By: Evren Korpeoglu, Najmeh Forouzandehmehr, Nima Farrokhsiar and Quint Barr
 Figure 1 Example of Complete-the-look model output: various sets generated for the anchor item, the orange dress.
Figure 1 Example of Complete-the-look model output: various sets generated for the anchor item, the orange dress.1. Introduction
Modern industrial e-commerce platforms typically offer a wide variety of choices to users. The plethora of options often calls for recommendation systems that can guide users to discover the merchandise they seek effectively. This is especially critical for style-oriented categories like Fashion and Home. In such areas, customers have virtually unlimited options and rely on retailers and recommender systems to make it easy — and fun — to discover the ‘right’ collection of products to complete an outfit for a certain occasion or to complete a room for their home.
The goal of the Complete the Look (CTL) model is to address such a need in the Fashion and Home space: to develop a model that generates a complete, stylized outfit built around the current item the customer is considering on a given item page. To do this effectively — requires a model that not only finds the right product types (articles of clothing) that together construct a complete outfit — but also selects the right individual items that collectively complement one another from a style/brand/price/color and overall theme to create a coherent look.
The CTL model moves beyond more traditional similar or complementary-based recommendation models and helps to drive the following objectives:
- Improved discovery and awareness — CTL elevates the shopping experience, provides inspiration and makes it easy to discover diverse, complete, and stylized collection of products within and across product categories
- Improved confidence and conversion– seeing a style-aware, personalized look built around the item the customer is considering allows them to envision themselves in the outfit and increases their confidence in their purchase consideration
- Save time and get more– offering a more cohesive and convenient shopping experience — customers no longer have to shop for each individual component of an outfit and turning single-item journeys into more complete, multi-item baskets
At Walmart, we use multiple algorithms to generate and scale CTL recommendations. Among them, algorithmic look generation and look coverage expansion algorithms will be explained and elaborated on in this article. Section 2 is dedicated to algorithmic look generation. The look coverage expansion algorithm will be discussed in Section 3, which proceeds with conclusion in Section 4.
2. The Algorithmic Look Generation
“Complete the Look” is a style-focused concept where the goal is to help users put together an entire outfit, instead of just picking out a single piece of clothing. This can be a challenging task as it requires an understanding of what clothing items go well together and how they interact to create a cohesive, fashionable look. In this section, we will explore a model architecture that is used to generate complete looks, consisting of five major steps: candidate selection, look definition, look generation, outfit matching, and variant expansion as shown in Figure 2. Candidate selection is the first step, and it involves identifying clothing items that are suitable candidates for inclusion in an outfit. In the look definition step, a basic look is defined using a combination of clothing product types or groups of product types. Look generation step involves creating multiple outfits from the basic look defined in the previous step. This can be done by using complementary recommendations to guide the selection of items to create to the basic look. Outfit matching is the fourth step, and it involves enhancing the style of looks by evaluating the visual similarity between different items in outfits. The final step, variant expansion, is responsible for generating additional variations of the outfits created in the previous steps.
After deploying the model to the production environment, user interactions with the model are captured and fed back to the model to improve the model’s performance. The collected feedback is in the form of impressions of the CTL module on the item page, clicks, corresponding add-to-cart, and recommended item purchases. As these feedback signals are collected, they will be continuously utilized to improve the model as more users interact with the model.
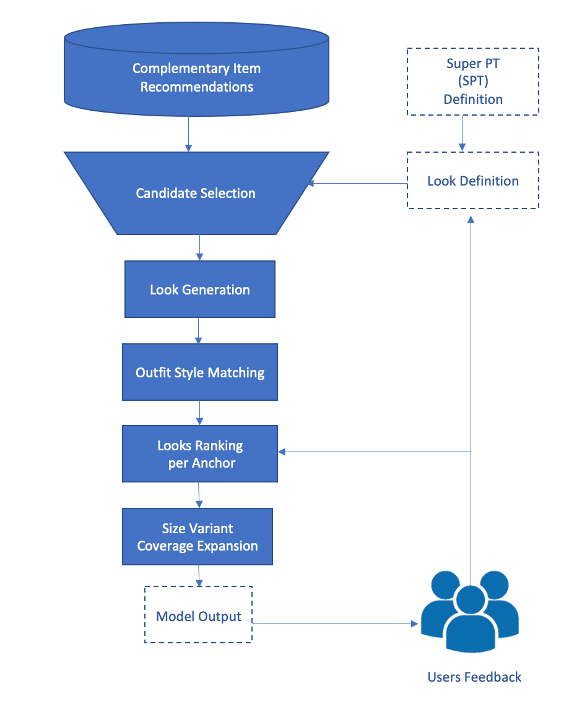 Figure 2 Look generation algorithm model architecture
Figure 2 Look generation algorithm model architecture2.1 Candidate selection
Candidate selection is the first step in creating meaningful looks, and it is essential to identify item groups that are complementary and compatible with each other. To create a look for each clothing anchor item, we leverage recommendations from our existing complementary item (CI) recommendations model. The CI model leverages various signals, including co-purchase, co-view, customer engagement, etc., to provide a multi-objective ranked complementary item list for every anchor item. We also leverage cold start complementary item recommendation models to expand the complementary item model coverage.
To ensure coherence of the final look, several filters are applied to the candidate set:
- Age/gender filters which are essential for making sure the recommended apparels are for the same age group and gender.
- Seasonal filter which provides appropriate candidate items for the current season
- Blacklist filter to remove inappropriate or controversial items from the candidate pool
2. 2 Look Generation
In the look generation step, we identify a set of looks for a given anchor. However, in order to generate these, we first need to define the look and identify its components. The definition of a look can be very subjective, but we make some assumptions to formulate and automate the look generation.
For our specific use case and the design constraints, we first need to define product types (PTs) which are hierarchical classifications of items. Some examples of product types are t-shirts, jeans, shorts, jackets, etc. In order to identify similar clothing groups, we add another layer of abstraction on top of existing PTs and combine PTs with similar functions into one class which we refer to as super product types (SPT). An example of a super PT can be the collection of PTs such as “Ponchos,” “Raincoats,” and “Rain Ponchos”. Defining super PTs has the benefits of having a more complete recall set coverage than that of individual PTs and significantly lowering the combination of PTs to form different looks.
Finally, we define a look as a combination of items from 4 to 5 distinct SPTs. The collections of SPTs that form a look are determined using the unique combination of clothing that most people wear. An example of a look is shown in the image below:
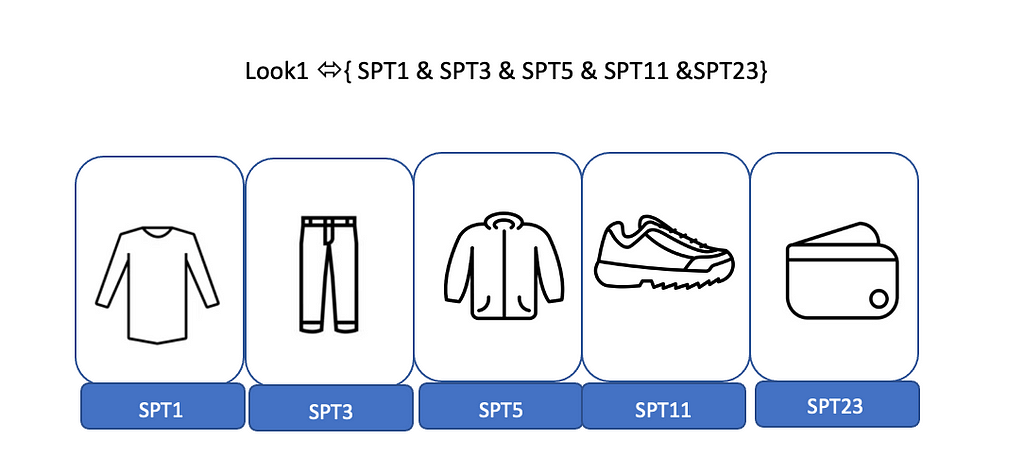 Figure 3 Schematic of the look definition as a set of SPTs
Figure 3 Schematic of the look definition as a set of SPTsLook definition also leverages the feedback signals from the model engagement as well. User feedback acts as a tool to adjust the looks that receive relatively few positive customer interactions. This would indicate that if the proposed collection of items does not generate enough engagement for anchors within a certain PT, the recommended PT would get a lower ranking within its SPT or will be completely removed.
Once we define the components of a look, the recommendations that form a basic look are generated by filtering the combined candidate set of multiple existing complementary recommendation models on the component PTs that belong to the same SPT group. For example, for a shirt as an anchor, if the look definition consists of pants, jackets, sneakers and wallets, the complementary recommendations are used to select items from this anchor’s candidate complementary recommendations to complete the outfit. For each SPT, multiple items can be selected and included in the raw look, and these items are ranked per each SPT in the outfit matching step based on style item embedding similarity score. In cases where no item is available for a specific SPT included in a look definition, we use style embedding, which is explained in the next section, to find matching items from that SPT.
2.3 Outfit Style Matching
To further improve the style compatibility and visual coherence of created looks from the last step, we explored several supervised learning approaches to learn complementary relationships beyond co-purchase and contextual similarity which are mainly used by complementary item recommendation models. For outfit matching, items are primarily selected based on visual coherence and consistency. To consider outfits’ visual coherence, we trained item style embeddings using triplet learning [1] which is performed by training a model to take in a triplet of items as input, consisting of an anchor item, a positive item (i.e., an item that is style-wise compatible with the anchor item), and a negative item (i.e., an item that is incompatible to the anchor item). The model is then trained to output a high score for the positive item and a low score for the negative item relative to the anchor item. We used CLIP [2] image embedding of items as input and selected a feed-forward network with triplet loss to train item-style embeddings.
 Figure 4 Example of the style matching score triplet item selection
Figure 4 Example of the style matching score triplet item selectionTo create triplets for training style embeddings using triplet learning, we use a dataset of outfits curated by merchants as well as the customer engagement data such as clicks and add-to-carts from the complete the look module. The triplets are generated by selecting a reference item from one of the outfits and selecting a positive item from the same outfit, and a negative item from a different outfit. This process is repeated for each outfit in the dataset to create a large number of triplets. Once we have selected item candidates and defined the outfits using a combination of clothing items, we use the style embeddings to further refine an outfit by selecting items that are visually similar in the embedding space.
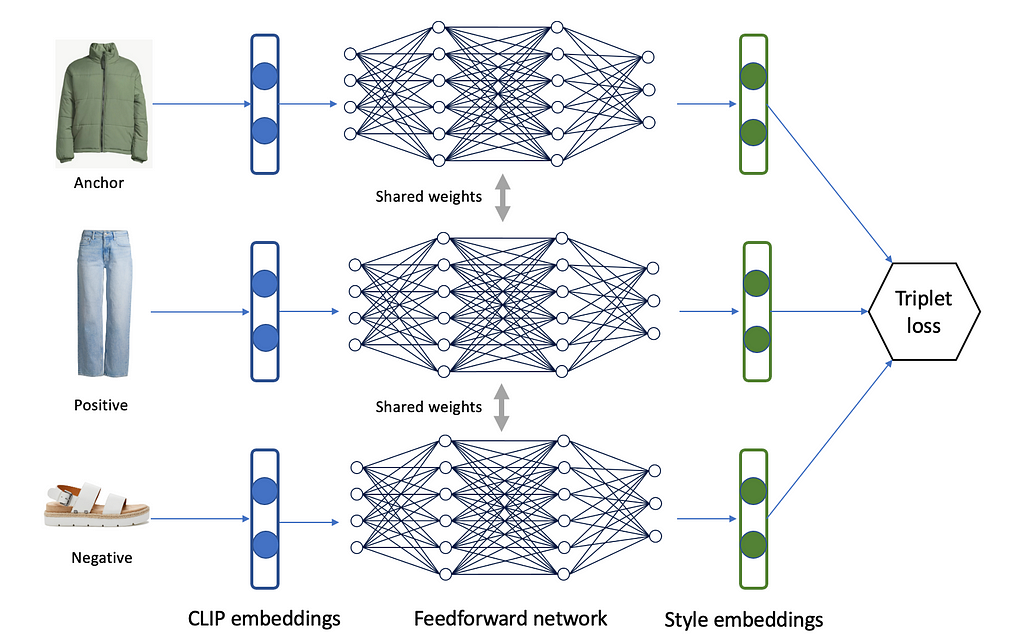 Figure 5 Triplet learning network architecture
Figure 5 Triplet learning network architectureOne of the challenges in generating item image embeddings to represent useful clothing features is finding the right product images. One potential issue is that the image may contain variations in the background color which may not be relevant to the clothing item but could still be learned by the model. Additionally, images cluttered with other clothing items may not be suitable for image embedding training. To address these issues, we created a model that can automatically identify “laid-down” images that are not worn by any human model or accompany other pieces of clothing. This was accomplished through a 2-step pipeline that first identifies apparel images with human limbs and, secondly, a classifier to score and select the best images where no human is present.
In the following Figure, we can see the output of the product image selection algorithm. This product has five images, and the leftmost image is the primary product image; however, our image selection algorithm picked the middle image (3rd image) to be displayed within the CTL model.
 Figure 6 Example of image selection algorithm. The image in the middle is selected as the main image
Figure 6 Example of image selection algorithm. The image in the middle is selected as the main imageNext, we implement a look permutation step which aims to increase the coverage of the model. For instance, if we build a look for a t-shirt that includes a pair of jeans, we can have the same look when that pair of jeans is the anchor item, and the t-shirt becomes part of the recommendations. We do this permutation for all major apparel categories, including upper-body and lower-body apparel, but not for shoes and other accessories.
2.4 Look Ranking
Finally, we need to rank the looks created for a given anchor item based on how well they match the anchor item and each other. A weighted combination of price proximity, brand affinity, and color compatibility scores is used to produce a final ranking score for each look. The weights are adjusted based on user interactions with displayed outfits. Once the looks are generated, we apply a size/variant expansion step to ensure all sizes of the same anchor item have the same look available for them.
After ranking looks for each item, since each item is associated with a specific anchor size, we want to expand the same look to all available sizes of the anchor clothing item. We find all variants of the anchor item with the same color and assign the anchor item ranked looks. This step significantly expands the coverage expansion of the CTL model.
3. Expanding Look Coverage
In Walmart, a style look can be generated with other methods as well. The algorithmic generation, as was discussed in the previous sections, is only one way that the recommender relies upon prior interactions and past style ideas. Merchants and stylists are a great source of forward-looking style creation yet to be matched by any ML-based generation algorithm. As much as humans are great at generating new previously unseen styles, they cannot provide them at the scale required to cover Walmart’s catalog. To address this gap, we developed a search-and-refine algorithm to expand the limited number of human-created styles to the entire Walmart’s clothing and accessory items. An example of such an expansion is shown in Figure 7 below. CTL recommendation set developed for a black dress, can be leveraged for tens of other black dresses that look similar.
 Figure 7 An example of replacing the anchor using visual search. The anchor can be replaced by a new dress using the visual search.
Figure 7 An example of replacing the anchor using visual search. The anchor can be replaced by a new dress using the visual search.The recommender can use a similar procedure to replace all the items in the original look. For every item with a particular human-made look, recommender systems might find hundreds of visually similar items using the visual search. The combinatorial combination of these new items expands the original look to a massive number of sets. However, only some of the new looks are coherent sets. Since the visual search relies only on the appearance of the items, the newly derived sets might be composed of visually compatible but otherwise non-compatible items. The refining step tries to eliminate or modify the internally non-compatible sets. Typical additional attributes required for apparel compatibility include the size, age, and gender of each item. One appeal of this method is it can quickly be applied to new areas such as home and office furniture with slight modification in the refining step.
The summary of the various steps of the search-and-refine algorithm is shown in Figure 8 below. The visual search is an embedding-based search in which item images are mapped to an embedding using a pre-trained model, in our case, CLIP [2]. An approximate Nearest Neighbor methods such as Faiss [3] or ScaNN [4] is utilized to find the similar images in the embedding space. The modify-and-eliminate step is domain dependent: a queen bed should match a queen mattress, and adult pants cannot be part of a kid’s look.
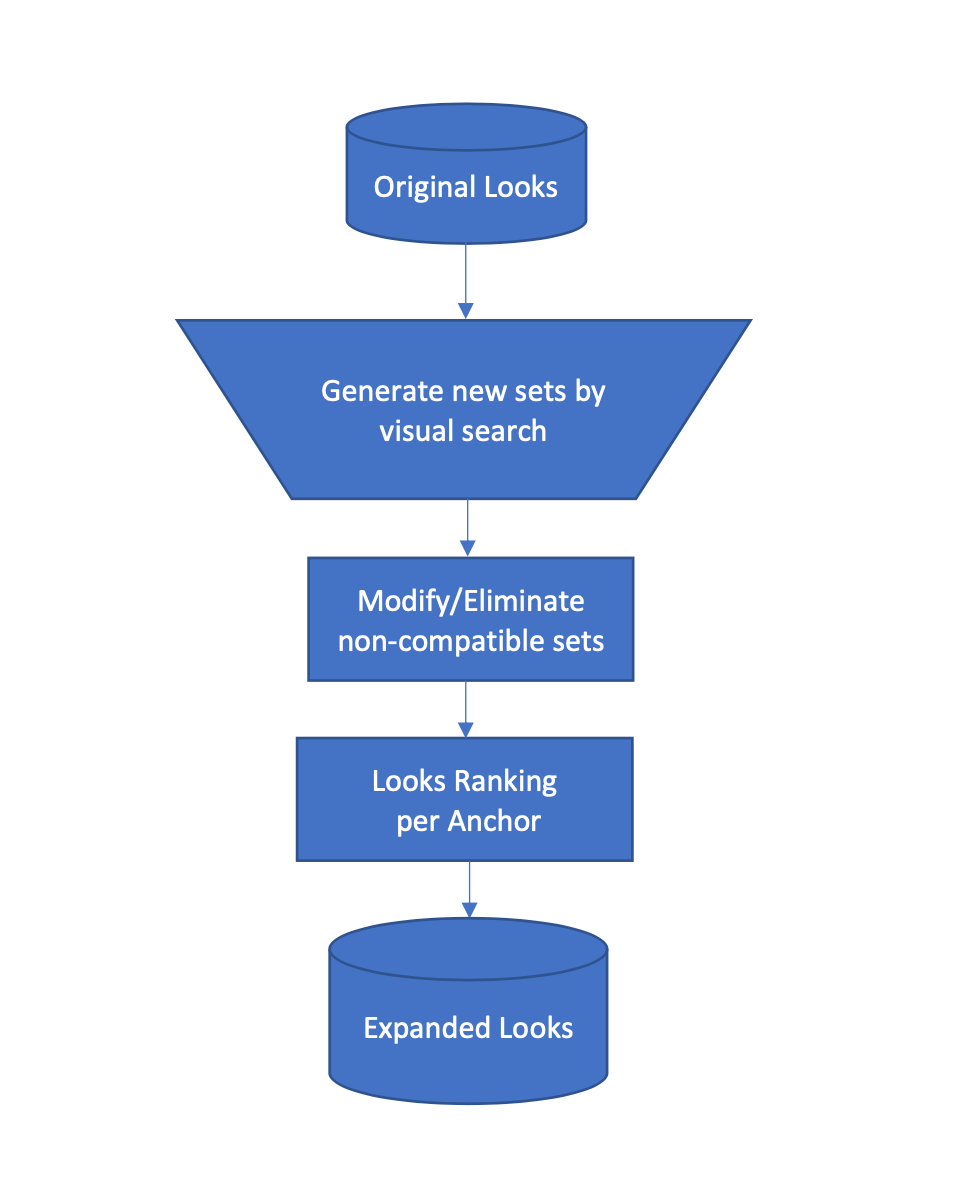 Figure 8 Summary of the look expansion algorithm
Figure 8 Summary of the look expansion algorithm4. Conclusion
In conclusion, creating complete looks is a challenging task that requires an understanding of what items go well together and how they interact to create a cohesive outlook. CTL model goes beyond traditional similar or complementary-based recommendation models and helps to improve the discovery and awareness of products, increase customer confidence in their purchase consideration, and provide a more cohesive and convenient shopping experience. It uses multiple algorithms, including algorithmic look generation and look coverage expansion algorithms, which were explained and elaborated on in this article. This model has the potential to greatly enhance the customer experience in the fashion and home departments.
References
[1] https://arxiv.org/pdf/1503.03832.pdf
[2] https://arxiv.org/abs/2103.00020
[3] https://github.com/facebookresearch/faiss
[4] https://github.com/google-research/google-research/tree/master/scann
[5] https://arxiv.org/pdf/2104.13921v3.pdf
[6] https://arxiv.org/pdf/2207.03482v3.pdf
Personalized ‘Complete the Look’ model was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Personalized ‘Complete the Look’ model | by Najmeh Forouzandehmehr | Walmart Global Tech Blog | Jan, 2023 | Medium