 Photo credit: geralt
Photo credit: geralt
Building high-performance REST APIs for serving large payloads is no easy task. As companies have increased their focus on faster service-level agreements (SLAs) with minimal resource usage, several new data compression and serialization algorithms have been developed in the past few decades.
In the Rollups team at Walmart, we aggregate data from various sources and serve extremely large JSON payloads to Walmart’s search and item pages. With payloads that are sometimes several megabytes (MB) large, an efficient serialization mechanism is vital to reducing network roundtrip times.
Rollups System Overview
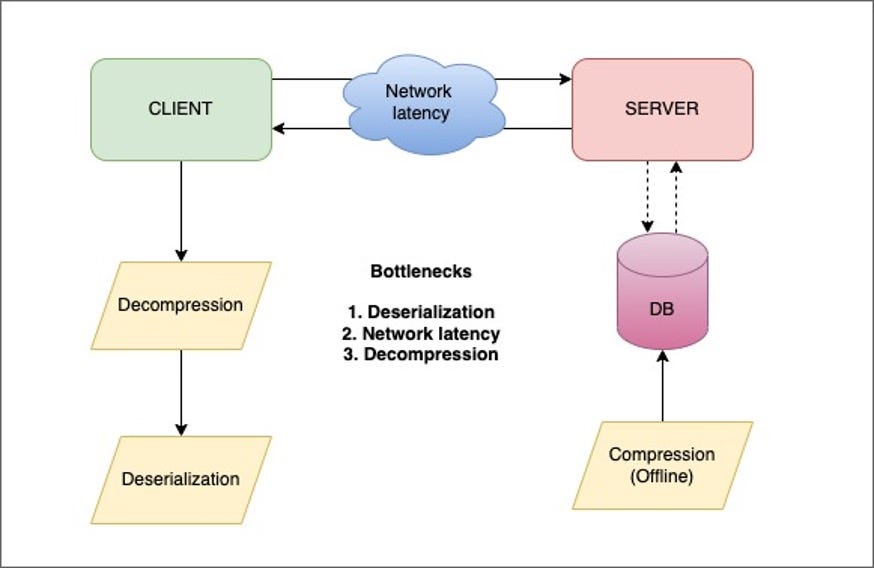
- Rollups is a Kafka consumer application that listens to various Kafka topics and aggregates different pieces of information about items sold at Walmart.
- The item payloads are aggregated offline as a large JSON string and compressed using the ZSTD algorithm. The compressed bytes are stored in a Cassandra database.
- When a customer performs a search on Walmart.com, a live call is made to the search backend service, which fetches the compressed bytes from the Rollups Read service through an orchestrator.
- The orchestrator (our client) decompresses and deserializes the payload using the Rollups library locally.
The requests from the search backend are bulk item requests that can result in an overall payload size of up to 3 MB. Deserializing these large payloads can create a huge bottleneck, which results in increased latencies for heavy item requests. The local Rollups library uses Jackson’s fasterxml mapper to deserialize the payload. Although we achieved an improvement of 5% with the Jackson afterburner module and some custom Jackson properties, we needed a way to reduce overall latencies to meet the SLAs for the service calls. JSON was not a viable option, so we began exploring alternative serialization formats.
 Architecture and bottlenecks
Architecture and bottlenecksThis article assesses the pros and cons of three popular serialization formats: JSON, Protocol Buffers (Protobuf), and Flatbuffers. We ran several benchmarking tests and compared the three formats based on code complexity, ease of maintenance, semantics, decompression time, deserialization time, network time and CPU, and memory usage.
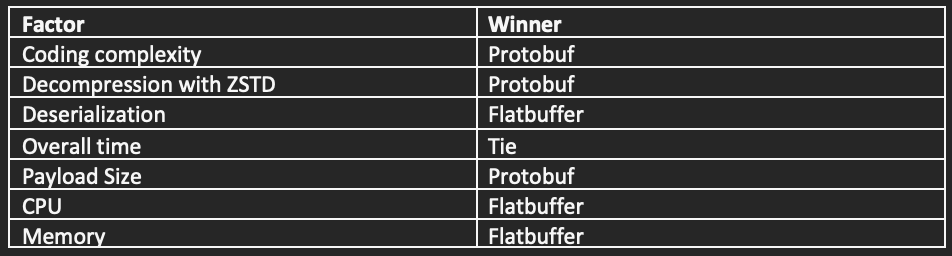
The table below shows the winning algorithms based on different factors. These results are specific to our schema definitions and can’t be generalized for other use cases.
Schema
Let’s compare the schema definitions for Protobuf and Flatbuffers.
 Protobuf vs. Flatbuffer Schema
Protobuf vs. Flatbuffer SchemaIn the Protobuf schema, every property has a data type and field number. Most of the standard data types are supported, including maps, lists, and timestamps. There are some great online tools for proto schema generation, which will speed up development. Although these tools don’t achieve a perfect conversion, they provide a good baseline to work with.
Protobuf also provides some special types, such as oneof, Any, and wrappers. It is important to note that default values are assigned to all unset fields. This might lead to issues in situations where the client needs to differentiate between a null value and a default. The wrapper types (wrappers.proto) can be considered to get around this issue.
The Flatbuffer schema also consists of a set of properties enclosed in a “table.” Unlike Protobuf, there are no field numbers. Because of this, the order of properties in the schema needs to be preserved. New fields should always be added at the end. This schema also supports most of the standard data types. Flatbuffers allow for optional types that won’t take up any space on the wire, if not set, and won’t have a default value.
Serialization
Protobuf uses the “protoc” compiler to generate code for the given schema, which can then be used to build the protobuf object. Varint encoding is used for the data type, field number, and delimited field lengths. Smaller integers take up less space on the wire with varint encoding. For example, the number “11” will take up one byte with varint encoding, but two bytes in a JSON string. It is important to determine the right data type for properties in the schema. Larger integers may do better with fixed-length encoding. For strings, standard UTF-8 encoding is used. If the schema has a simple structure and contains mostly strings, JSON may perform better than Protobuf.
Flatbuffers flatten the entire payload object such that every property is stored at a specific offset location relative to the start of the buffer. A Flatbuffer object has three parts: the vtable, pivot, and data block. Consider the schema diagram above for Flatbuffers.
In our example, the payload is a single instance of “Person.” This instance will have a pivot point. To the left of the pivot point, a list of offsets is stored. This is called a “vtable.” The vtable for “Person” has three offset values, one for each of the three attributes in the table. They will be stored in the same order as the fields defined in the schema file. To the right of the pivot point, the actual values will be stored. If the attribute value is another complex object type, then the child object’s pivot point will be stored at that offset location. For example, the offset of “1” in the first position of Person’s vtable indicates the first field value is stored one position to the right of the pivot point.
The table below is an abstract representation of what a serialized Flatbuffer may look like in memory. Think of the table as a single dimensional structure with each row being a continuation of the previous row.

Do We Still Need ZSTD Compression When Using Protobuf/Flatbuffers?
Protobuf achieves good compression ratios through varint encoding. It might not be necessary to add an extra layer of compression in most cases. However, to arrive at a payload size equivalent to the compressed JSON payload size, we applied ZSTD compression to the Protobuf object.
Interestingly, ZSTD didn’t work as well on the Flatbuffer object. This is likely because of the large offset values in the serialized object, which are very difficult to compress. The compressed Flatbuffer was almost 63% larger than the compressed JSON size. Before we ran the benchmarking tests, we hoped the savings on deserialization time would make up for the increased size.
Benchmarking Results
A sample set of 20 products were used to perform load testing for all three data formats in production. Walmart’s Omniperf platform was used to run the tests at scale. The tests were executed over a 10-minute duration and resulted in a total of up to 41,000 requests for each of the formats.
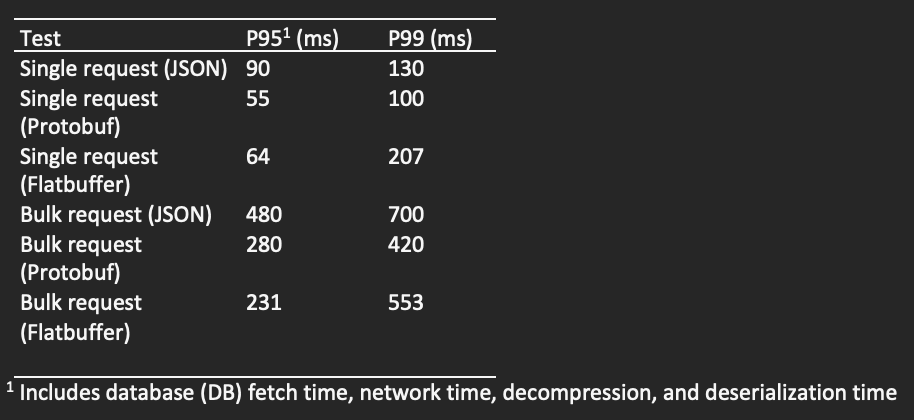
These results indicate that Flatbuffers performed slightly better than Protobuf as the payload size increased. However, only a small percentage of Walmart customer traffic contains heavy bulk requests that exceed a few MB in size. Therefore, Protobuf seems to have a slight edge for the average use case.
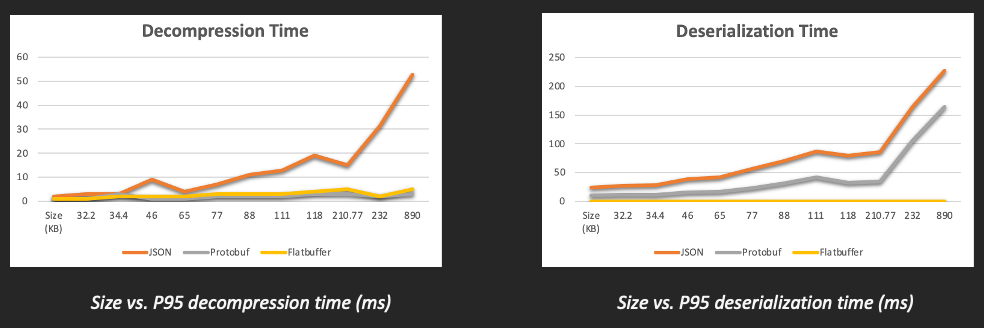
It is even more interesting to examine the decompression and deserialization times for each of these formats. Protobuf provides up to 56% improvement in deserialization time for smaller payloads (up to 230 KB), then gradually starts degrading in performance, as shown in the graphs above. However, it is still 32% better than JSON for large payload use cases. Flatbuffer objects, on the other hand, don’t need to undergo any deserialization. They just require a small unpacking step to ensure the payload is ready for traversal. This takes less than 1 millisecond (ms) in most cases.
In terms of decompression times, both Protobuf and Flatbuffers show a massive improvement over JSON.
Flatbuffers use less CPU and memory than Protobuf. This is expected due to its zero-copy serialization format. For applications that are sensitive to CPU and memory, Flatbuffers may be a better choice.
Related Work
Protobuf provides great benefits when using HTTP 1 with REST, but it is more widely adopted with Google Remote Procedure Call (gRPC), which uses HTTP 2 with header compression and Transmission Control Protocol (TCP) connection reuse. We plan to run some tests with gRPC and Protobuf in the near future.
Conclusion
Both Flatbuffers and Protobuf resulted in similar results for the overall P95 processing time, so our decision was based purely on coding complexity and ease of maintenance.
Flatbuffers require offsets to be created explicitly in the code. This is very cumbersome to maintain and highly error prone. Protobuf has the same getter/setter semantics as plain old Java objects (POJOs) and seems like a safer and easier option to use for the long term. It also has better community support and open-source libraries that can be plugged in seamlessly. Thus, Protobuf with ZSTD compression became our final choice.
Optimizing API Performance with ZSTD Compression and Protocol Buffers was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.