It’s very tempting and, honestly, I’m doing it from time to time… I search for pictures on the Internet and use them in my documents! Why it could be dangerous in some cases? Let’s put aside copyright issues (yes, some pictures might not be free of use) but focus on the risk of linking pictures into your presentations, reports, …
I just faced an interesting case. A Word document passed through a set of security controls and was put in quarantine due to “suspicious HTTP activity” once opened. When you read this, you immediately think about a VBA macro that is trying to download some payload from the Wild internet, right? After the first suite of classic tests, the document did not appear to be malicious:
- No “executable” code in the file (VBA, exploit, …)
- The document meta-data were correct (names, organisation) (Ok, ok, it can be easily changed if the attacker is clever)
- The document was delivered through an email and was sent from the pretended user (from his network, his servers, etc…)
Was it a BEC attack maybe? No Sir, it was not. Contact was taken with the recipient, he confirmed to be in contact with the sender and also requested the document to be released from the quarantine. So, what’s next?
The malicious document contained a header with logos and one of them was linked to a URL. The URL was pointing to a WordPress site. Ok, we found the guilty! Probably an exploit will be delivered with the help of a vulnerable WordPress plugin. Not possible to verify this scenario because the website replied to all requests with an HTTP/301 reply (redirect). The traffic was redirected to another site about football and another redirect landed to a Turkish online betting service. This last page had many pieces of JavaScript but, after checking them, none was malicious. Note that the first website was hosted on a domain registered more than two years ago, once again, not suspicious.
After contacting the sender of the initial email, it was more clear. The document was created based on an old template. The author searched the web for a “nice” logo to add in the header and found one, probably via a search engine. This image was added as an object into the document and every time it is opened, an HTTP request is performed by Word against the URL. In this case, it followed the multiple HTTP redirect and hit the JavaScript code and was flagged as malicious…
How this works? Let’s check the following Word document:
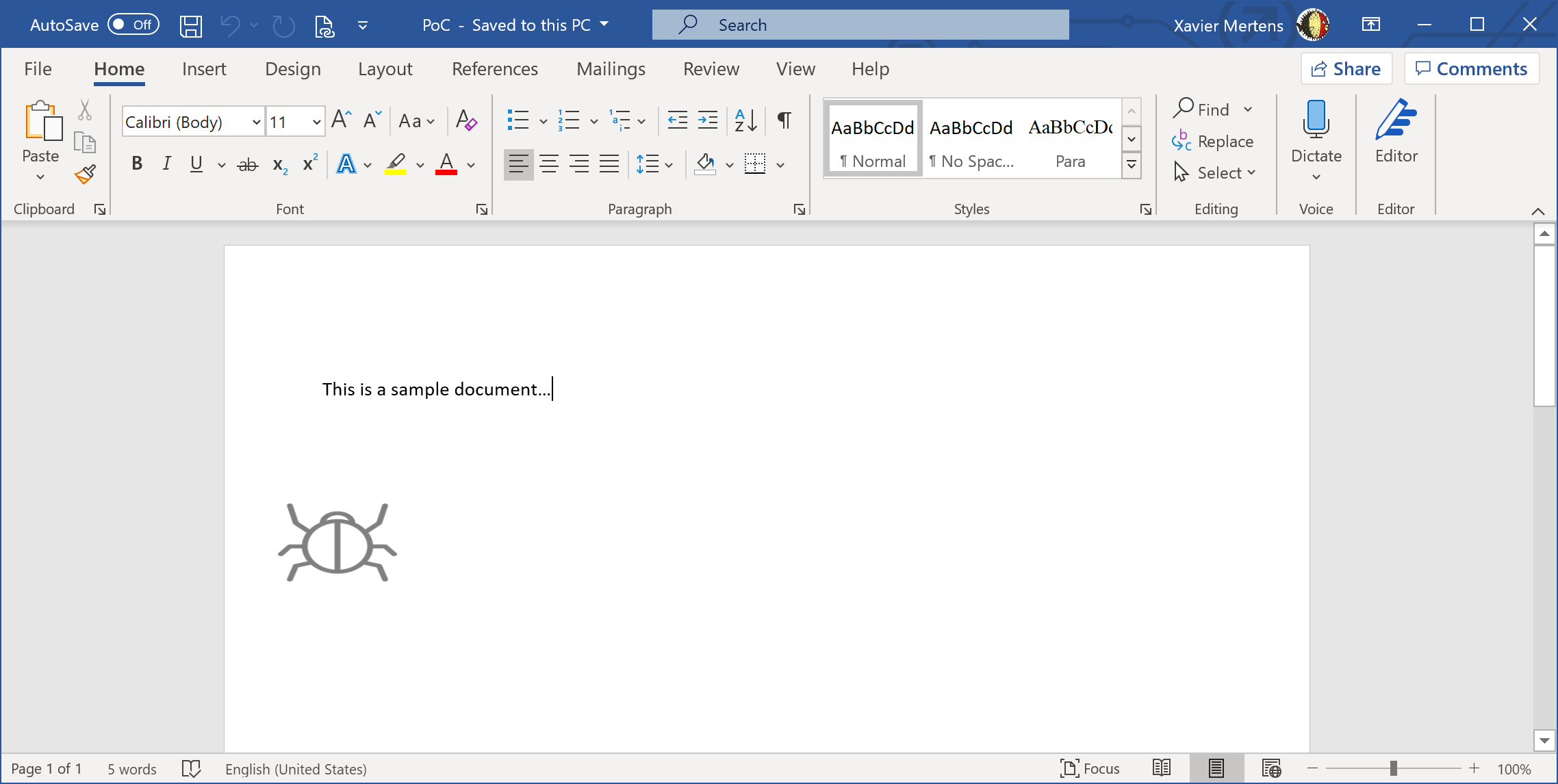 (Click to enlarge)
(Click to enlarge)
The small bug is a picture grabbed from a site and added as an object in the document. You can see/edit links in a Word document via the “Edit Links” feature:
 (click to enlarge)
(click to enlarge)
The link to the picture could have been found by using any search engine. Note also that the automatic update of the picture is disabled.
Even if disabled, Word will generate some HTTP requests every time the document is opened:
x.x.x.x - - [21/Jan/2021:15:23:09 +0100] "OPTIONS /images/bug.png/ HTTP/1.1" 200 3600 "-" "Microsoft Office Word 2014"
x.x.x.x - - [21/Jan/2021:15:23:09 +0100] "OPTIONS /images/bug.png/ HTTP/1.1" 200 3600 "-" "Microsoft Office Word 2014"
x.x.x.x - - [21/Jan/2021:15:23:10 +0100] "OPTIONS /images/bug.png/ HTTP/1.1" 200 308 "-" "Microsoft Office Word"
x.x.x.x - - [21/Jan/2021:15:23:10 +0100] "OPTIONS /images/bug.png/ HTTP/1.1" 200 3600 "-" "Microsoft Office Protocol Discovery"
x.x.x.x - - [21/Jan/2021:15:23:10 +0100] "HEAD /images/bug.png HTTP/1.1" 200 378 "-" "Microsoft Office Word 2014"
x.x.x.x - - [21/Jan/2021:15:23:10 +0100] "OPTIONS /images/bug.png/ HTTP/1.1" 200 308 "-" "Microsoft Office Word 2014"
x.x.x.x - - [21/Jan/2021:15:23:10 +0100] "HEAD /images/bug.png HTTP/1.1" 200 378 "-" "Microsoft Office Word 2014"
x.x.x.x - - [21/Jan/2021:15:23:10 +0100] "HEAD /images/bug.png HTTP/1.1" 200 378 "-" "Microsoft Office Existence Discovery"
x.x.x.x - - [21/Jan/2021:15:23:20 +0100] "GET /images/bug.png HTTP/1.1" 200 14625 "-" "Mozilla/4.0 (compatible; ms-office; MSOffice 16)"
Why is this technique dangerous? Here are some attack scenarios.
First, it’s possible to change the ranking of a website (and its pictures) in search engines using SEO techniques. If you know that your victim is looking for very specific pictures, you can expect that the search engine will propose your pictures first.
If an attacker has access to a document containing the URL. It can target the site hosting the picture, compromise it and replace the original picture with another one. This is even more dangerous if the auto-updated is enabled in the document.
If the attacker has access to the server hosting the picture, it can also track who opens the document and collect public IP addresses, User-Agents (revealing the Word version as you can see above).
If the website hosting the picture you linked because flagged as suspicious, your document might be flagged as suspicious (like the case I explained above).
My recommendation is to NOT link pictures directly in your Word documents. Search for pictures with your favorite search engine, download them on your file system and add them manually into documents. The key point is to avoid Word to perform HTTP requests on its own! This is a common hunting rule implemented by many SOCs: To try to spot HTTP traffic not originating from a classic browser.
The post Be Careful When Using Images Grabbed Online In Your Documents appeared first on /dev/random.
Article Link: https://blog.rootshell.be/2021/01/22/be-careful-when-using-images-grabbed-online-in-your-documents/