
Walmart systems produce one of the largest and most diverse datasets in the world growing at 10’s of Petabytes of data per day. From many disparate sources and their supporting backend systems, a series of high-volume streams of business events are emitted into our messaging layer primarily backed by Apache Kafka.
Walmart teams have a strong desire to expand near real-time decision making as seen with a significant increase in event driven architectures, change data capture (CDC) from production databases, ML and computer vision services all of which have resulted in exceptionally large tables with new query patterns. Efficiently storing these events for further aggregations, reporting, analytics, and machine learning across our many businesses domain (e.g., supply chain, customer, inventory, search, etc…) is challenging due to a complex topology, the velocity of the events, data variety, and rapidly changing schemas.
It is with these challenges in mind that Walmart has begun to evolve our Data Lake(s) from batch-oriented architectures to a modern Lakehouse approach by seeking a common framework to provide near real-time data with warehouse like semantics (strong typing, transactional guarantees, and ACID compliance) and improving query efficiency through caching, columnar statistics, data partitioning, compaction, clustering, and ordering.
The guidance and direction chosen will have significant impact for many years, due to the substantial cost to migrate data from one format to another both computational and developer time. To reduce all future known and unknown risks, it is critical that Walmart maintains total control of all aspects of the format and runtimes supported, ensuring the flexibility to maintain, patch, upgrade and extend the framework as needed while running across Walmart and public clouds and all query acceleration layers within our ecosystem. This led us towards only selecting open-source formats ensuring that Walmart can maintain and contribute towards.
Our teams have evaluated the current industry standards for modern Lakehouse architecture based on:
· Ingestion / query performance of two critical Walmart real world workloads within our multi-cloud environment. WL1 (Workload 1) unbounded time partitioned data with significant fanout due to late arriving data, < 0.1% Updates, > 99.9% Inserts and WL2 (Workload 2) mostly bounded cardinality with unpartitioned data writes were > 99.999% Updates, < 0.001% inserts.
· Architectural reviews of the underlying design choices and subtle tradeoffs.
· Discussions with industry experts and technical leadership within other fortune 500 companies.
From this work a weighted score matrix was created considering system characteristics or “Illities”:
· Availability [3], recoverability, and portability
· Compatibility [3] with different versions of Spark, execution and query engines
· Cost [3] per unit of work on Walmart real-world datasets
· Performance [2] of ingestion, query , tunability, sane defaults, level of effort to migrate any existing data
· Roadmap [2] for product development and Walmart’s ability to contribute and influence
· Support [2], Stability of product, documentation, and deployment controls
· TCO [3] (Total Cost of Ownership) based on job cost and internal management factors
For brevity we’ve included highlights from our internal investigation into open-source data lake formats like Apache Hudi, Open-Source Delta, and Apache Iceberg (compatibility, performance, and overall thoughts).
Compatibility
Winner: Apache Hudi
Schema evolution and validation
Walmart today has a tremendous overhead in managing the overall number of data pipelines needed to empower our business. This is further compounded by schema management complexities from the thousands of application changes needed to modernize and evolve our business. Understanding and managing the compatibility of these schema changes is critical in building a robust Lakehouse. Furthermore, it’s critical that invalid schema evolutions in our Lakehouse are resolved quickly and where possible, at the source.
Lakehouse platforms enforce schemas at write alleviating any read compatibility issues, thereby avoiding placing the onus of discovering and reporting an error on the consuming systems. Additionally, if large amounts of data were written before a reader discovers a fault, it may cause data loss and/or a costly and time-consuming recovery. By validating schemas on write, Hudi, Delta and Iceberg remove most of the data incompatibility issues, but Lakehouse writers still need to deal with invalid and unmappable schemas from upstream data sources. Many of these upstream schema issues cannot be solved through any of these Lakehouse formats and need to be addressed holistically via flexible schema management or strong enforcement of schema evolution rules on upstream sources.
Iceberg’s approach to schema evolution is the most flexible, allowing for the greatest cross section of potential upstream schema formats, supporting most valid schema evolution scenarios in Protocol Buffers, Avro and Thrift. Hudi and Delta support Avro compatible evolution, but lack column rename capabilities, which is a supported schema evolution for binary representation of Protocol Buffers and Thrift messages. This requires that Walmart enforce restrictions on those types of pipelines if they feed into our Lakehouse. When working with streaming data, the schema changes have to be dealt without downtimes to our pipelines and queries, which rules out allowing any such breaking backwards incompatible changes anyway.
Validating schema on write to upstream data sources helps to alleviate the problem, however with a significant portion of streaming data in Walmart being “schema in code” with JSON encoding, the path to migrate to a contract-based data interchange format will be long. With the likelihood of unsupported schema changes, a large investment in strong operations (tooling and monitoring), along with educating data owners, and a longer-term investment into mandating upstream, Walmart’s sources adhere to non- breaking schema changes governed via a global schema registry.
 Schema Evolution Compatibility
Schema Evolution CompatibilityAll Lakehouse table formats support backwards compatibility only, for the same reason, to reserve the right to allow for breaking changes in the future. Table format schema changes are infrequent, but readers may need to upgrade before the tables are migrated.
Engine support
Walmart data is queried with a variety of engines: Hive and Spark, Presto / Trino, BigQuery, and Flink. Native reader / writer support for all these engines is important to reduce the change required for existing customers to migrate to the new Lakehouse. This table lists the degree an engine is used at Walmart and the support for that engine for each product.
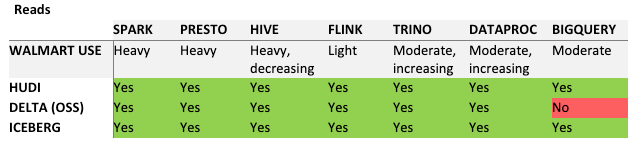 Engine Compatibility (Read)
Engine Compatibility (Read)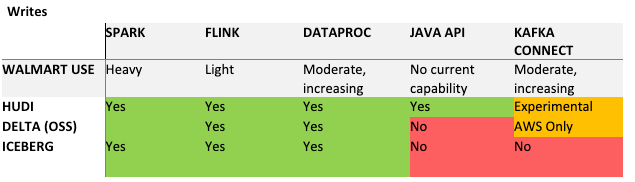 Engine Compatibility (Write)
Engine Compatibility (Write)Architecture and Design
Improvements in performance are the primary reason Walmart has embarked on investigating a change in table format. Hudi, Delta and Iceberg are all performance focused, and while there are differences to each systems approach as noted in the table below, their features can be grouped into concurrency, statistics, indexes, colocation, and reorganization.
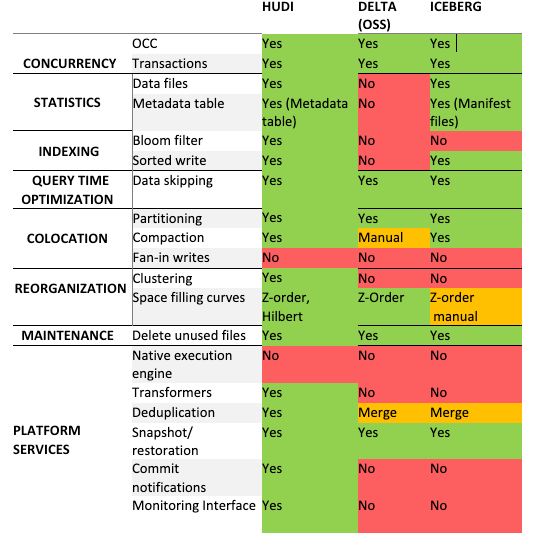 Framework Features
Framework FeaturesPerformance
Winner: Apache Hudi
Ingestion performance
Batch and streaming ingestion benchmarking was performed on two real-world workloads that struggle to meet business latency SLAs. These two critical internal workloads were dubbed WL1 and WL2. WL1 (batch) is a typical time-based table partitioned by year, month, day, hour and suffers from significant late arriving records causing Spark ingestion to suffer significant read/write amplification across many partitions. WL2 (streaming) without partitioning maintains row level upserts to a bounded data set with low latency data being projected via change data capture from a multi-TB Cassandra table.
WL2 Pattern has become a critical pattern for Walmart to maintain business desires for lower latency data lake tables over bounded operational datasets.
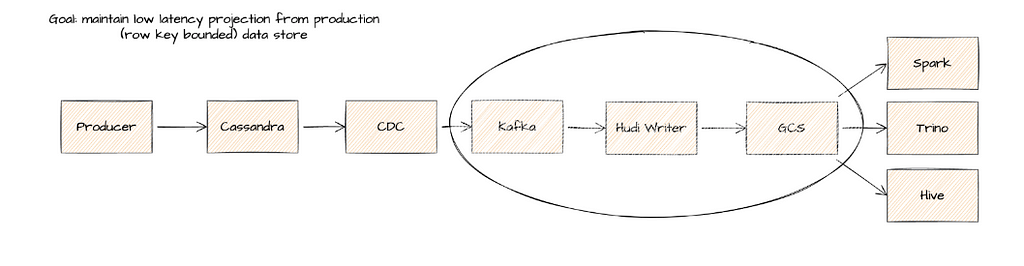
For testing completely isolated environments were constructed for all tests to avoid any chance of noisy neighbors. Then each ingestion job (Delta, Hudi, Iceberg, Legacy) were deployed and allowed sufficient time to reach a steady state. The Median batch ingestion time were measured over a reasonable set of batches (n > 30) and normalized across total cores of ingestion to determine a weighted score [time * GB-ingested] / cores (lowest score is best). When compactions were executed, a similar metric to standard ingestion was calculated by isolating the compaction via asynchronous execution with an external Spark application or internally as inline (blocking) and measured from the compaction stage.
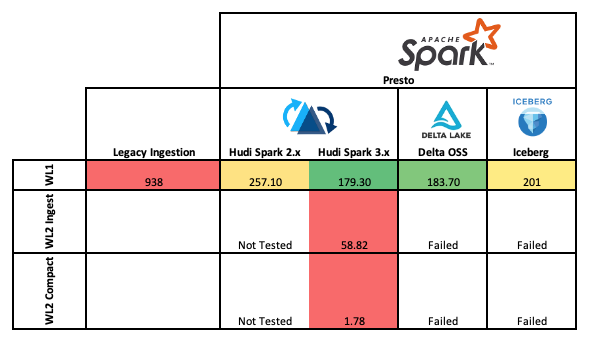 Ingestion Benchmark Scores (GB-ingested * Time [min]) / Cores
Ingestion Benchmark Scores (GB-ingested * Time [min]) / CoresThe results for WL1 noted dramatically improved ingestion performance over the existing ORC processing pipeline with over 5X speedup in performance, and the most performant was Hudi running on Spark 3.x. For WL2 streaming ingestion performance was 27% faster on Delta, however compaction for Hudi was dramatically faster as the application on performed compaction and lacked the ZOrdering performed in the Delta pipeline (at the time of testing Hudi did not yet support asynchronous ordering). This additional efficiency gave the query performance in Delta dramatically improved query performance.
Delta WL2 Pattern — Ingestion difficulties
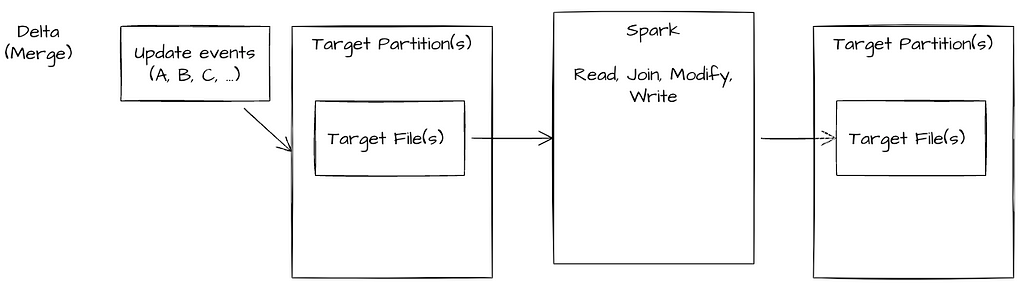
Ingestion Job — consists of a global shuffle of target partition files and records to be processed — 150 Cores (6+ hours and didn’t finish)
Reader has clean compacted view of data (no need to merge logs for realtime view) however the merge becomes more costly with growing cardinality
Due to the cost of a global shuffle and the growing data sizes the Delta writer was not able to process the data effectively. We attempted an alternate architecture to append the data to the table and run a background (async — non blocking compaction) however Delta’s architecture prevented these operations from completing successfully.
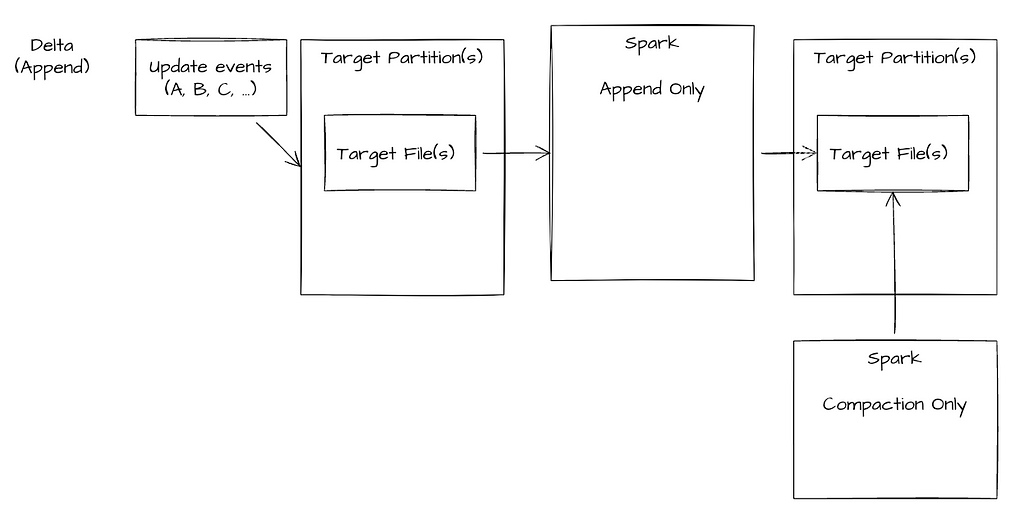
Ingestion Job — consists of 2 jobs an append only streaming job and a async cron scheduled compaction. This fails due to multiple writers touching the same files.
Reader much de-duplicate the records by reading duplicates and applying a window over the data.
Hudi WL2 Pattern
In our testing a Hudi MOR (Merge on Read) table with either synchronous or background compaction was the only open file format able to handle this pattern, ensuring the latest writes and a cleaned view were available for data consumers.
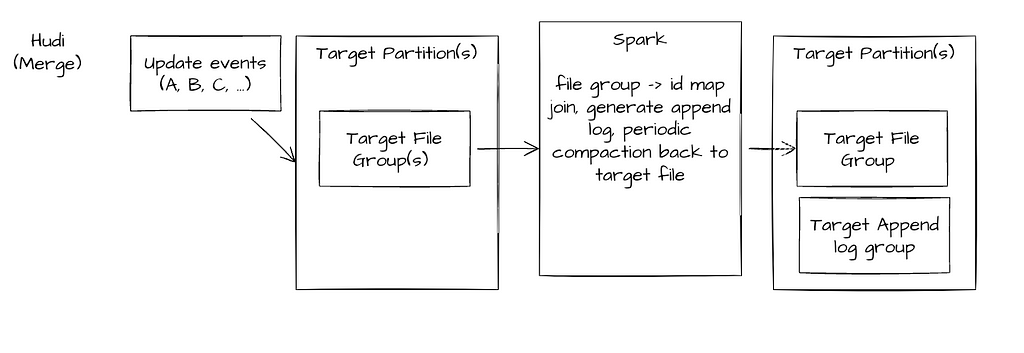
Ingestion Job — has row-key to file group map reducing complexity of join operations — — 150 cores (~15 minute batches / 50 minute compaction)
Reader — has choice of compacted (avoid change log view) Or slower performance realtime view. Periodic compact merges logs into respective file groups
Query performance
Common business query patterns were selected and dubbed them Q1-Q7 for workload 1 and Q1-Q10 for WL2. These patterns included:
· table count
· aggregate partition count
· count row key
· count row key predicated on partition
· needle in a haystack predicated on row key
· needle in a haystack predicated on row key and partition
· needle in a haystack predicated on dataset field
· needle in a haystack predicated on dataset field and partition
· 2-way table join on row keys
· 3-way table join on row keys
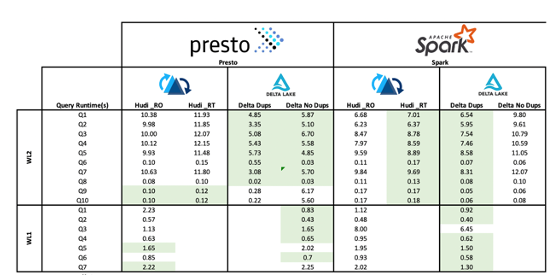 Query Benchmark Scores — Median Query times [min] across typical workloads
Query Benchmark Scores — Median Query times [min] across typical workloadsThough Delta provided the most optimal performance across most queries by around 40% there are exceptions in comparing the Delta view on top of the transactional real-time data compared with Hudi RT endpoint where Hudi was significantly faster in providing a deduped (latest record view) of the endpoint. A significant performance advantage for Delta was in the ZOrdering of records which will have created an advantage across most of the queries in the table able. Since the time of testing ZOrdering is now available in Hudi as well as improvements in filegroup metadata management. Together this will bring the benchmarks much closer.
In figures 3 and 4 are summaries of the query and ingestion performance across the three Lakehouse technologies that were tested. A critical footnote to consider is that Hudi provides significant performance optimizations though more complex configuration than Delta. At the time of our testing the “out-of-the-box” Delta default configuration is significantly more optimized and requires much less knowledge of the framework to be performant.
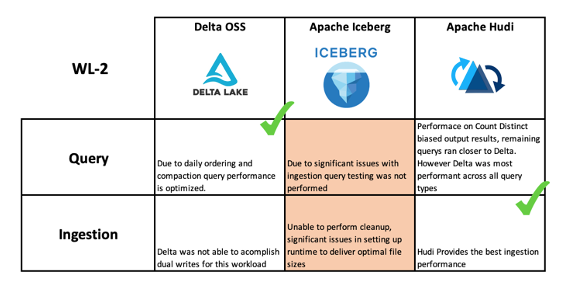 WL2 Query/Ingestion Performance summary
WL2 Query/Ingestion Performance summary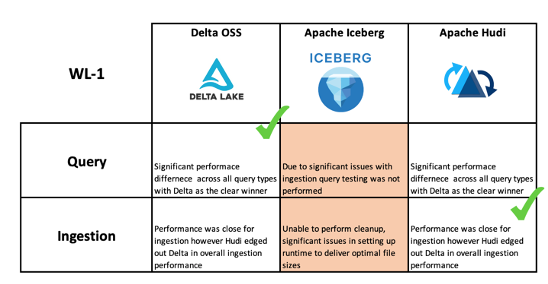 WL1 Query/Ingestion Performance summary
WL1 Query/Ingestion Performance summaryOverall
Winner: Apache Hudi
Based on Walmart’s investigation Apache Hudi has been selected to empower our next generation Lakehouse considering final scores from our weighted matrix across availability, compatibility, cost, performance, roadmap, support, and TCO. Additionally, it is noteworthy that our final decisions have been impacted dramatically by our highly diverse technology stack with over 600k+ cores of Hadoop and Spark across Walmart’s internal Cloud, Google and Azure. These workloads also run across a large distribution of Spark distributions and versions. Apache Hudi is the only 2.4.x Spark compatible version allowing us greater flexibility and adoption within our massive ecosystem.
Walmart has embarked on a major transformational shift having already started with the migration of some critical workloads. The journey isn’t complete, the domain is rapidly evolving, and Walmart will be constantly re-evaluating what is state of the art in this space, contributing towards these open source initiatives, pushing them to meet our complex business needs, and ensuring interoperability between new and legacy warehousing technologies.
Walmart platform teams leverage open-source technologies extensively hence our focus was to evaluate open-source Data Lake formats only. We did not focus majorly on enterprise offerings. With this in mind we’ve selected Apache Hudi to drive our Lakehouse pattern moving forward. Come help the world’s largest company in a transformational evolution supporting the creation one of the largest Lakehouse’s around, we’re hiring!!
NOTE: It is important to note that things in this domain are changing rapidly and some of the findings and results in this blog may be out of date by the time of publishing. We Benchmarked Leveraging Delta Core 1.0.0, Apache Iceberg 0.11.1, Apache Hudi 0.10.1
Co-Contributors:
- Toni LeTemp — Walmart Sr. Director
- Konstantin Shavachko — Walmart Distinguished Engineer
- Satya Narayana — Walmart Sr. Distinguished Technical Architect
Lakehouse at Fortune 1 Scale was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: Lakehouse at Fortune 1 Scale. Walmart systems produce very large and… | by Samuel Guleff | Walmart Global Tech Blog | Medium