Enterprises today rely on a wide range of cloud services—infrastructure as a service (IaaS), platform as a service (PaaS), software as a service (SaaS), and more—to meet their business needs. But the growing popularity of cloud has also led to an increase in attacks on cloud infrastructure, and thus the need for companies to develop strong security and incident response skills.
Before we dive into incident response in the cloud, however, it’s important to distinguish between the responsibility of the cloud service provider (CSP) and that of the cloud consumer. According to the “shared responsibility model,” the CSP is responsible for securing the cloud, while security in the cloud falls on the customer. This means it’s the client’s job to protect their workloads (including applications, systems, and code) running on the CSP’s platform.
With this responsibility placed on the customer, how they respond to an attack can have a significant impact on the mitigation of security breaches. But incidents in the cloud, such as those involving your EC2s, differ from those occurring on-premises (e.g., involving endpoints). This poses new challenges for incident response teams and requires different approaches.
In this blog, we cover the differences between cloud forensics and forensics in on-premises systems. We also take a look at the incident response process for a real attack that was spotted in the wild.
Incident Response: Cloud vs. Endpoint
The incident response process involves a skilled response or security team gathering the information needed in order to conduct a thorough investigation of the incident. But incident response in the cloud presents obstacles that don’t exist when investigating standard endpoints.
The main difference between cloud and on-premises systems is the degree of access and control a user has over resources. On-premises systems provide users full access to both hardware and software, while access in the cloud is limited depending on the type of service being used and the service provider.
Because cloud systems are distributed, the forensic evidence may be spread out across the globe, making it difficult to gather all of the information needed to investigate.
These factors need to be taken into consideration. The challenges of incident response in the cloud can be divided into six categories, each of which are covered below.
1. Collecting Forensic Evidence
When investigating incidents on endpoint or on-premises systems, the investigator has full access to all of the resources, including logs, memory dumps, hard drives, and more. But this isn’t the case in a cloud environment.
First, access to the forensics data depends on the cloud model. For instance, IaaS customers will have access to more data relative to SaaS customers.
For example, let’s assume attackers gained access to a messaging application (SaaS) used by company employees and stole sensitive data. In order to obtain the compromised/malicious account information (e.g., IP addresses and logs), the company would have to contact the messaging application and ask them to provide this information.
On the other hand, if attackers gained access to an EC2 (IaaS) instance, as long as you have basic logging and monitoring capabilities, you’d be able to access more information on your own, without the help of the CSP.
CSPs are not inclined to provide logs and data for fear of exposing sensitive information that could compromise them or their customers. In other cases, they may be reluctant to do so because they simply don’t know how to handle the event.
If customers of service models like PaaS and SaaS depend on their CSP for logs, they may not have access to important information needed in order to conduct a thorough investigation. On the other hand, customers using IaaS have greater control and the ability to set up different logs.
Customers should therefore configure logs and especially what to log. But logging everything isn’t the best solution, since this results in a huge amount of information that needs to be filtered, analyzed, and stored. Sifting through such large amounts of data during an investigation can be overwhelming and time-consuming.
While CSPs provide logging services, the more logs your system produces, the more expensive it will be. The cost will also depend on whether you’re using AWS, Azure, or GCP.
2. Data is Volatile or Not Saved
The incident response process is based on collecting information, including events that happened prior to the incident. CSPs provide clients with many tools that need to be configured according to your organization’s needs. This means the amount of data you can collect depends on what you choose to log and store, as well as the time period for which the data is stored.
In an IaaS like AWS, the data stored on the instances is lost after termination of the machine. As a result, important evidence is lost, including commands, scripts, processes, and files. Attackers can take advantage of this data loss to hide their malicious activity once they’ve completed their task.
3. No Physical Evidence
In the cloud, systems are distributed, and the physical components on which the data is stored may be in different geographic locations. This can make it nearly impossible to acquire the physical evidence or to perform physical forensics. Since each country has different laws, the process of seizing hardware involves collaboration between different governing legal authorities, which is a long and complicated process, with no guarantee the drives can be retrieved.
Without access to the physical drives, investigators need to ensure they’re using the appropriate forensics tools, since many rely on access to hardware. This has created a real need for new tools developed specifically for cloud forensics.
4. Chain of Custody and Privacy Laws
Due to the nature of cloud computing and the way data is stored, a single physical hard drive may contain the information of multiple customers. CSPs must notify clients that their data is protected and logically segmented from other tenants so they know other tenants can’t access their information—and vice versa. This makes collecting data from the hard drive complicated, and ultimately, only the CSP will be able to do so.
If evidence is presented in a court of law, the investigators must maintain the chain of custody of that evidence throughout the investigation. This becomes a major challenge due to multi-jurisdictional laws, further compounded when CSPs and other third-party companies join in the evidence collection process.
5. CSP Limitations
When an incident occurs, especially in SaaS and PaaS infrastructures, investigators must rely on the CSP to assist in the investigation. Another challenge is the dependency between CSPs and third parties. For example, a provider of email services may use a third-party platform to host its infrastructure.
In the event of an incident, the investigators would have to collaborate with all of the entities in this chain of dependencies, each with their own incident response approaches and methods. Once again, this complicates the incident response process.
6. Service-Level Agreement (SLA)
When it comes to SLAs, important terms related to forensics are often missing. This is due to both the failure of CSPs to provide full transparency in this regard as well as a lack of customer awareness on the matter. In the case of an incident, this creates an additional barrier for customers attempting to collect all the evidence needed for the investigation process.
Overcoming the Challenges of Incident Response in the Cloud
The incident response lifecycle can be broken down into four phases, as outlined by the National Institute of Standards and Technology (NIST). As visible from Figure 1, the process is cyclical, meaning it is an ongoing learning process whereby organizations can continue to improve their prevention and response methods.
 Figure 1: Cycle of incident response (Source: The National Institute of Standards and Technology)
Figure 1: Cycle of incident response (Source: The National Institute of Standards and Technology)
The challenges of incident response in the cloud are complex, and not all can be solved at once. However, there are actions that can be taken in the various stages of the process to help you better handle and investigate incidents.
Preparation Stage
Preparation is the most important stage. When your systems are well configured and your software is up to date, your response team will be prepared. This reduces incident handling time and even prevents attacks from happening in the first place.
1. Setting Logs
Logging events in the cloud is the key to proper incident handling. If your cloud provider offers logging options, you should use them. Just remember, logging everything isn’t ideal; instead, carefully choose which events and resources should be logged.
For example, in order to set notifications for suspicious activities such as unusual access to secrets in your company’s cloud account, you can configure CloudTrail to log these events. Each provider has its own set of recommendations, so be sure to follow the CIS benchmark best practices for the CSP you are using, whether AWS, Azure, or GCP.
2. Rules and Permissions
Set permissions and rules for each user and group based on the principle of least privilege policy, where a user is given the minimum level of access and permissions they need to do their job.
For example, each development team should only have access to the repositories and servers relevant to their specific departments, and developers should have permissions to add new code only to projects they are currently working on. But members of the finance department—or any other department that doesn’t require it—shouldn’t have access to any of these resources.
3. Zero Trust
Use the zero trust approach when configuring your network. Based on this concept, no device is trusted until its integrity and identity are verified.
There are many ways to apply this model:
- Implement a network and logical segmentation on the VPC in AWS, Azure Virtual Network (VNet), or GCP.
- For access control:
- Identify all of the company’s employees and configure roles for each of them.
- Manage company devices (e.g., laptops) and verify their integrity using MDM solutions such as JumpCloud.
- Map permissions for each asset to each role in the company.
- Map the application employees need to use and implement SSO authentication.
- Implement two-factor authentication (2FA).
4. Notifications
Add alarms and notifications for specific events, but try to minimize false positive alerts.
There are two types of alerts; those that are triggered by a user’s actions and those that come from system and metrics events. It’s important to configure both types, but the configuration of events that will trigger alerts also depends on your company’s organizational behavior. Examples include:
- User alerts: If all of your company employees use the same VPN configuration, setting a geolocation login alert will notify you of any suspicious login attempts that do not originate from your VPN.
- System alerts: If your cloud infrastructure doesn’t typically require high CPU and memory usage, setting an alert for high usage will allow you to address any anomalies in the system.
5. Prepare in Advance for Different Types of Attacks
Make sure you’re ready for whatever type of attack comes your way:
- Backup and recovery: Develop a recovery plan and maintain up-to-date backups of your organization’s most valuable data. Using cloud backups, which employs versioning to make copies of all your files, will ensure continuous backup and make it easier to restore data after any attacks.
- Playbooks: Prepare a playbook of routines and the actions for different incident scenarios.
- Recovery drills: Prepare a recovery drill to test your backups so you’re fully prepared to use them when they are most needed.
These preparations can help with many different incidents, such as DDoS attacks that prevent customers from accessing your system, or ransomware attacks that encrypt all the files in your environment. Following the principles of chaos engineering, you can use automated tools like Chaos Monkey to test your system’s resilience.
Last, define the impacts and prioritize risks for every component in your environment, so you know where to put your best efforts during an incident.
6. Know Your Runtime
Knowing what code is being executed in your environment makes it easy to detect any unauthorized code that could be part of an attack. A cloud workload protection platform (CWPP) that monitors your runtime and alerts you on the execution of code that deviates from your known code baseline will help you identify and stop attacks in their earliest stages.
Intezer Protect provides full runtime visibility for conducting forensics on containerized environments and standalone VMs. It also provides quick and easy malware scans built for modern production systems, with no impact on performance. Intezer has integrations with SOAR, SIEM, and Slack.
7. Fix Misconfigurations
Cloud infrastructure can be complex, with many components and services that need to be configured. This increases your opportunity for error. Scanning your cloud environment for misconfigurations is important, because attackers are scanning as well. And if they find it before you do, the consequences can be catastrophic.
There are many cloud security posture management (CSPM) tools that can be used for misconfiguration scanning. A few examples include:
- GCP’s Security Command Center (SCC).
- CloudSploit, an open-source project that finds security misconfigurations in cloud infrastructures.
- OpenCSPM, an open-source project that provides visibility over the configuration of the cloud infrastructure.
- Intezer Protect, which finds misconfigurations inside your Linux workloads.
8. Patch Vulnerabilities and Install System Updates
Keeping all the components of your cloud environment updated and patched can prevent attacks from happening in the first place.
There are several open-source projects, such as Vuls, OpenVAS, and Xray, that can be used for vulnerability scanning. Finally, with Intezer Protect, you gain visibility over vulnerable packages installed on your workload.
Detection and Analysis
So if you’ve done everything you can to reduce the likelihood of an attack, where do you start when one happens?
First, collect all of the information that indicates that an incident is occurring in the system, including logs, IP addresses, affected accounts, virtual images of the victim hosts, commands and scripts that are being executed, and so on.
Next, analyze the evidence to better understand the incident and how you should respond to it.
For example, let’s assume you got an alert on the creation of several new AWS instances. The first thing to check is the CloudTrial logs, where you’ll find RunInstances events as shown in Figure 2 below.
Figure 2: AWS CloudTrail logs showing RunInstances events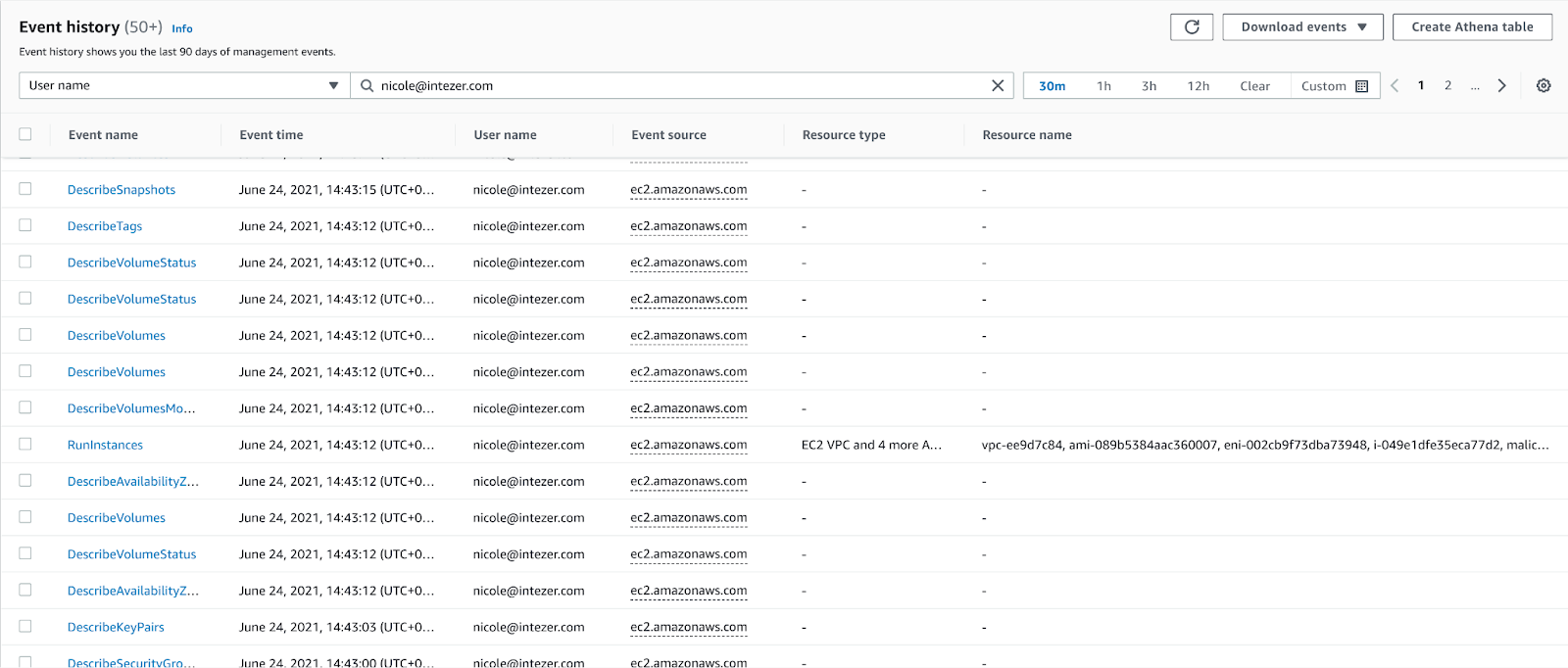
After you isolate the instances and connect securely (not from your personal computer), you find a suspicious file in the /tmp/kdevtmpfsi directory. After extracting the file from the machine either you or the threat analysis team will analyze the file and the events that led to the execution of the malware in an attempt to understand the threat and the damage to the environment. This process may take a long time especially for sophisticated threats.
Intezer Protect provides full runtime visibility and detection over the commands and executions in the environment (see figure 3 below), so in cases like the previous example, an alert is triggered as soon as the cryptominer is executed, and the user can view the events that occurred prior to the malware execution.
Figure 3: Screenshot of the alert on execution of a cryptominer in Intezer Protect
Containment, Eradication, and Recovery
The next stage in the process involves:
- Identifying and isolating the hosts or containers that were attacked to prevent the attack from spreading in the network.
- Making a snapshot/copy of the instance and the volume that was attacked to preserve the evidence. Preserving the evidence is important for investigation of the incident. It will help you learn how the attackers got into the system, find compromised hosts, and understand the attack flow.
Post Incident
Once the incident is over:
- Complete an incident response report and share it with relevant stakeholders in the organization so they can read and understand it. It’s important to document the investigation and findings to prevent similar events in the future, improve the incident response process, and to fix and add security measures.
- Learn the kill chain of the attack based on the evidence you gathered, and monitor your systems for post-incident activity.
- If the incident was caused by misconfigurations or vulnerabilities, make sure to patch and fix them.
Getting Started
Developing a reliable incident response process in cloud environments is a complicated and challenging task, with many factors that need to be taken into account.
Even with the precautions detailed in this blog, breaches still happen—whether due to unknown vulnerabilities/misconfigurations, unauthorized access, or supply chain attacks. Having strong runtime threat detection and response capabilities is crucial.
Intezer Protect automates the digital forensics and incident response (DFIR) process and gives you full visibility of your runtime environment. It also detects advanced in-memory threats, including fileless malware such as the Ezuri packer, terminating them immediately. Intezer Protect gives you the information needed to investigate the incident, including the full process tree, an event log for each asset, and details about containers and images that were used in the environment.
Automate your DFIR process to close incidents fast while maintaining a state of running only trusted code. Try Intezer Protect for K8s, containers, and VMs, and get started with 10 free hosts, nodes, or machines.
Special thanks to Aner Izraeli for contributing to this post.
The post Guide to Digital Forensics Incident Response in the Cloud appeared first on Intezer.
Article Link: https://www.intezer.com/blog/cloud-security/guide-to-digital-forensics-incident-response-in-the-cloud/