 Image source : https://unsplash.com/photos/sq5P00L7lXc by Hanson Lu
Image source : https://unsplash.com/photos/sq5P00L7lXc by Hanson Lu
A large catalog of products with millions of transactions makes it complex to understand what the best product combinations would be to offer a customer. To understand customer shopping behavior and provide curated products based on basket history, product recommendation plays an important role. Propensity-based models provide insights on co-buying products within Omni transactions(E-commerce: E-comm & store). Propensity to buy a product based on previous purchase history and basket analysis have multiple existing applications such as:
- E-commerce: generating recommendations and search capabilities within brand websites
- CRM: personalized email/direct mail marketing
- Supply chain: Demand forecasting, Assortment planning
- Promotions/Sales: Bundling products, packaging, promo offers
Problem statement
How do you discover what the right set of curated products for Walmart’s customer base are? Curated product recommendations lead to an increase in basket size and increase in revenue. But, can we scale curated product recommendation models for all departments, and find cross-buying opportunities? Building a scalable solution can be challenging in terms of complexity , changing real world datasets and memory consumption. The scalable product recommendation engine is a solution which needs to have a tradeoff between product combinations and complexity of solution. In this blog, we will be describing a transactions-based product recommendation engine we built using PySpark to overcome the challenge of complexity.
Modeling approach
For finding the right product recommendation sets , we divide the problem into 5 steps:
- Data fetch
- Preprocessing and filtering transactions
- Building product association model to find association rules
- Output validation
- Scaling solution for all departments
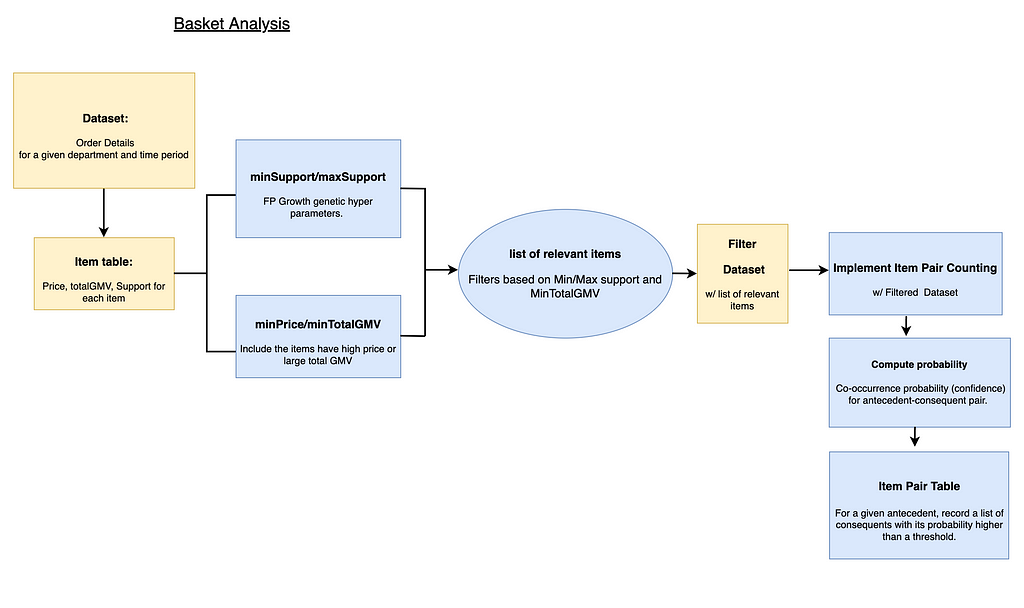 Modeling Framework( click to enlarge )
Modeling Framework( click to enlarge )- Data fetch
Ecomm has multiple divisons like Electronics Toys & Seasonal, Apparel, Food etc. Each division has its department which has category and subcategories related to it. We pull all the transactions data for each department within a fixed timeframe.
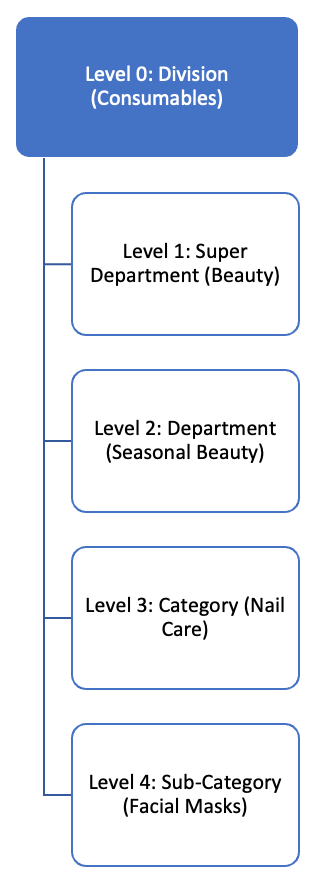 Reporting Hierarchy for Products in E-commerce
Reporting Hierarchy for Products in E-commerce2. Preprocessing-
Transactions contain products from different subcategories and each of these products have different price ranges and a specific customer base shopping for it. To minimize the bias while selecting product recommendations, we apply filters to select products to be included in the analysis.
The Filters are based on 3 key parameters
- Support
- Price
- GMV(Gross Merchandise Value) contribution
What is support, confidence and lift in product association Mining?
Support: defines how frequent an item-set is in all transactions
 Support
SupportConfidence: defines the likeliness of occurrence of consequent in the cart given that the cart already has the antecedents
 Confidence
ConfidenceLift: measures the performance of a an association rule at predicting a specific outcome, compared with a random choice.
Greater lift values indicate stronger associations.
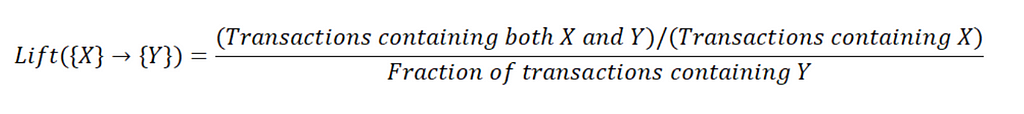 Lift
LiftWe start by filtering out non-relevant transactions which have single products.
Then minimum and maximum support is calculated based on the quantile range distribution to subset the transaction and products.
MinSupport helps in removing products which are rarely bought. Example: Golf accessories, Electric Knifes.
MaxSupport removes products commonly bought for daily purposes. Example: Cilantro, tomatoes.
Threshold is decided by the minimum price of a product and the GMV contributed by the product.
The original association rule findings only take into account the frequency of appearance. However, our objective for basket analysis is not only finding frequent items but also to increase the revenue/profit. Hence, we include the filters for price and GMV to include items like Treadmill and Television. Based on these filters, the final subset of products and transactions are selected for modeling.
3. Modeling
Two approaches have been utilized to solve the basket analysis:
A) FP Growth:
FP Growth generates frequent patterns from transactional data without candidate generation. PySpark ML distributed FP growth algorithm is used on top of preprocessed data to find frequent item pairings and product association rules tuned by MinSupport and MinConfidence parameters.
Support is calculated for each rule and analyzed based on the combination of support, confidence, lift. The evaluation performed using the 3 metrics helps in deciding which rules are significant for a set of product combinations from different sub-categories.
B) Probability based approach
Instead of using any product association model, we develop our own distributed probability based item pairing approach. In this method, we look at the baskets and calculate the probability of co-occurrence. The rules are selected from each sub-category level to provide varied recommendations from different product categories.
Example of recommendation: Product A belonging to category: Hair Conditioner will be recommended with Product B belonging to category: Hair Serum.
Overall, based on both approaches, the probability based approach was selected as the most efficient solution for all the departments based on 2 factors:
1. It only considers the relationship between two individual items, whereas associate rule mining (FPGrowth) considers multi-item relationships.
2. Since we exclude the multi-item relationship, the computation expense is reduced from O(n^n) to O(n), where n is the mean item count for a given basket.
4. Output validation
The rules generated from the selected model for a fixed time period are used for making decisions on product combinations to be offered together. Hundreds of thousands of rules get generated at each division level which are finally sorted to offer are the best product recommendation.
 Sample Product association rules
Sample Product association rulesOne month vs 3 month association rules validation results, we observe more unique query/antecedents and rules for 3 month as compared to 1 month :
 Rules stats
Rules stats5. Scaling
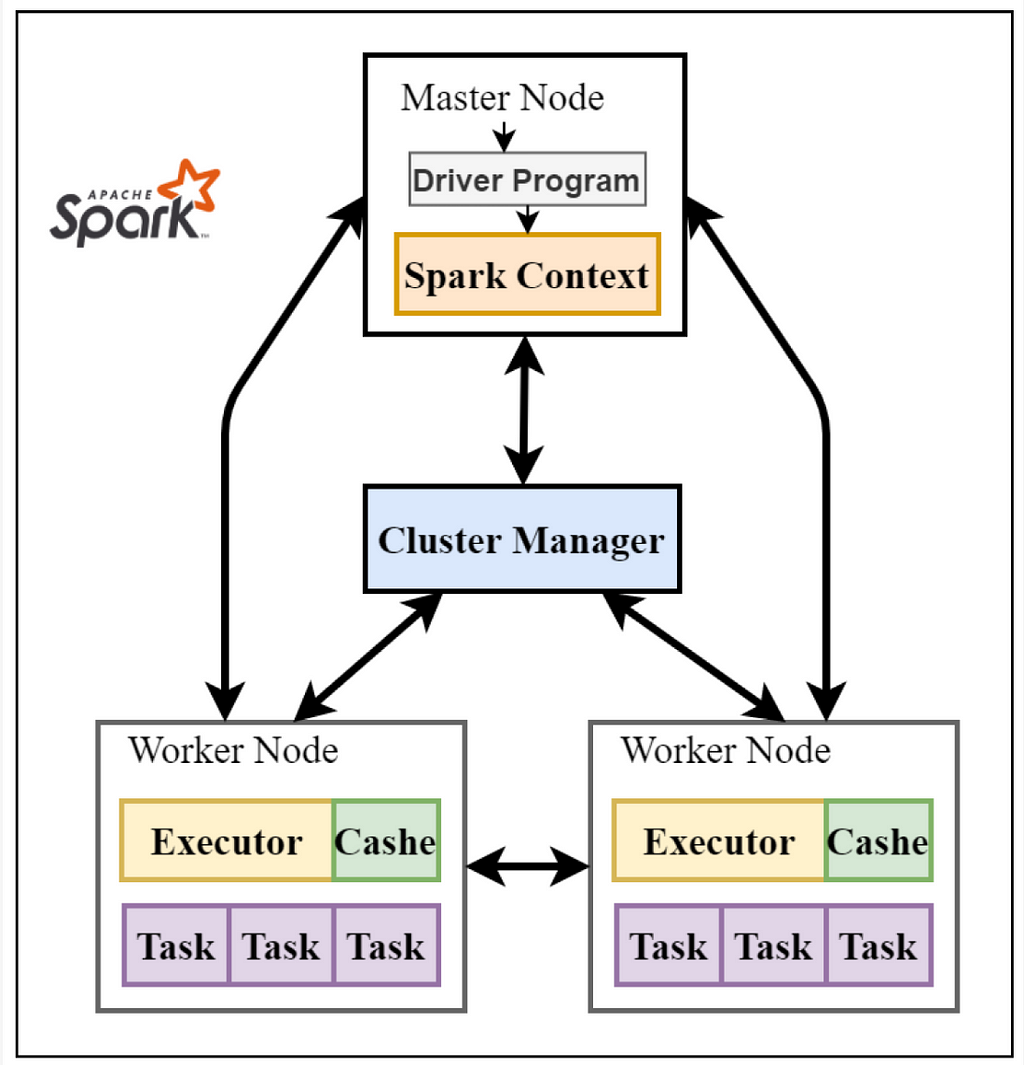 Overview of Spark framework. The master node contains driver program, which drives the application by creating Spark context object. Spark context object works with cluster manager to manage different jobs. Worker nodes job is to execute the tasks and return the results to Master node. Picture from https://www.mdpi.com/2076-3417/10/10/3382/htm
Overview of Spark framework. The master node contains driver program, which drives the application by creating Spark context object. Spark context object works with cluster manager to manage different jobs. Worker nodes job is to execute the tasks and return the results to Master node. Picture from https://www.mdpi.com/2076-3417/10/10/3382/htmTransactional data can have billions of transactions containing products from different subcategories. To understand the shopping behavior from these transactions is complex and most importantly a costly memory computation. To be able to analyze data on a large scale we use PySpark to enable distributed processing while running the jobs for multiple departments together. This makes the processing faster compared to running it at division level.
 Airflow workflow setup
Airflow workflow setupThe super departments are divided based on volume of transactions and catalog diversity. Airflow workflow is setup for all the divisions broken down based on sub-departments to process the basket analysis for a fixed timeframe. The results are computed in batches and merged to the master table which is clustered by super departments. Approximately the overall workflow execution takes around 6 hours to cover all the 4 steps of modeling.
Conclusion
Transactional based product recommendations generated a lot of useful product sets which are complementary and help in increasing basket size. This approach suffers from Cold-start problem however. To deal with a Cold-start problem of new products, we are extending a Transactional-based Product Recommendations with Product attribute-based approach. Stay tuned for Part 2 of the product recommendation. I sincerely hope this article will help those seeking to build scalable recommendation solutions . Please drop a comment if you have any suggestions.
Acknowledgement
Product recommendation using basket analysis is being used within Walmart Global Tech. This recommendation engine is co-developed with Junhwan Choi. Special thanks to Srujana Kaddevarmuth & Jonathan Sidhu for this initiative and support, Abin Abraham for the contribution & support, Data Venture team for helping throughout this effort.
Resources
https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.ml.fpm.FPGrowth.html
Scaling Product Recommendations using Basket Analysis- Part 1 was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Scaling Product Recommendations using Basket Analysis- Part 1 | by Apurva Sinha | Walmart Global Tech Blog | Medium