverting it back (Old/Blue version) with factory setting if the new updates aren’t satisfactory.
After the deployment is completed, it is imperative that the system is monitored for any potential breakdown or surprises. Industry standard metrics for monitoring are —
- Software metrics — Memory, compute, latency, throughput, server load
- Input metrics — Average i/p length., Average i/p volume, Number of missing values etc.
- Output Metrics- eg. how often the intelligent system return null values , incorrect values , or no. of times re-do are needed, no. of times user gives up on intelligent system etc.
Summary
References & credits:
- What Is Machine Learning - ML - and Why Is It Important? | NetApp
- Concept drift - Wikipedia
- Bridging AI’s Proof-of-Concept to Production Gap — Insights from Andrew Ng
- Machine Learning Life Cycle: Top 3 Components - Deepchecks
Unsung Saga of MLOps was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Unsung Saga of MLOps. Machine Learning Engineering for… | by Jaya Nupur | Walmart Global Tech Blog | Medium