
CTF competitions often turn out to be a great amusement, but they also play a very important role in training of IT security specialists. Such kinds of challenges are challenging both to contestants and organizers. This article will describe organizational aspects related to such competitions, taking European Cyber Security Challenge 2018 qualifications as an example.
- web – web applications in the organizer’s infrastructure, which have to be somehow attacked,
- stegano – tasks in which steganography techniques were used (e.g. analysis of a wav file with hidden text transmission),
- crypto – tasks related to breaking ciphers, digital signatures and other cryptographic systems,
- pwn – tasks which require usage of binary exploitation techniques (e.g. buffer overflow, heap exploitation),
- forensic – various investigations (eg. analysis of communication dumps),
- recon – usually multi-step reconnaissance performed by following various traces,
- re – tasks related to reverse engineering (e.g. analysis of executables),
- misc – various riddles which don’t match to the above categories.
Introduction
Capture the Flag most often is a competition which is held in particular time frame. Contestants are presented with few to few thousand tasks with varying difficulty level. Each task contains more or less precise hints about the suggested way of solving it. It also has references to appropriate resources (URL of web application to be hacked, binaries etc).
Typical task categories are:
When task is succesfully solved, the contestant receives a flag, which is an evidence of task completion.
hack.cert.pl portal
What every CTF needs is to somehow distribute the tasks to the contestants and to verify the correctness of flags submitted by them. If the scale of a project is small, it can be done fully manually using e-mails, for instance.
All competitions organized by CERT Polska are ran in a special web portal named hack.CERT.PL, which is responsible for user accounting, presenting task objectives, flag verification and presentation of a ranking list for active competitions.

Task list on hack.cert.pl web portal
Hosted services
While it is possible to launch particular tasks from “re” or “crypto” categories without specialized infrastructure, it is required to provide special services for “pwn” and “web” categories. Such services have to be continously available to CTF contestants.
One of most important problems with running such kind of services is variety of expectations, especially if the contest is authored by few different persons. While one task author needs a stack of Ubuntu + nginx + Node.js in order to provide his task from “web” category, the other one may need an obsolete Debian version in order to provide a task from “pwn” category. Because the variety of target environments may be very high, it worth to consider usage of Docker. Because most of the tasks may need more than one container (usually a tandem of database + http server), Docker Compose may be also useful.
This way, we’ve introduced a requirement for each task to be delivered in a form of source code package containing docker-compose.yml file, which will use precompiled images (np. mysql/mysql-server) and custom containers defined using Dockerfiles.
Because a team of CTF task authors may consist of even a dozen persons, such design decision eliminated most of “works for me” kind of problems. On the other hand, additional time was spent on providing help for colleagues which are less familiar with Docker technology. Moreover, some problems related to task deployment were solved yet on the development stage.
A docker-compose.yml file for “web blind” task
A Dockerfile for “web blind” task
A uwsgi.ini file for “web blind” task
Comment: web service for “web blind” task was a Flask application contained in webblind.py file. Flask Instance was in a variable named app.
All services were run under watchful eye of systemd:
Systemd configuration for web blind task (/etc/systemd/system/ctf-webblind.service)
Comment: After adding a new service it is required to issue systemctl enable ctf-webblind command. Next, the service should be started using service ctf-webblind start. One may use journalctl -fu ctf-webblind command in order to see a log stream for particular service.
High-risk services (nsjail)
While solving some tasks, especially the ones from “pwn” category, the attacker may obtain ability to perform remote code execution (RCE) in the task’s infrastructure.
Such kind of vulnerability could be used to attack organizer’s infrastructure. The most typical approach for such attack is a “fork bomb” – a program which constantly runs new copies of itself until system resources are exhausted.
The simplest fork-bomb in bash
Comment: You should consider running a fork-bomb on your own, test infrastructure before releasing it to the contestants.
Because Docker containers were not designed for running untrusted code, further infrastructure hardening could be done using NsJail tool.
NsJail is a Linux tool for process isolation. It is using kernel functions related to the control groups, resource limits and system call filters. For our case, the “network service inetd style isolation” mode was especially useful.
Launching NsJail in this mode (using -Ml switch) caused that network service was exposed on the provided port. For every incoming connection, NsJail will create a separate control group, assign appropriate limits to it and run the particular program, pipeing it’s I/O streams to the connection socket.
Because each connection would have it’s own control group and it’s own process launched in it, resource exhaustion is possible only in context of particular group. Thus, a particular contestant launching a fork-bomb will render himself unable to use services, but other contestants will be not significantly affected.
Example of full nsjail configuration:
A Dockerfile for “Pwn and Chill” task
A launcher script nsjail.sh
Comments: we’ve build nsjail ourselves using slightly modified source code. Original image could be built this way:
It’s worth to become familiar with meaning of different nsjail options. The command provided above would cause that directories /app, /bin, /lib, /lib32, /lib64 will be remounted in a sandbox in read-only mode. It is also possible to selectively mount devices or to mount a small, writeable tmpfs which will be unique for each instance (so the contestants will not interfere between themselves).
Installation of lib32z1 is necessary if the service to be attacked is a binary built in 32 bit mode (-m32). In case of lack of this library we could receive a misleading error message /app/pwn_me – no such file or directory.
Removal of /var/lib/apt/lists/* performed within a single RUN clause along with the package install commands will help to save several hundreds of megabytes in the resulting Docker image.
Blondies in “web” tasks
An interesting case occurs with some tasks from the “web” category, in which it is required to trick other application user into an XSS attack. Such “another user” is usually a hypothetical system administrator implemented as a bot in organizer’s infrastructure.
In the “web art” task, contestants had a possibility to use contact form in order to report a dead link to the administrator. A web application was vulnerable to XSS attack. The role of robotic administrator was to click into crafted links from these reports. We have set up these bots using Selenium library.
A standard practice with creation of such bots is to run a Chrome browser in headless mode, but this mode of operation doesn’t allow to load plugins. Because in case of “web art” task it was necessary to use additional add-on, bots for this particular task were ran using desktop version of Chrome working under control of xvfb.
A code snippet for web-art task
If (as in case of “web art” task) it is necessary for a bot to see target application under adress 127.0.0.1, it is possible to use supervisord in order to run these two services as one container.
A Dockerfile for web-art task
start.sh script
Reverse proxy (nginx)
Because each task from “web” category was exposing it’s own HTTP server (or at least FastCGI/uWSGI endpoint), it is necessary to apply additional step in order to set them up under friendly hostnames. As a gateway, we have used an nginx server, which was retrieving the whole traffic from ports 80 and 443. This traffic was further redirected to the appropriate container based on the hostname provided. Because a TLS termination point was a front nginx server, it was not necessary to configure certificates separately for each task.
Exemplary nginx vhost definition for strange-captcha task (/etc/nginx/sites-available/strange-captcha)
Load balancing
In tasks from “web” category where bottlenecks were present, it is necessary to estimate a number of concurrent users and consider using load-balancing. Such bottleneck may be a necessity to interact with a bot (like in “web art” task) or necessity to perform some extended computations on the server side (like in “Strange CAPTCHA” task).
The task is much simpler thanks to usage of reverse proxy in a form of nginx server. As a load balancing strategy we suggest ip_hash, due to a relative simplicity of configuration and versatility. A contestant having given IP address will be always routed to the same instance, so the application’s behaviour will be predictable even if a user would cause permanent state changes (e.g. introduction of stored XSS).
Fixed Dockerfile for “web art” task
Fixed /etc/systemd/system/ctf-art command
Fixed nginx config in /etc/nginx/sites-available/web-art
Service monitoring (icinga2)
Because the resulting infrastructure is quite extensive, manual monitoring could be ineffective. Human-based monitoring is prone to mistakes caused by working in a rush. Additional reason to monitor the infrastructure is it’s uncommon nature. CTF contestants attacking particular service may cause it to enter an undesired state which may turn into an involuntary Denial-of-Service attack.
During ECSC 2018 qualifications our infrastructure was monitored with Icinga 2 along with Icinga Web 2 web interface. The first thing that we have started monitoring were nginx virtual hosts.
Host definition in /etc/icinga2/conf.d/hosts.conf
As some kind of innovation, we were also checking differend kinds of services, e.g. servers dedicated for “pwn” tasks and more complicated tasks from “web” category. Task authors were asked to create simple scripts (under a work name “health checks”), which were connecting to the particular service and exploiting it as it would be done by the contestant.
Command definition in /etc/icinga2/conf.d/commands.conf
check_ctf script in /usr/lib/nagios/plugins directory
Addition to the previous host definitions in /etc/icinga2/conf.d/hosts.conf
Comments: setting environment variables TERM and TERMINFO was a work around for problems with pwntools Python library, which was causing troubles when the scripts were ran in unattended mode.
The aforementioned health checks were a some kind of simplified end-to-end tests. It was fairly simple to write them and they were extremely helpful in detecting problems even before the contest was launched.
Healthcheck for pwnfck task (in /opt/ecsc18/healthcheck directory)
Placing monitoring services outside the core infrastructure and network (e.g. on a VPS server in the external company) would give best reliability. Doing it this way would allow to detect possible problems with configuration of firewalls or IDS. We may be not aware of presence of such solutions. It is required to take into account that the process of solving particular tasks may generate a network traffic similiar to the actual attack on the infrastructure.
Icinga automatically reports problems after deploying initial version of “webblind” task.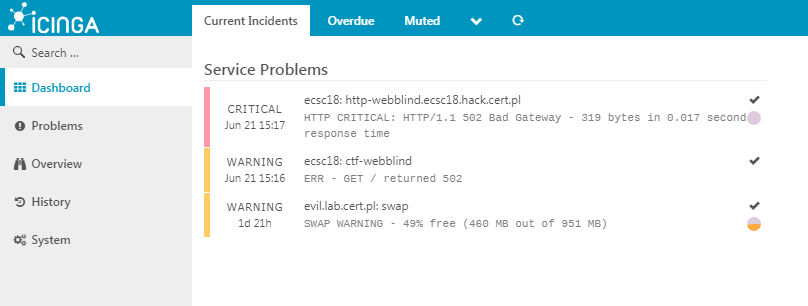
An interesting problem was to monitor bots from “web” category tasks. An attack vector may be related to e.g. leaking information by downloading image from the external server. In such case, a health check script must run such server in order to retrieve leaked information through it. In such case we have used Python’s http.server module (previously known as SimpleHTTPServer).
Health check script for “web art” task
Comments: because the script was exposing a service on all interfaces, it was necessary to block external access to ports 11000-11999, e.g. this way:
In case of this task there are five different container instances which are load-balanced between based on IP hash. However, we would like to know if any of them gets stalled. Because of that, the script takes the source port of the instance as a command line argument. Because health checks may be ran in parallel, we can not let them to run into a port collision when they will try to run a HTTP server. Due to that, the port for a server launched by the health check script is calculated from the source port (e.g. if we test instance on port 10050 then the server will listen on port 11050).
The report form in “web art” task was protected by reCAPTCHA in order to prevent contestants from stalling the “robotic administrator” (aka bot). Unfortunately, this effectively denies the possibility to perform automatic end-to-end tests. Due to that, we have equipped our health check script with a “magic token” which was always considered as a valid reCAPTCHA solution. It a presence of such token was detected by the server, it was omitting the appropriate anti-bot check.
Notifications
Because we would like to succesfully report all accidents detected by Icinga 2 to the administrators, we decided to use Mattermost for that purpose. The choice was based on the fact that we were previously familiar with this messaging platform and most of the team had it configured already.
A hook which was originally sending e-mail notifications was modified into a hook which was posting messages on the appropriate Mattermost channel:

We receive the notification that bot’s load during the contest is too heavy. Thanks to that, we decided to further scale the infrastructure.
Definition of /usr/local/sbin/mwall command
Mattermost access credentials in /etc/icinga2/mattermost.json
Comments: Please remember that the files containing access credentials should be appropriately protected, e.g. using sudo chown nagios:nagios mattermost.json && sudo chmod 640 mattermost.json command. Alternatively, the mwall command may be also flagged with setuid with the read access granted only to the root.
An mwall command may be used by redirecting an arbitrary text to it, for instance: echo test | mwall would cause bot to write “test”.
Contents of /etc/icinga2/scripts/mail-service-notification.sh script
Comments: if it is desired to retrieve emails as well as Mattermost messages, instead of changing mail-service-notification.sh script, you may add additional notification template in templates.conf, apply it in notifications.conf and define a new command in commands.conf file.
The change of form of notifications brought measurable benefits. Informations about failures were interspersed with ordinary communication related to the organization of our competition. It caused that messages posted by notification bot were noticeable. It also gave us the possibility to discuss problems with the team on the same channel.
An emergency scenario
If for some reason everything will fail, or some hardware problems will occur, it is worth to have the possibility of spinning-off a replacement infrastructure on another machines. For automatic server configuration we have used Ansible tool, which is automatically issuing SSH commands based on the declarative configuration provided by the user.
In the inventory we defined what tasks should be ran on the particular servers and which ports should be exposed outside of Docker containers (designated by parameters port_out and bind). We also specified which services should be served by a reverse proxy (all ports marked with a web_port flag).
inventory/hosts.yml
In a playbook we have separated two roles – ctf_host for hosts on which some tasks should be ran and reverse_proxy for a host which should run nginx server in reverse proxy mode.
playbook/main.yml
A role of ctf_host is running particular CTF tasks through docker-compose and registering them as a systemd service.
playbook/roles/ctf_host/tasks/main.yml
playbook/roles/reverse_proxy/handlers/main.yml
The reverse_proxy role is generating nginx configuration for particular tasks, if the task contains ports designated with web_port flag.
playbook/roles/reverse_proxy/tasks/main.yml
Summary
In the article, we have shown basic concepts and problems related to organization of cyber security exercises in a form of Capture The Flag contest. We have described techniques of service deployment using Docker and isolation for high-risk services with usage of NsJail. Moreover, we have shown configuration of service monitoring using Icinga 2.
This article was created based on the joint knowledge of CERT Polska team, acquired during organization of ECSC 2018 qualifications and previous initiatives. We would like to remind you that both current contests co-organized by CERT Polska are available through hack.CERT.pl platform. Contests which were held in the past are still running there.
Artykuł Technical aspects of CTF contest organization pochodzi z serwisu CERT Polska.
Article Link: https://www.cert.pl/en/news/single/technical-aspects-of-ctf-contest-organization/