DataBathing — A Framework for Transferring the Query to Spark Code
A mini-guide about Query-Config Driven Coding
 Photo credit: Pixabay
Photo credit: PixabayOur team has successfully transformed from Hive SQL driven to code driven for data engineering. We are using Spark (Scala or Python) every day, and our calculation performance has increased significantly. (We have reduced our average running time by 10–80%.)
However, coding will take more time, and different developers will have different versions of the coding style, impacting the spark job performance.
Then how can we solve the above issues? Can we have some standardized ways to utilize SQL for a complex pipeline? — I will explain why we don’t want to use Spark SQL directly in the following blog.
Yes, this is why DataBathing is coming !!!
Agenda
- DataBathing is coming
- Spark Dataframe versus Spark SQL
- HERO: mo_sql_parsing
- Small demo
- Currently supported features
- Next roadmap
- Contribution
- Thanks
- Summary
DataBathing is coming
DataBathing is a library that can transfer the SQL to Spark Dataframe calculation flow code. We can find the high-level example in Figure 1. DataBathing can parse the SQL query, and the output will be PySpark or Scala Spark code.
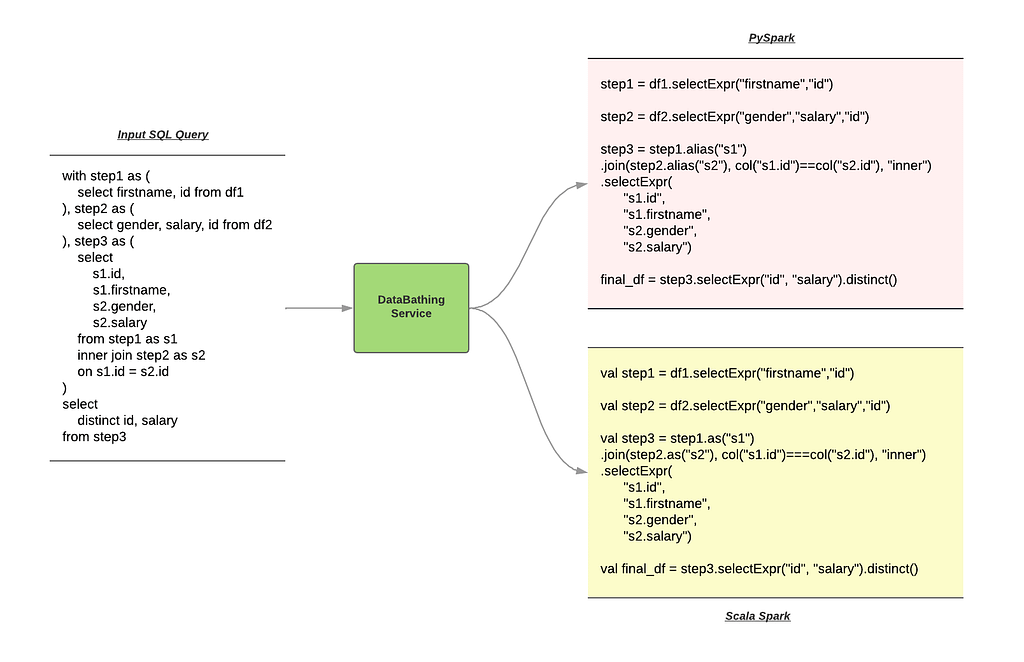 Figure 1 — What DataBathing can do !!!
Figure 1 — What DataBathing can do !!!In Figure 1, we save the logic as a Dataframe for future usage in each stage of the data lineage. We will discuss the reason for this design in the following section. In short, we are using “with statement” to link the logic in our pipeline.
In Phase I, we use DataBathing to extract the SQL’s logic and data lineage. Typically, after using the “with statement” to create the logic, we can easily copy and paste the Dataframe calculation into our actual pipeline. Figure 2 shows the flow.
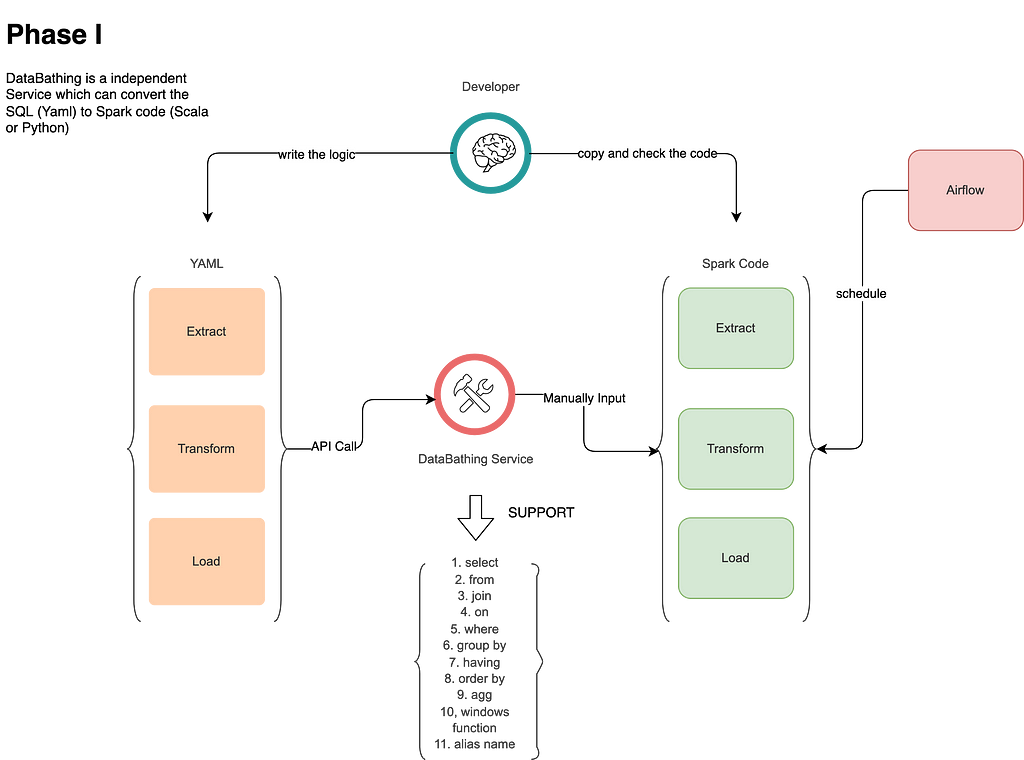 Figure 2 — Phase I for DataBathing Usage
Figure 2 — Phase I for DataBathing UsageSpark Dataframe versus Spark SQL
If you’ve used Spark before, you may be wondering why we need to convert SQL to Spark Dataframe calculation. I’ll explain.
Tech concerns
- We won’t know the syntax error until runtime - especially for the Scala part - when using Spark SQL. It will be a massive cost for development. However, we don’t have this issue for the Dataframe calculation flow, because the error will be caught at compile time.
- If we put a large SQL query into our Spark SQL running task and the query is inefficient, that will be a problem for the ETL job. On the other hand, compact Spark Dataframe calculation can improve performance and provide clear data lineage. This is one of the benefits that we get from DataBathing: splitting complex logic into smaller pieces.
Next step plan
DataBathing is not only a library that can help developers parsing the SQL into Spark Dataframe calculation flow; it is also a crucial foundation for our next generation Auto-Generated Pipeline Framework usage.
Auto-Generated Pipeline Framework: In short, after using this framework, you don’t need to write the spark code; it can help us generate the pipeline based on logic itself with the framework. (I will explain in a future blog.)
In Phase II of DataBathing, all SQL queries are parsed and concatenated in one pipeline; if we want to utilize some middleware logic, the framework can help us. Using DataBathing’s “with statement” design, we can reach our goal easily. In Figure 3, our next generation Auto-Generated Pipeline internally and sequentially calls our DataBathing service to get the Spark Dataframe calculation flows and combine them. We will detail this usage in the next blog.
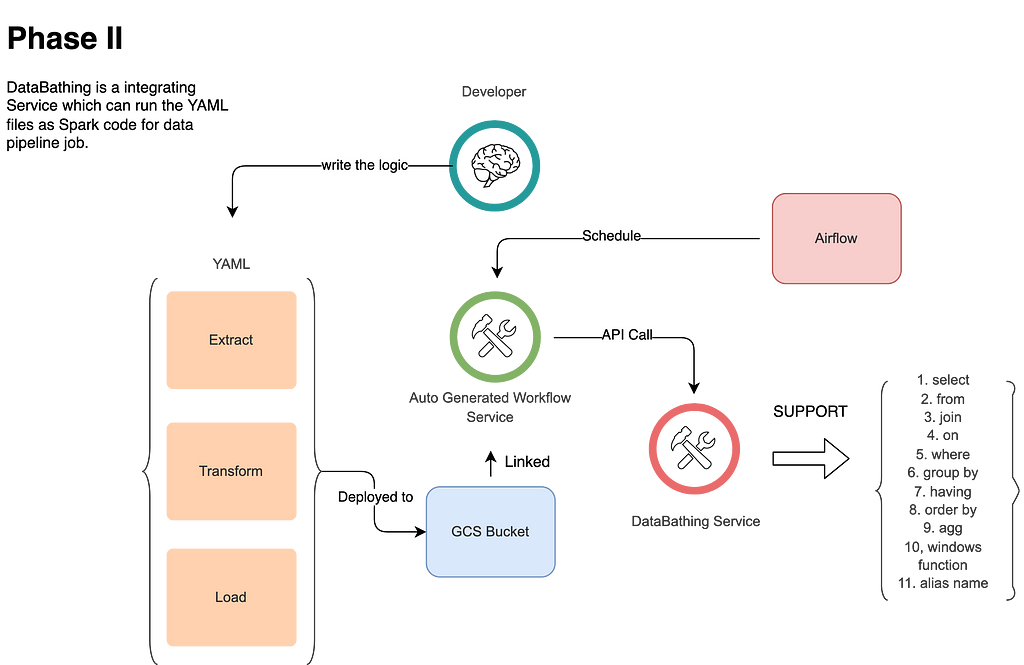 Figure 3— Phase II for DataBathing Usage
Figure 3— Phase II for DataBathing UsageHERO: mo_sql_parsing
How do you parse the SQL into a structural format? With mo_sql_parsing!
mo_sql_parsing is a library to parse SQL into JSON.
Please reference the example and Github link below:
>>> parse("select a as hello, b as world from jobs")
{'select': [{'value': 'a', 'name': 'hello'}, {'value': 'b', 'name': 'world'}], 'from': 'jobs'}
Small demo
You can also generate PySpark code from the given SQL query. Please install the DataBathing package from PyPI.
pip install databathing
>>> from databathing import Pipeline
>>> pipeline = Pipeline("SELECT * FROM Test WHERE info = 1")
'final_df = Test\\\n.filter("info = 1")\\\n.selectExpr("a","b","c")\n\n'
Currently supported features
Features and Functionalities — PySpark Version
- SELECT feature
- FROM feature
- INNER JOIN and LEFT JOIN features
- ON feature
- WHERE feature
- GROUP BY feature
- HAVING feature
- ORDER BY feature
- AGG feature
- WINDOWS FUNCTION feature (SUM, AVG, MAX, MIN, MEAN, COUNT, COLLECT_LIST, COLLECT_SET)
- ALIAS NAME feature
- WITH STATEMENT feature
- SPLIT feature
Next roadmap
In the next roadmap, I will focus on:
- More test cases
- Scala version for the 12 features in PySpark
- More JOIN features like OUTER, FULL, FULLOUTER, LEFTSEMI, LEFTANTI
Contribution
If you need more features from DataBathing, you can raise an issue and show the error, or you can create a PR with new features and tests. If you also submit a fix, then you have my gratitude.
Please follow these instructions to update the version when raising the PR, because we are using cicleci for the CICD process:
You can find DataBathing on the GitHub homepage:
GitHub - jason-jz-zhu/databathing
Thanks
When I started designing and implementing DataBathing, I found this article helpful. I want to thank the author, even though I don’t know who they are.
Online SQL to PySpark Converter
Summary
- We can use DataBathing to reduce our development time using SQL style “with statement” with compact and clear code.
- In the meantime, we can use it to enjoy the calculation of the performance of Spark.
- Most importantly, it will be a huge difference when combined with the Auto-Generated Pipeline Framework.
- See you in the next Auto-Generated Pipeline Framework blog!
DataBathing — A Framework for Transferring the Query to Spark Code was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Article Link: DataBathing — A Framework for Transferring the Query to Spark Code | by Jiazhen Zhu | Walmart Global Tech Blog | Medium