When optimizing machine learning (ML) models, model performance often is prioritized over model interpretability. However, in the field of information security interpretability is a sought after feature, especially in the realm of malware classification. By understanding why a model classifies a binary as benign or malicious, security practitioners are better equipped to remediate an alert.
We worked with the ember benchmark model, a classifier that is currently not interpretable, to design a measure of interpretability that will determine which features contribute to the model’s predictions. This enables future ember users to quickly interpret and explain their findings, highlighting the value of focusing on both performance and interpretability in ML models.
Methods for Model Interpretability
There are many ways to approach model interpretability, including partial dependence plots (PDP), local interpretable model-agnostic explanations (LIME), and Shapley values.
The Shapley values method, which quantifies how much each model feature contributes to the model’s prediction, is the only one that can determine each feature effect on a global scale and thus give a full model explanation. For this reason we chose to use SHapley Additive exPlanation (SHAP) Values, an extension of the Shapley values method, to assess interpretability for the ember benchmark model. For a given model, all the SHAP values are summed to get the overall difference in model prediction in comparison to the baseline prediction without considering feature effect. The SHAP paper is available here and the open source code we utilized is available here.
It is important to note how SHAP values are correlated to file classification. When interpreting malware classification models, lower SHAP values push the model towards classifying a file as benign, whereas higher SHAP values push the model towards classifying a file as malicious.
Applying SHAP for Model Interpretability
We applied SHAP value-based interpretability to the ember model in two ways: model summary and single file. Each of these are discussed below.
Model Summary
The ember dataset consists of raw features extracted from over one million files/samples that are used as training/test sets for the ember model. Each file’s raw features are converted into 2351 vectorized features. By creating a SHAP summary plot for the model, we were able to determine the 20 features (out of 2351) that affected the model the most and how changes in these values affect the model’s prediction.
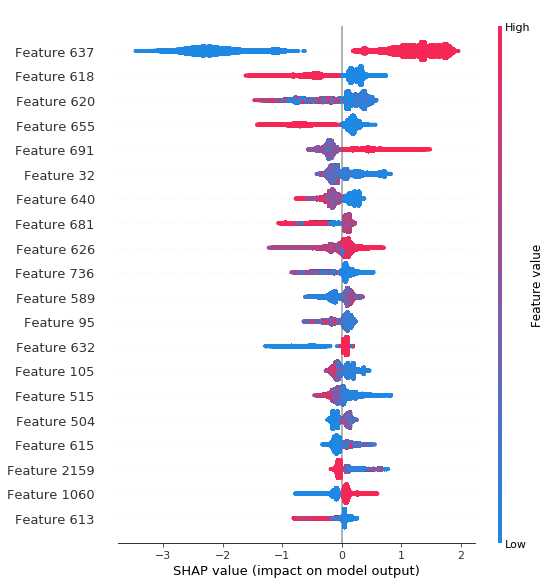
Figure 1: A summary for all the files/samples in the ember dataset of the correlation between feature values and SHAP values
This plot shows how high and low feature values are related to SHAP value. For example, Feature 637 (machine type) is the most important model feature because high and low feature values directly correlate to high and low SHAP values. In comparison, other model features are less important because there is less distinction between high and low features values and their resulting SHAP values are closer to zero. This can be seen with Feature 504 (byte entropy histogram), as its corresponding SHAP values are closer to zero and thus has less impact on the model. We were able to use this plot to get a better understanding of how certain features affected the ember model decision.
Single File
While understanding features’ effects on the model is important, ideally we want to provide a file and identify how the features in that file specifically influence the model’s prediction.
Within the ember dataset, each file’s raw features are already converted into 2351 vectorized features and categorized into eight feature groups (Byte Histogram, Byte Entropy Histogram, String Extractor, General File Info, Header File Info, Section Info, Imports Info, and Exports Info).
It would be possible to visualize how each of these 2351 features contributes to the model; however, we determined that the visualization would be too cluttered for a user to extract any meaningful information. Instead, it would be more informative to understand how each feature group contributed to the final prediction so that the user would know what part of the file to scrutinize more.
We added together the SHAP values for all the features in each feature group to get an overall SHAP value for each group, and then created a force plot (see example below) to visualize each feature group’s overall effect on the model’s prediction.

Figure 2: Most of the eight feature groups in this specific file push the model towards classifying the file as malicious (red)
In addition to feature group importance, we also provide a list of the top five features in the file that contribute to the prediction the most, as well that feature’s information. An example can be seen here:
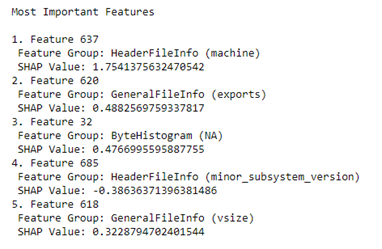
While we can say which features contributed most to the model’s prediction and what groups/subgroups they are in, the next step would be to identify what exactly that feature represents. For example, from the visual above, we can say that Feature 620 is a part of the General File Information, specifically the exports section, but ideally, we would be able to determine exactly which export contributes to how the file is classified.
Conclusion
With the possible extensions mentioned above, we now have a measure of model interpretability for the ember model that will help us better understand why it classifies certain files as benign or malicious. Ideally, this interpretability feature could be implemented for other classifiers so that researchers in information security can quickly identify and respond to a security alert.
As shown through the ember model, interpretability provides more detailed insights about ML models. These insights will allow researchers to move past current ML black box predictions, thus highlighting the importance of model interpretability and transparency within ML models.
Article Link: https://www.endgame.com/blog/technical-blog/opening-machine-learning-black-box-model-interpretability